准确率(accuracy),精确率(Precision),召回率(Recall)和综合评价指标(F1-Measure )----转
| 正确的、相关的(wanted) | 不正确的、不相关的 | ||||
|
|
|
|||
|
|
|

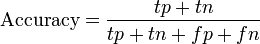
然而在实际当中我们当然希望检索的结果P越高越好,R也越高越好;事实上这两者在某些情况下是矛盾的。比如,我们只搜出了一个结果,且是准确的,那么P就是100%,但是R就很低;而如果我们把所有结果都返回,那么必然R是100%,但是P很低。因此在不同的场合中需要自己判断希望P比较高还是R比较高。如果是做实验,可以绘制Precision-Recall曲线来帮助分析。
F-Measure是Precision和Recall加权调和平均:
当参数a=1时,就是最常见的F1了:
很容易理解,F1综合了P和R的结果,当F1较高时则比较说明实验方法比较理想。
二、
自然语言处理(ML),机器学习(NLP),信息检索(IR)等领域,评估(evaluation)是一个必要的工作,而其评价指标往往有如下几点:准确率(accuracy),精确率(Precision),召回率(Recall)和F1-Measure。
本文将简单介绍其中几个概念。中文中这几个评价指标翻译各有不同,所以一般情况下推荐使用英文。
现在我先假定一个具体场景作为例子:
假如某个班级有男生80人,女生20人,共计100人.目标是找出所有女生.
现在某人挑选出50个人,其中20人是女生,另外还错误的把30个男生也当作女生挑选出来了.
作为评估者的你需要来评估(evaluation)下他的工作
将挑选结果用 矩阵示意表来表示 : 定义TP,FN,FP,TN四种分类情况
| 相关(Relevant),正类 | 无关(NonRelevant),负类 | |
| 被检索到(Retrieved) | TP 系统检索到的相关文档,例"其中20人是女生" | FP 系统检索到的不相关文档,例”错误把30个男生当女生“ |
| 未被检索到(Not Retrieved) | FN 相关系统未检索到的文档,例"未挑0人是女生" | TN 相关但是系统没有检索到的文档,例”未挑50人非女生“ |
准确率(accuracy)的公式是,其定义是: 对于给定的测试数据集,分类器正确分类的样本数与总样本数之比。也就是损失函数是0-1损失时测试数据集上的准确率
A = (20+50) / 100 = 70%
精确率(precision)的公式是,它计算的是所有被检索到的item中,"应该被检索到"的item占的比例。
P = 20 / (20+30) = 40%
召回率(recall)的公式是,它计算的是所有检索到的item占所有"应该检索到的item"的比例。
R = 20 / (20 + 0) = 100%
综合评价指标(F-Measure)是Precision和Recall加权调和平均:
当参数a=1时,就是最常见的F1了:
P和R指标有的时候是矛盾的,综合考虑精确率(precision)和召回率(recall)这两个度量值。很容易理解,F1综合了P和R的结果,当F1较高时则比较说明实验方法比较理想。
F1 = 2*0.4*1 / (0.4 + 1) = 57%
准确率(accuracy),精确率(Precision),召回率(Recall)和综合评价指标(F1-Measure )----转的更多相关文章
- 准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure
yu Code 15 Comments 机器学习(ML),自然语言处理(NLP),信息检索(IR)等领域,评估(Evaluation)是一个必要的 工作,而其评价指标往往有如下几点:准确率(Accu ...
- 准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure(对于二分类问题)
首先我们可以计算准确率(accuracy),其定义是: 对于给定的测试数据集,分类器正确分类的样本数与总样本数之比.也就是损失函数是0-1损失时测试数据集上的准确率. 下面在介绍时使用一下例子: 一个 ...
- 精确率与召回率,RoC曲线与PR曲线
在机器学习的算法评估中,尤其是分类算法评估中,我们经常听到精确率(precision)与召回率(recall),RoC曲线与PR曲线这些概念,那这些概念到底有什么用处呢? 首先,我们需要搞清楚几个拗口 ...
- 目标检测评价指标mAP 精准率和召回率
首先明确几个概念,精确率,召回率,准确率 精确率precision 召回率recall 准确率accuracy 以一个实际例子入手,假设我们有100个肿瘤病人. 95个良性肿瘤病人,5个恶性肿瘤病人. ...
- 准确率、精确率、召回率、F1
在搭建一个AI模型或者是机器学习模型的时候怎么去评估模型,比如我们前期讲的利用朴素贝叶斯算法做的垃圾邮件分类算法,我们如何取评估它.我们需要一套完整的评估方法对我们的模型进行正确的评估,如果模型效果比 ...
- 机器学习性能指标精确率、召回率、F1值、ROC、PRC与AUC--周振洋
机器学习性能指标精确率.召回率.F1值.ROC.PRC与AUC 精确率.召回率.F1.AUC和ROC曲线都是评价模型好坏的指标,那么它们之间有什么不同,又有什么联系呢.下面让我们分别来看一下这几个指标 ...
- 一文让你彻底理解准确率,精准率,召回率,真正率,假正率,ROC/AUC
参考资料:https://zhuanlan.zhihu.com/p/46714763 ROC/AUC作为机器学习的评估指标非常重要,也是面试中经常出现的问题(80%都会问到).其实,理解它并不是非常难 ...
- 二分类算法的评价指标:准确率、精准率、召回率、混淆矩阵、AUC
评价指标是针对同样的数据,输入不同的算法,或者输入相同的算法但参数不同而给出这个算法或者参数好坏的定量指标. 以下为了方便讲解,都以二分类问题为前提进行介绍,其实多分类问题下这些概念都可以得到推广. ...
- 目标检测评价标准(mAP, 精准度(Precision), 召回率(Recall), 准确率(Accuracy),交除并(IoU))
1. TP , FP , TN , FN定义 TP(True Positive)是正样本预测为正样本的数量,即与Ground truth区域的IoU>=threshold的预测框 FP(Fals ...
- 准确率(Precision),召回率(Recall)以及综合评价指标(F1-Measure)
准确率和召回率是数据挖掘中预测,互联网中得搜索引擎等经常涉及的两个概念和指标. 准确率:又称“精度”,“正确率” 召回率:又称“查全率” 以检索为例,可以把搜索情况用下图表示: 相关 不相关 检索 ...
随机推荐
- Windows 下的内存泄漏检测方法
在 Windows 下,可使用 Visual C++ 的 C Runtime Library(CRT) 检测内存泄漏. 首先,我们在.c或.cpp 文件首行插入这一段代码: #define _CRTD ...
- GO语言 切片的缩短和增长原理
package main import "fmt" //import OS "os" //import "strings" //import ...
- codeforces 453C Little Pony and Summer Sun Celebration
codeforces 453C Little Pony and Summer Sun Celebration 这道题很有意思,虽然网上题解很多了,但是我还是想存档一下我的理解. 题意可以这样转换:初始 ...
- keepalived安装文档
安装依赖 su - root yum -y install kernel-devel* yum -y install openssl-* yum -y install popt-devel yum ...
- 对Java中的异常的理解
1.What is exception in Java? Java使用异常描述程序中可能出现的不正常情况.这个不正常可以是java认为的不正常,也可以是你主观上的出乎意料(自定义异常).总而言之,异常 ...
- angularJs的run方法操作
省掉了控制器 <!DOCTYPE HTML> <html ng-app="myApp"> <head> <meta http-equiv= ...
- BZOJ 1013 球形空间产生器sphere 高斯消元
题目链接: https://www.lydsy.com/JudgeOnline/problem.php?id=1013 题目大意: 有一个球形空间产生器能够在n维空间中产生一个坚硬的球体.现在,你被困 ...
- docker-7-常用软件的安装
1.总体步骤 搜索镜像 拉取镜像 查看镜像 启动镜像 停止容器 移除容器 2.安装tomcat docker hub上面查找tomcat镜像:docker search tomcat 从doc ...
- Asp.Net Core + Ocelot 网关搭建:路由简单配置
前言 Ocelot是一个基于中间件的网关实现,功能有很多.从浅入深简单学习并记录一下吧.本篇就是一个简单的路由配置实现. DEMO 搭建 首先建立三个项目.Api.User,Api.Artic ...
- java把行政区划放到一个节点树形中
作者原创:转载请注明出处.https://www.cnblogs.com/yunqing/p/9486923.html 先放数据,t_city表 //津京冀地区行政区划数据 SET FOREIGN_K ...