核密度估计 Kernel Density Estimation (KDE) MATLAB
对于已经得到的样本集,核密度估计是一种可以求得样本的分布的概率密度函数的方法:
通过选取核函数和合适的带宽,可以得到样本的distribution probability,在这里核函数选取标准正态分布函数,bandwidth通过AMISE规则选取
具体原理及定义:传送门 https://en.wikipedia.org/wiki/Density_estimation
MATLAB 代码实现如下:
% Kernel Density Estimation
% 只能处理正半轴密度
function [t, y_true, tt, y_KDE] = KernelDensityEstimation(x)
% clear % x = px_last;
% x = px_last_tu;
%%
%参数初始化
Max = round(max(x)); %数据中最大值
Min = round(min(x)); %数据中最小值
Ntotal = length(x); %数据个数
tt = : 0.1 : Max; %精确x轴
t = : Max; %粗略x轴 y_KDE = zeros( * Max+, ); %核密度估计值
sum1 = ; %求和的中间变量
%%
%计算带宽h
R = /(*sqrt(pi));
m2 = ;
h = ;
% h = (R)^(/) / (m2^(/) * R^(/) * Ntotal^(/)); %%
%计算核密度估计
for i = : 0.1 : Max
for j = : Ntotal
sum1 = sum1 + normpdf(i-x(j));
end
y_KDE(round(i*+)) = sum1 / (h * Ntotal);
sum1 = ;
end sum2 = sum(y_KDE)*0.1; %归一化KDE密度
for i = : 0.1 : Max
y_KDE(round(i*+)) = y_KDE(round(i*+))/sum2;
end %%
%计算真实密度的分布
y_true = zeros(Max+,);
for i = : Max
for j = : Ntotal
if (x(j) < i+)&&(x(j) >= i)
y_true(i+) = y_true(i+) + ;
end
end
y_true(i+) = y_true(i+) / Ntotal;
end %%
%绘图 % figure() %真实密度的分布图象
% bar(t, y_true);
% axis([Min Max+ max(y_true)*1.1]);
%
% figure() %核密度估计的密度分布图象
% plot(tt, y_KDE);
% axis([Min Max max(y_true)*1.1]);
给定测试数据:
data = [1,2,3,4,5,2,1,2,4,2,1,4,7,4,1,2,4,9,8,7,10,1,2,3,1,0,0,3,6,7,8,9,4]
样本的条形统计图和KDE密度分布图分别如下,可以看到KDE可以较好的还原样本的分布情况:
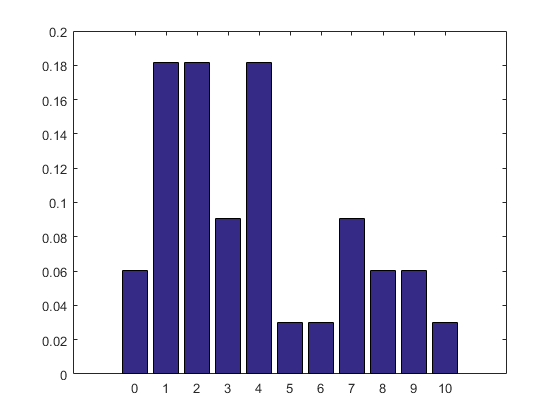
真实概率分布图
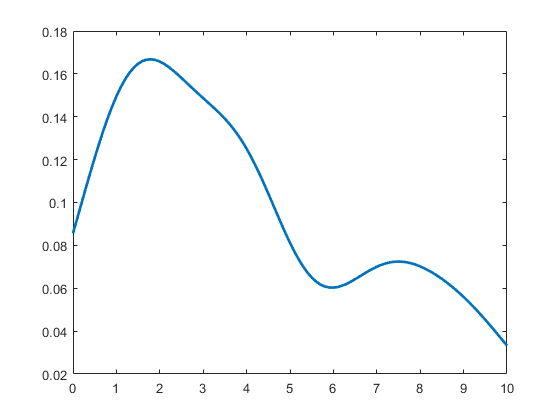
KDE密度分布图
核密度估计 Kernel Density Estimation (KDE) MATLAB的更多相关文章
- 非参数估计:核密度估计KDE
http://blog.csdn.net/pipisorry/article/details/53635895 核密度估计Kernel Density Estimation(KDE)概述 密度估计的问 ...
- kdeplot(核密度估计图) & distplot
Seaborn是基于matplotlib的Python可视化库. 它提供了一个高级界面来绘制有吸引力的统计图形.Seaborn其实是在matplotlib的基础上进行了更高级的API封装,从而使得作图 ...
- 【转】用深度学习做crowd density estimation
本博文主要是CVPR2016的<Single-Image Crowd Counting via Multi-Column Convolutional Neural Network>这篇文章 ...
- R语言与非参数统计(核密度估计)
R语言与非参数统计(核密度估计) 核密度估计是在概率论中用来估计未知的密度函数,属于非参数检验方法之一,由Rosenblatt (1955)和Emanuel Parzen(1962)提出,又名Parz ...
- More 3D Graphics (rgl) for Classification with Local Logistic Regression and Kernel Density Estimates (from The Elements of Statistical Learning)(转)
This post builds on a previous post, but can be read and understood independently. As part of my cou ...
- 泡泡一分钟:Geometric and Physical Constraints for Drone-Based Head Plane Crowd Density Estimation
张宁 Geometric and Physical Constraints for Drone-Based Head Plane Crowd Density Estimation 基于无人机的向下平面 ...
- <轻量算法>根据核密度估计检测波峰算法 ---基于有限状态自动机和递归实现
原创博客,转载请联系博主! 希望我思考问题的思路,也可以给大家一些启发或者反思! 问题背景: 现在我们的手上有一组没有明确规律,但是分布有明显聚簇现象的样本点,如下图所示: 图中数据集是显然是个3维的 ...
- 非参数估计——核密度估计(Parzen窗)
核密度估计,或Parzen窗,是非参数估计概率密度的一种.比如机器学习中还有K近邻法也是非参估计的一种,不过K近邻通常是用来判别样本类别的,就是把样本空间每个点划分为与其最接近的K个训练抽样中,占比最 ...
- Windows内核开发-6-内核机制 Kernel Mechanisms
Windows内核开发-6-内核机制 Kernel Mechanisms 一部分Windows的内核机制对于驱动开发很有帮助,还有一部分对于内核理解和调试也很有帮助. Interrupt Reques ...
随机推荐
- database design three form
https://www.cnblogs.com/linjiqin/archive/2012/04/01/2428695.html
- matlab中的knn函数
knn 最邻近分类 Class = knnclassify(test_data,train_data,train_label, k, distance, rule) k:选择最邻近的数量 distan ...
- unity3d项目版本管理设置
unity3d老是有一堆乱七八糟的文件,好像不提交也不行,特别是那烦人的meta文件,哪到底unity项目提交到版本管理哪些东西可以忽略呢?应该设置些什么东西呢? 菜单,Edit => Proj ...
- August 28th 2017 Week 35th Monday
The truth may hurt for a little while but a lie hurts forever. 真相会让我们痛一阵,但谎言会让我们痛一生. Once you make a ...
- kafka概要设计
Kafka核心功能 即:高性能的消息发送与高性能的消息消费 下载安装包后即可启动Kafka服务器,但是此前需要首先启动Zookeeper服务器,Zookeeper是为Kafka提供协调服务的工具,Ka ...
- Foj 2299 Prefix(AC自动机、DP)
Foj 2299 Prefix 题意 给定串s.正整数n,问有多少长度为n的字符串t满足:s[0...i]是t的子串,s[0...i+1]不是. 题解 求有多少长度为n的字符串t满足:s[0...i] ...
- 020.2.1 system
内容:System的常用方法1.currentTimeMillis()方法(与1970年相差多少毫秒),2.Properties getProperties():获取系统属性3.Set<Str ...
- python接口测试-项目实践(八) 完成的接口类和执行脚本
脱敏后脚本 projectapi.py: 项目接口类 # -*- coding:utf-8 -*- """ xx项目接口类 2018-11 dinghanhua &quo ...
- Redis命令、数据结构场景、配置文件总结
本文大纲 一.常用数据类型简介二.redis操作命令三.redis配置文件详解四.redis数据类型使用场景 一.常用数据类型简介 redis常用五种数据类型:string,hash,list,set ...
- 【转】Faster RCNN 原理
看过好几篇讲Faster RCNN的文章,有一些基础以后,看这个文章是最好的. https://www.cnblogs.com/wangyong/p/8513563.html