Mapreduce中maptask过程详解
一、Maptask并行度与决定机制
1.一个job任务的map阶段的并行度默认是由该任务的大小决定的;
2.一个split切分分配一个maprask来并行处理;
3.默认情况下,split切分的大小等于blocksize大小;
4.切片不是mapper类中对单词的切片,而是对每一个处理文件的单独切片。
eg. 默认情况下,一个maptask处理的文件大小为128M,比如一个400M的数据文件,就需要4个maptask并行来处理,而500M的数据文件也是需要4个maptask。
二、Maptask运行机制
1.读数据文件:执行类Driver通过InputFormat类读取文件中的数据;
2.mapper阶段:通过文件的大小决定了maptask的数量,然后mapper进行逻辑运行(读数据、切分、封装);
3.OutputCollector阶段:mapper方法通过OutputCollector接口将KV对写入到环形缓冲区中(这个过程不需要我们处理我们);
4.溢写阶段:环形缓冲区默认的大小为100M,当环形缓冲区中数据量到达阈值的80%的时候发生溢写,溢写的过程中会保证数据KV对使用默认的分区和排序(HashPartitioner分区、字典排序,而环形缓冲区大小和阈值的大小都是可以通过配置来修改的);
5.归并排序:将溢写的数据进行合并排序。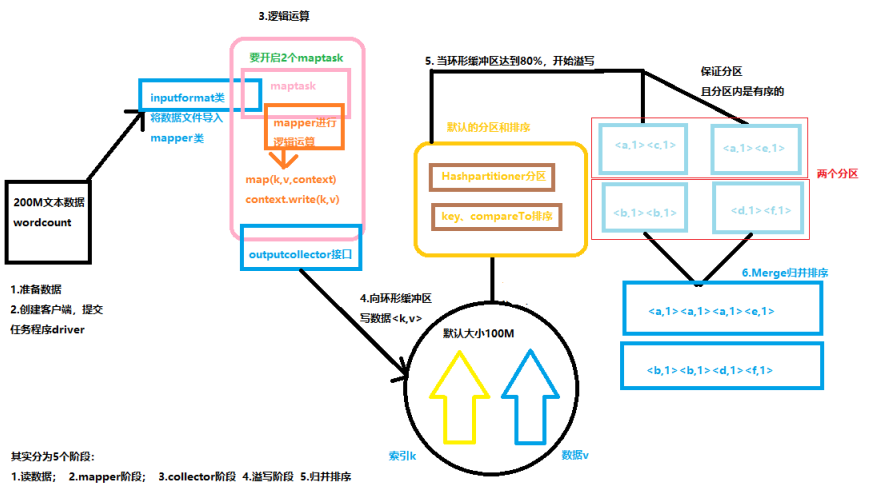
三、MR的小文件优化案例
当许多个小文件上传到HDFS集群上时,每个小文件都将会占用一个blocksize的大小(128M),而且在对它们进行MR计算时,一个文件就会开启一个maptask,这样会浪费很多的资源,下面有两种解决方案:
1.在文件上传到HDFS集群前,先将文件进行合并成一个大的文件,再上传到HDFS集群进行存储和计算;
2.若文件已经上传到HDFS集群,需要直接进行计算时,
可以再Driver类中设置输入流之前设置InputFormatClass属性为CombinerTextInputFormat(它的默认为TextInputFormat),
原理是:CombineTextInputFormat类可以将多个小文件交给一个split切片,然后交给一个maptask来处理,即再Driver类中设置输入流FileInputFormat前加入代码:
job.setInputFormatClass(CombinerTextInputFormat.class);
CombinerTextInputFormat.setMaxInputSplitSize(job,4194304); //设置切片最大值为4M
CombinerTextInputFormat.setMinInputSplitSize(job,3145725); //设置切片最大值为3M
表示大小在3M~4M的文件会被方法一个切片中,那么如果有无数的小文件,一个maptask中大概会有28~42个小文件一起处理。
四、自定义分区Partitioner
在MR程序中,默认分区为HashPartitioner,以下为源码:
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public HashPartitioner() {
}
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & 2147483647) % numReduceTasks;
}
}
HashPartitioner继承了父类Partitioner,其中getPartition方法返回int值0(注释:分区数量决定了reducetask的数量,不分区reducetask值为1,所以一直返回int值0,也就只会产生一个结果文件!!!)
而如果我们想要进行自定义分区,就要重新定义一个分区类继承Partitioner类:
public class FlowPartitioner extends Partitioner<Text,FlowBean> {
@Override
public int getPartition(Text key, FlowBean value, int i) {
//获取用来分区的电话号码前三位
String phoneNum = key.toString().substring(0, 3);
//设置分区逻辑
int partitionNum = 4;
if ("135".equals(phoneNum)){
return 0;
}else if ("137".equals(phoneNum)){
return 1;
}else if ("138".equals(phoneNum)){
return 2;
}else if ("139".equals(phoneNum)){
return 3;
}
return partitionNum;
}
}
我在流量统计案例中也写了该分区类,然后再Driver类中的InputFormat类之前加入设置的自定义分区代码:
job.setPartitionClass(PhoneNumPartitioner.class);
job.setNumReduceTasks(5); (注意:输出文件数量要大于partitioner分区的数量)
总结:MR程序运算过程中,决定maptask个数的有块大小(blocksize)、数据文件大小、文件输入方式(小文件优化);而决定reducetask个数的是分区(无分区时reducetask个数为1,生成一个结果文件)。
Mapreduce中maptask过程详解的更多相关文章
- Android中mesure过程详解
我们在编写layout的xml文件时会碰到layout_width和layout_height两个属性,对于这两个属性我们有三种选择:赋值成具体的数值,match_parent或者wrap_conte ...
- Hadoop学习之路(二十三)MapReduce中的shuffle详解
概述 1.MapReduce 中,mapper 阶段处理的数据如何传递给 reducer 阶段,是 MapReduce 框架中 最关键的一个流程,这个流程就叫 Shuffle 2.Shuffle: 数 ...
- MapReduce的shuffle过程详解
[学习笔记] 结果分析:shuffle的英文是洗牌,混洗的意思,洗牌就是越乱越好的意思.当在集群的情况下是这样的,假如有三个map节点和三个reduce节点,一号reduce节点的数据会来自于三个ma ...
- MapReduce:Shuffle过程详解
1.Map任务处理 1.1 读取HDFS中的文件.每一行解析成一个<k,v>.每一个键值对调用一次map函数. <0,hello you> & ...
- Hadoop Mapreduce的shuffle过程详解
1.map task读取数据时默认调用TextInputFormat的成员RecoreReader,RecoreReader调用自己的read()方法,进行逐行读取,返回一个key.value; 2. ...
- MapReduce过程详解(基于hadoop2.x架构)
本文基于hadoop2.x架构详细描述了mapreduce的执行过程,包括partition,combiner,shuffle等组件以及yarn平台与mapreduce编程模型的关系. mapredu ...
- Hadoop MapReduce执行过程详解(带hadoop例子)
https://my.oschina.net/itblog/blog/275294 摘要: 本文通过一个例子,详细介绍Hadoop 的 MapReduce过程. 分析MapReduce执行过程 Map ...
- Hadoop Mapreduce分区、分组、二次排序过程详解[转]
原文地址:Hadoop Mapreduce分区.分组.二次排序过程详解[转]作者: 徐海蛟 教学用途 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2) ...
- Hadoop学习之Mapreduce执行过程详解
一.MapReduce执行过程 MapReduce运行时,首先通过Map读取HDFS中的数据,然后经过拆分,将每个文件中的每行数据分拆成键值对,最后输出作为Reduce的输入,大体执行流程如下图所示: ...
随机推荐
- mongoDB 文档操作_查
基本查询命令 find 查找复合条件的所有文档 命令 db.collection.find(query,field) 参数 query 查找条件 格式: {ssss:"xxx"}是 ...
- 【BZOJ5506】[GXOI/GZOI2019]旅行者(最短路)
[BZOJ5506][GXOI/GZOI2019]旅行者(最短路) 题面 BZOJ 洛谷 题解 正着做一遍\(dij\)求出最短路径以及从谁转移过来的,反过来做一遍,如果两个点不由同一个点转移过来就更 ...
- 【UR #7】水题走四方
题目描述 今天是世界水日,著名的水题资源专家蝈蝈大臣发起了水题走四方活动,向全世界发放成千上万的水题. 蝈蝈大臣是家里蹲大学的教授,当然不愿意出门发水题啦!所以他委托他的助手欧姆来发. 助手欧姆最近做 ...
- 扩展CRT +扩展LUCAS
再次感谢zyf2000超强的讲解. 扩展CRT其实就是爆推式子,然后一路合并,只是最后一个式子上我有点小疑惑,但整体还算好理解. #include<iostream> #include&l ...
- sopUI上手教程
1.新建项目 File-->New SOAP Project-->Project Name:填入项目名 Initial WSDL:填入项目的 web Services 2.添加WSDL ...
- cdq分治(hdu 5618 Jam's problem again[陌上花开]、CQOI 2011 动态逆序对、hdu 4742 Pinball Game、hdu 4456 Crowd、[HEOI2016/TJOI2016]序列、[NOI2007]货币兑换 )
hdu 5618 Jam's problem again #include <bits/stdc++.h> #define MAXN 100010 using namespace std; ...
- Ansible安装部署以及常用模块详解
一. Ansible 介绍Ansible是一个配置管理系统configuration management system, python 语言是运维人员必须会的语言, ansible 是一个基于py ...
- Shpinx在PHPCMS里的使用及配置
现在可以用最新版的Sphinx版本 网址:http://sphinxsearch.com/downloads/release/ 我使用rpm方式: 下载RHEL/CentOS 6.x x86_64 R ...
- VIM --使用进阶 -- 插件篇 -- YouCompleteMe -- nerdtree
系统:ubuntu: 资源:https://github.com/ 其他:想了解都要哪些好用的插件,推荐大家读 http://blog.csdn.net/mergerly/article/detail ...
- Java中多态性的实现
class A ...{ public String show(D obj)...{ return ("A and D"); } public String show(A obj) ...