(一)CentOS6.3安装Hadoop2.6.5
1.准备环境
下载CentOS:
https://www.centos.org/download/
下载JDK:
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
下载 Hadoop:
https://hadoop.apache.org/releases.html
2.安装步骤
首先熟悉以下linux常用命令。
cd / 切换到根目录
cd ~ 切换到用户跟目录
mkdir xxx新增目录
ls -a 查看当前目录下的所有目录,以及隐藏目录
ls -l 查看当前目录下的所有目录的详细信息
find /root -name *test*搜索目录
mv xxx aaa (xxx 旧目录名,aaa新目录名) 修改目录
mv yyy /root (yyy需要修改目录。/root 剪切到的位置) 移动目录
cp -r aaa / (将aaa目录复制到根目录下)
cp tt.zip / (将tt.zip复制到根目录下)
rm 删除文件
rm-r 删除目录
rm-rf 强制删除目录
touch test.txt 新建文件
rm -rf xxx.txt 删除文件
tar -zcvf 打包后的名称 打包前的名称 压缩文件
tar -zcvf xxx.tar.gz ./* (./*表示当前目录下的所有文件)
tar-xvf 包名 解压到当前的目录
tar-xvf 包名 -C 目标目录 解压到指定的目标目录
文件编辑:
vim文件名-->进入文件-->命令模式-->按i进入编辑模式-->编辑文件-->按Esc进入底行模式-->输入:-->输入命令 wq(保存并退出) 输入q! (不保存,强制退出)
yum install packagexx安装Linux的源包软件
yum remove xx 卸载软件
rpm -ivh package安装第三方源包
rpm -e --nodeps xxx 卸载
了解掌握以上基础命令可以让一个新手少走很多弯路。
安装准备
安装前最好是启用并登录root用户操作,会减少很多麻烦。
注意安装包和系统是否匹配,如果是64位,则保证都是64位二进制程序。
linux操作最好还是选择CentOS,ubuntu亲测系统容易崩溃,恢复起来难度太大。
修改主机名:
vim /etc/sysconfig/network
这里考虑后期集群配置,主机名设置为:Master.Hadoop
NETWORKING=yes
HOSTNAME=Master.Hadoop

配置Host,配置的作用是不用每次都输入这么长的IP
vim /etc/hosts
文件尾部增加:192.168.241.130 Master.Hadoop
配置完成后,重启机器。

2.1安装JDK
在/usr/lib/下新建jdk1.8文件夹
下载好的安装包jdk-8u161-linux-x64.tar.gz复制到jdk1.8目录下,解压提取文件到当前目录。
解压完安装包,并按照目录放置程序后,配置环境变量。
vim /etc/profile
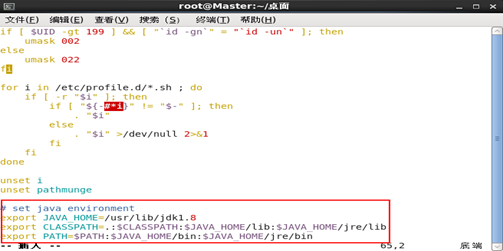
# set java environment
export JAVA_HOME=/usr/lib/jdk1.8
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
source /etc/profile
2.2安装=Hadoop
在/usr/lib/下新建hadoop2.6.5文件夹
下载好的安装包hadoop-2.6.5.tar.gz复制到jdk1.8目录下,解压提取文件到当前目录。
配置环境变量:

#hadoop2.6.5
export HADOOP_HOME=/usr/lib/hadoop2.6.5
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib"
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
配置生效
source /etc/profile
接下来配置hadoop,每一步一定要信息,不然后期排查问题够头疼的。
所有配置文件目录:/usr/lib/hadoop2.6.5/etc/hadoop,共6个文件需要配置。
(1)配置:core-site.xml

<configuration>
<!-- HDFS file path -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.241.130:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/lib/hadoop2.6.5/tmp</value>
<description>Abasefor other temporary directories.</description>
</property>
</configuration>
目录下file:/usr/hadoop/hadoop-2.6.5/tmp,tmp目录需要手动创建。
(2)配置:hdfs-site.xml
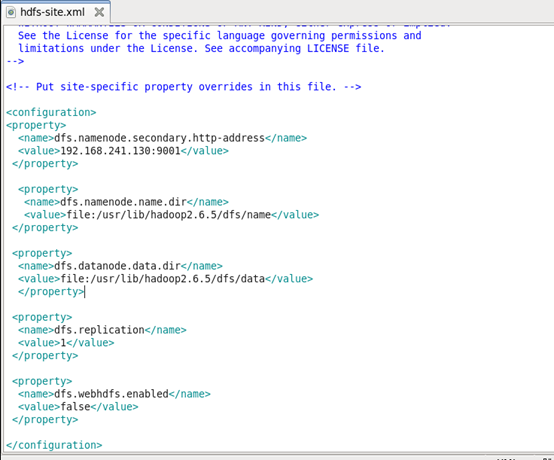
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.241.130:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/lib/hadoop2.6.5/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/lib/hadoop2.6.5/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>false</value>
</property>
</configuration>
(3)配置mapred-site.xml
mapred-site配置需要手动添加一个该文件,或者直接复制系统给出的mapred-site.xml.template内容
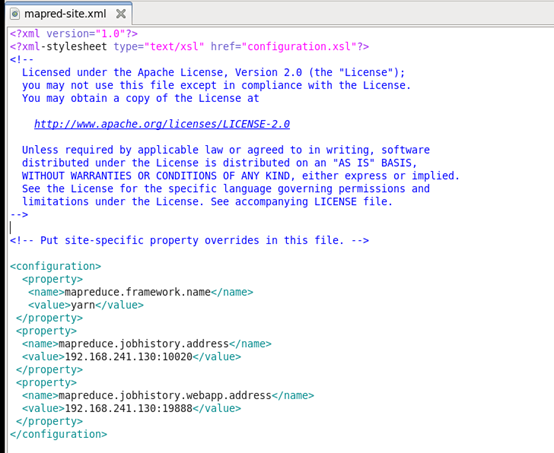
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.241.130:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.241.130:19888</value>
</property>
</configuration>
(4)配置yarn-site.xml
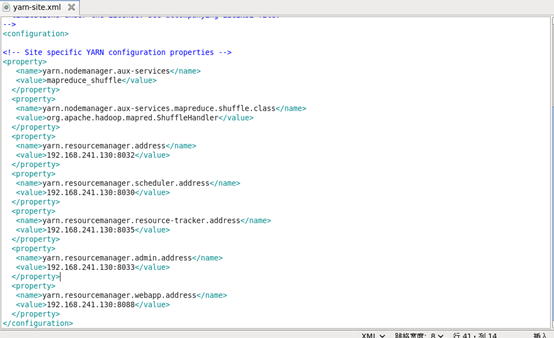
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.241.130:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.241.130:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.241.130:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.241.130:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.241.130:8088</value>
</property>
(5)配置hadoop-env.sh
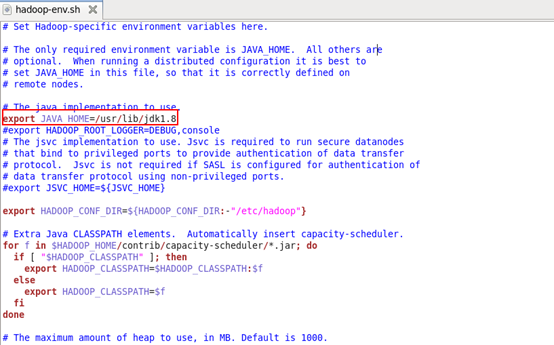
export JAVA_HOME=/usr/lib/jdk1.8
(6)配置yarn-env.sh

export HADOOP_YARN_USER=/usr/lib/jdk1.8
配置完成后,最好从头到位再检查一遍,一定注意每个细节不出问题。
3. 启动Hadoop
首先切换到安装目录
HDFS初始化
bin/hadoop namenode –format

启动HDFS
$HADOOP_HOME/sbin/start-dfs.sh
停止HDFS
$HADOOP_HOME/sbin/stop-dfs.sh
查看运行状态
$HADOOP_HOME/bin/hadoop dfsadmin –report

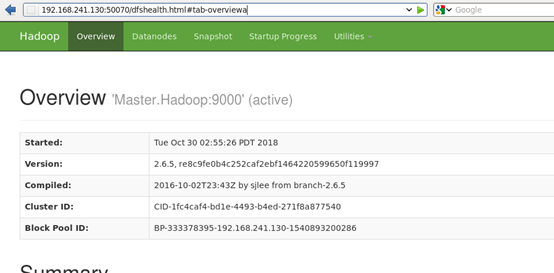
视图查看运行状态
http://192.168.241.130:50070/dfshealth.html#tab-overviewa
Hadoop集群启动
$HADOOP_HOME/sbin/start-yarn.sh
停止Hadoop集群
$HADOOP_HOME/sbin/stop-yarn.sh

视图查看集群运行状态
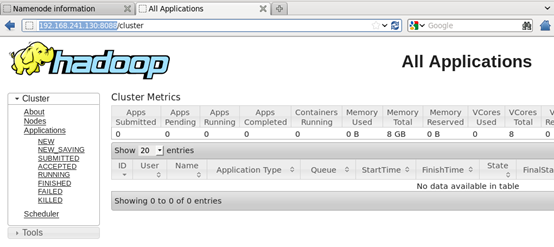
4.异常排除
当然,很多情况下都不能一次成功的。下面是集中常见的异常和处理办法。
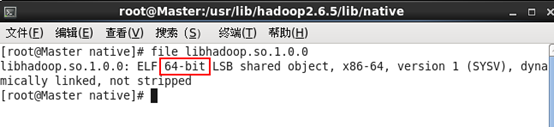
(1)WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
出现这个异常时,很有可能是/usr/lib/hadoop2.6.5/lib/native版本与系统版本不对应导致,
这种情况在hadoop2.4之前的版本比较常见,因为官网编译的二进制包是32位。
可以执行file libhadoop.so.1.0.0查版本。
网上还提到一种缺少配置的异常解决办法:
在hadoop-env.sh中重新配置:
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native/"
当尝试多种办法不能得以解决时,我们可以进入debug模式查看异常具体原因:
在etc/hadoop/hadoop-env.sh文件中添加下面配置:

export HADOOP_ROOT_LOGGER=DEBUG,console
(2)配置ssh
配置hadoop集群时一定要配ssh免密登录,但是配单机有时候也会提示SSH的异常,配置方法如下:
检测是否已经配置ssh
ssh -version
获取并安装ssh
sudo apt install openssh-server
或者通过yum install openssh-server安装
配置ssh免密登录
ssh-keygen -t rsa #回车
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
测试ssh无密登陆
ssh 主机名 #如果不提示输入密码则配置成功
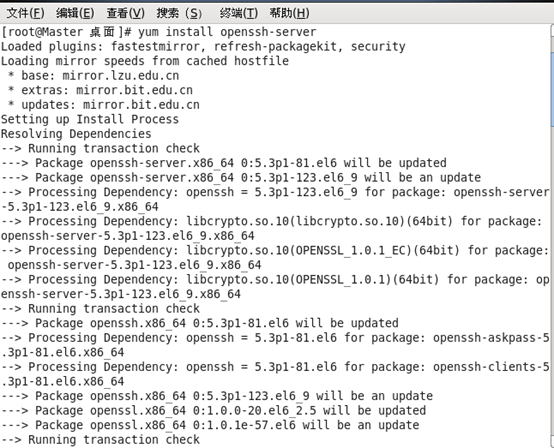
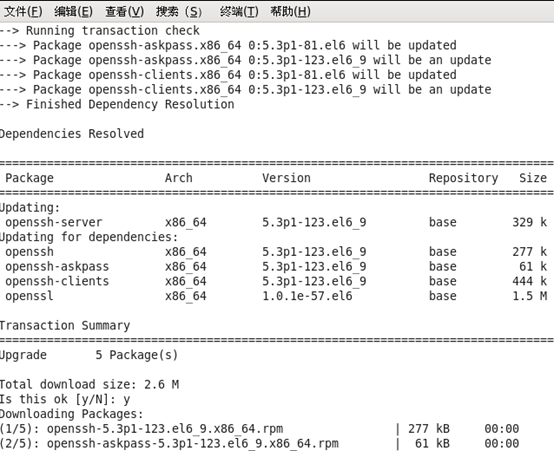
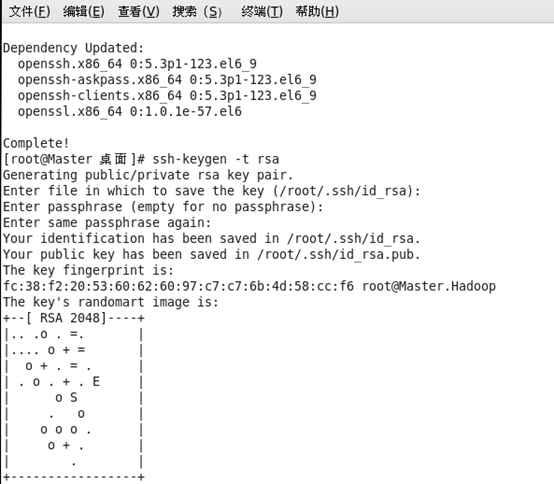

(3)需要配置安装2.14的glibc库
有网友提供了下载地址:http://pan.baidu.com/s/1eRNygZC 密码:s2r0
下载下来,放在桌面任意位置都行,把所有文件放在一个文件夹里。
执行:rpm -Uvh glibc-2.14.1-6.x86_64.rpm glibc-common-2.14.1-6.x86_64.rpm glibc-headers-2.14.1-6.x86_64.rpm glibc-devel-2.14.1-6.x86_64.rpm nscd-2.14.1-6.x86_64.rpm
安装完成
(4)异常openssl: false Cannot load libcrypto.so (libcrypto.so: 无法打开共享对象文件: 没有那个文件或目录
打开缺少的路径,这里缺少的是usr/lib64
执行命令:
echo "/usr/ lib64 " >> /etc/ld.so.conf
ldconfig

(5) WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
所有准备就绪,执行hadoop fs –ls /时又出现
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
ls: `.': No such file or directory
此时按照之前方式debug 查看具体原因,发现缺少HADOOP_OPTS配置。
在hadoop-env.sh中添加HADOOP_OPTS配置

# Extra Java runtime options. Empty by default.
#export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true"
export HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib:$HADOOP_PREFIX/lib/native"
(一)CentOS6.3安装Hadoop2.6.5的更多相关文章
- Centos6下安装Hadoop2.6 问题总结
一. 安装背景:VirtualBox下安装三台Centos6.8虚拟机(一主:master, 两从:slave1,slave2) Centos版本:CentOS-6.8-x86_64 网络配置:三台虚 ...
- centos6.6安装hadoop-2.5.0(三、完全分布式安装)
操作系统:centos6.6(三台服务器) 环境:selinux disabled:iptables off:java 1.8.0_131 安装包:hadoop-2.5.0.tar.gz hadoop ...
- centos6.6安装hadoop-2.5.0(一、本地模式安装)
操作系统:centos6.6(一台服务器) 环境:selinux disabled:iptables off:java 1.8.0_131 安装包:hadoop-2.5.0.tar.gz hadoop ...
- centos6.6安装hadoop-2.5.0(二、伪分布式部署)
操作系统:centos6.6(一台服务器) 环境:selinux disabled:iptables off:java 1.8.0_131 安装包:hadoop-2.5.0.tar.gz 伪分布式环境 ...
- centos6.6安装hadoop-2.5.0(五、部署过程中的问题解决)
操作系统:centos6.6 环境:selinux disabled:iptables off:java 1.8.0_131 安装包:hadoop-2.5.0.tar.gz 一.安装过程中会出现WAR ...
- CentOS6.4安装Hadoop2.0.5 alpha - Single Node Cluster
1.安装JDK7 rpm到/usr/java/jdk1.7.0_40,并建立软链接/usr/java/default到/usr/java/jdk1.7.0_40 [root@server-308 ~] ...
- centos6.6安装hadoop-2.5.0(四、hadoop HA安装)
操作系统:centos6.6 环境:selinux disabled:iptables off:java 1.8.0_131 安装包:hadoop-2.5.0.tar.gz HA模式下的HADOOP完 ...
- CentOS6.4安装Hadoop2.0.5 alpha - 3-Node Cluster
1.在第2个个节点上重复http://www.cnblogs.com/littlesuccess/p/3361497.html文章中的第1-5步 2.修改第1个节点上的hdfs-site.xml中的配 ...
- centos6.6安装hadoop-2.5.0(六、各种node功能)
一.hadoop的YARN框架 hadoop的YARN职能就是将资源调度和任务调度分开 ResourceManager全局管理所有应用程序计算资源的分配,每一个job的ApplicationMaste ...
随机推荐
- 3--Postman--变量(environment&global)
(1) Environment clear an environment variable: pm.environment.unset("variable_key")--recom ...
- 停止node进程和查看react-native-cli
taskkill /f /t /im node.exe which react-native
- Spark的mlib中的稠密向量和稀疏向量
spark mlib中2种局部向量:denseVector(稠密向量)和sparseVector(稀疏向量) denseVector向量的生成方法:Vector.dense() sparseVecto ...
- React生命周期简单详细理解
前言 学习React,生命周期很重要,我们了解完生命周期的各个组件,对写高性能组件会有很大的帮助. Ract生命周期 React 生命周期分为三种状态 1. 初始化 2.更新 3.销毁 初始化 1.g ...
- AJ的笔记之上拉电阻的工作原理分析
第二章:聊一聊上拉电阻的工作原理 **********本文所采用的单片机是:STC89C52RC系******************** [重点提要]其实,理解上拉电阻的原理,关键是理解这两个词:锁 ...
- jmeter 上传附件脚本报Non HTTP response code: java.io.FileNotFoundException
如果上传附件报如下错误,就需要把附件放到和脚本同一路径下就解决了
- UVA10562(看图写树,dfs)
这个题过的好艰难,不过真的学到好多. 关于fgets的用法真的是精髓.!isspace(c)和c!=' '是有区别的. 其它的看代码吧 #include <iostream> #inclu ...
- what are you 弄啥嘞!!!!!!!!!!!!!!!!泛型
1.为什么需要泛型 泛型在Java中有很重要的地位,网上很多文章罗列各种理论,不便于理解,本篇将立足于代码介绍.总结了关于泛型的知识.希望能给你带来一些帮助. 先看下面的代码: List list = ...
- 作业一 :关于C语言
C语言是计算机专业的基础课,同时也是计算机专业的第一个入门语言,学好C语言母庸质疑.就目前来看,在C语言中已经学习的内容有:基本运算符及表达式.输入输出函数.选择 结构程序设计.循环结构程序设计.数组 ...
- 微信企业付款获取RSA
package com.hentica.app.test.wx; import com.plant.app.modules.pay.wxpay.config.WxpayConfig; import o ...