利用python抓取页面数据
1、首先是安装python(注意python3.X和python2.X是不兼容的,我们最好用python3.X)
安装方法:安装python
2、安装成功后,再进行我们需要的插件安装。(这里我们需要用到requests和pymssql两个插件re是自带的)注:这里我们使用的是sqlserver所以安装的是pymssql,如果使用的是mysql可以参考:安装mysql驱动
安装插件的方法为
安装pymssql->进入命令行输入命令:pip install pymssql
安装requests->进入命令行输入命令:pip install requests
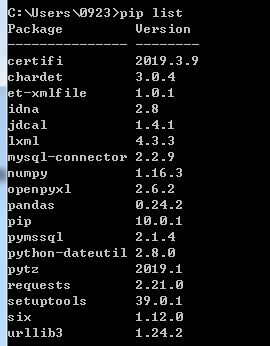
可以通过命令pip list来查看是否安装成功。
3、安装完成后,我们编写代码如下:
import requests
from requests.exceptions import RequestException
import re
import pymssql #通过url获得页面内容
def get_one_page(url):
try:
response = requests.get(url)
#解决乱码问题
response.encoding = response.apparent_encoding
if response.status_code == 200:
return response.text
return None
except RequestException:
return None #通过正则表达式抓取我们所需要的页面内容
def parse_one_page(html):
pattern = re.compile('<div class="newBox">.*?src="(.*?)".*?<h4>.*?<div class="fp_subtitle">.*?>(.*?)</a></div>.*?</h4>.*?<p>(.*?)</p>.*?<span>(.*?)</span>.*?<span>(.*?)</span>.*?<span>(.*?)</span>.*?</div>',re.S)
items = re.findall(pattern,html)
return items; #数据库连接
def db_conn():
server = '192.168.6.111\mssqlzf'
user = 'sa'
password = 'sa@2016'
database = 'zfnewdb'
return pymssql.connect(server, user, password, database) #定义main()
def main():
conn = db_conn()
url = 'http://www.stdaily.com/cxzg80/index.shtml'
html = get_one_page(url)
cursor = conn.cursor()
#将抓取回来的数据循环插入到数据库中,注意:parse_one_page返回的数据类型为
for item in parse_one_page(html):
cursor.execute("INSERT INTO tblGrabNews VALUES (%s,%s,%s,%s,%s,%s)",(item[1], item[2], item[0], item[5], item[3], item[4]))
conn.commit()
conn.close() #执行main()
if __name__ == '__main__':
main()
注意,parse_one_page(html)函数返回的数据类型如下:[(),(),()...],所以上面程序要的for循环才会那么去写,如果不知道什么是list和tuple的同学可以看一下这篇文章list和tuple。

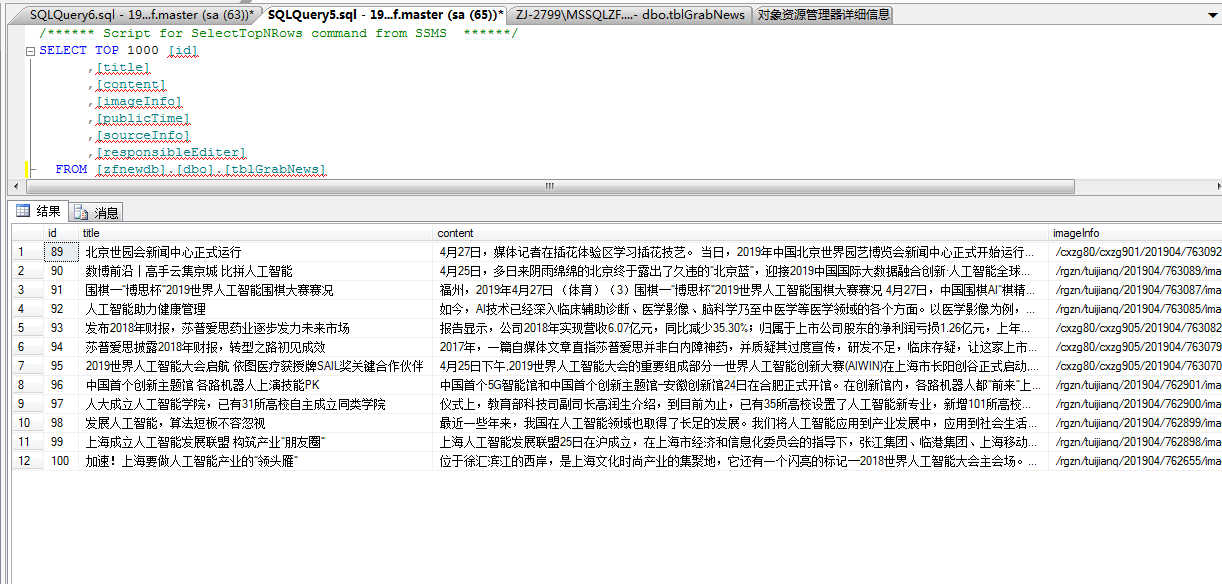
运行上述代码后,可在数据库中看到爬下来的数据。
数据表结构为:
create table [zfnewdb].[dbo].[tblGrabNews] (
id int identity (1,1) primary key,
title varchar(255),
content text,
imageInfo text,
publicTime varchar(100),
sourceInfo varchar(100),
responsibleEditer varchar(100)
)
希望能帮助到有需要的人。
利用python抓取页面数据的更多相关文章
- 爬虫抓取页面数据原理(php爬虫框架有很多 )
爬虫抓取页面数据原理(php爬虫框架有很多 ) 一.总结 1.php爬虫框架有很多,包括很多傻瓜式的软件 2.照以前写过java爬虫的例子来看,真的非常简单,就是一个获取网页数据的类或者方法(这里的话 ...
- Python抓取页面中超链接(URL)的三中方法比较(HTMLParser、pyquery、正则表达式) <转>
Python抓取页面中超链接(URL)的3中方法比较(HTMLParser.pyquery.正则表达式) HTMLParser版: #!/usr/bin/python # -*- coding: UT ...
- 对比使用Charles和Fiddler两个工具及利用Charles抓取https数据(App)
对比使用Charles和Fiddler两个工具及利用Charles抓取https数据(App) 实验目的:对比使用Charles和Fiddler两个工具 实验对象:车易通App,易销通App 实验结果 ...
- python 抓取alexa数据
要抓取http://www.alexa.cn/rank/baidu.com网站的排名信息:例如抓取以下信息: 需要微信扫描登录 因为这个网站抓取数据是收费,所以就利用网站提供API服务获取json信息 ...
- 记录使用jQuery和Python抓取采集数据的一个实例
从现成的网站上抓取汽车品牌,型号,车系的数据库记录. 先看成果,大概4w条车款记录 一共建了四张表,分别存储品牌,车系,车型和车款 大概过程: 使用jQuery获取页面中呈现的大批内容 能通过页面一次 ...
- python 抓取金融数据,pandas进行数据分析并可视化系列 (一)
终于盼来了不是前言部分的前言,相当于杂谈,算得上闲扯,我觉得很多东西都是在闲扯中感悟的,比如需求这东西,一个人只有跟自己沟通好了,总结出某些东西了,才能更好的和别人去聊,去说. 今天这篇写的是明白需求 ...
- js 抓取页面数据
数据抓取 主要思路和原理 在根节点document中监听所有需要抓取的事件 在元素事件传递中,捕获阶段获取事件信息,进行埋点 通过getBoundingClientRect() 方法可获取元素的大小和 ...
- 使用python抓取App数据
App接口爬取数据过程使用抓包工具手机使用代理,app所有请求通过抓包工具获得接口,分析接口反编译apk获取key突破反爬限制需要的工具:夜神模拟器FiddlerPycharm实现过程首先下载夜神模拟 ...
- 网络爬虫-使用Python抓取网页数据
搬自大神boyXiong的干货! 闲来无事,看看了Python,发现这东西挺爽的,废话少说,就是干 准备搭建环境 因为是MAC电脑,所以自动安装了Python 2.7的版本 添加一个 库 Beauti ...
随机推荐
- javascript的数组之pop()
pop()方法从数组中删除最后一个元素,并返回该元素的值.此方法更改数组的长度. let a = [1, 2, 3]; a.length; a.pop(); console.log(a); // [1 ...
- USB包格式解析(转)
本文对应usb2.0协议的第八章Protocol Layer. 数据是由二进制数字串构成的,首先数字串构成域(有七种),域再构成包,包再构成事务(IN.OUT.SETUP),事务最后构成传输(中断传输 ...
- nginx,maven
nginx反向代理 负载均衡 keepalive高可用 lvs负载均衡算法 mvn build自定义命令 install安装到本地仓库
- MS17-010 漏洞研究——免考课题 20155104 赵文昊
免考实验与研究--MS17-010漏洞研究 研究内容 ·MS17-010漏洞的来源 ·MS17-010漏洞的攻击实例 ·MS17-010漏洞原理分析 ·MS17-010代码分析 写在前面:这次对一个漏 ...
- python数据分析算法(决策树2)CART算法
CART(Classification And Regression Tree),分类回归树,,决策树可以分为ID3算法,C4.5算法,和CART算法.ID3算法,C4.5算法可以生成二叉树或者多叉树 ...
- bootstrap-treeview树形图参数详解
哈哈 找了半天找到了,需要的可以去看看! 直接放上博客链接:https://blog.csdn.net/hailangtuteng/article/details/80842730
- CF1033G Chip Game
题意 给你一个长度为\(n\)的序列和一个数\(m\). 小A和小B分别在\([1,m]\)选出一个数\(a\)和\(b\),然后开始游戏. 轮到小A时,他选择一个元素减\(a\):小B则选择一个元素 ...
- iconfont在线链接使用方法(转)
原文:https://blog.csdn.net/jinkingliao/article/details/51353937 基础流程就不多赘述,直接到http://www.iconfont.cn/官网 ...
- 初识springboot
一.springboot简介: 1.简化spring应用开发框架 2.把spring所有技术整合在了一起 3.J2EE开发的一站式解决方案 我曾经学习springMVC时候,那许许多多的配置文件的配置 ...
- webpack(6)-模块热替代&tree shaking
模块热替换(hot module replacement 或 HMR) 模块热替换(hot module replacement 或 HMR)是 webpack 提供的最有用的功能之一.它允许在运行时 ...