python 抓取alexa数据
要抓取http://www.alexa.cn/rank/baidu.com网站的排名信息:例如抓取以下信息:

需要微信扫描登录
因为这个网站抓取数据是收费,所以就利用网站提供API服务获取json信息:
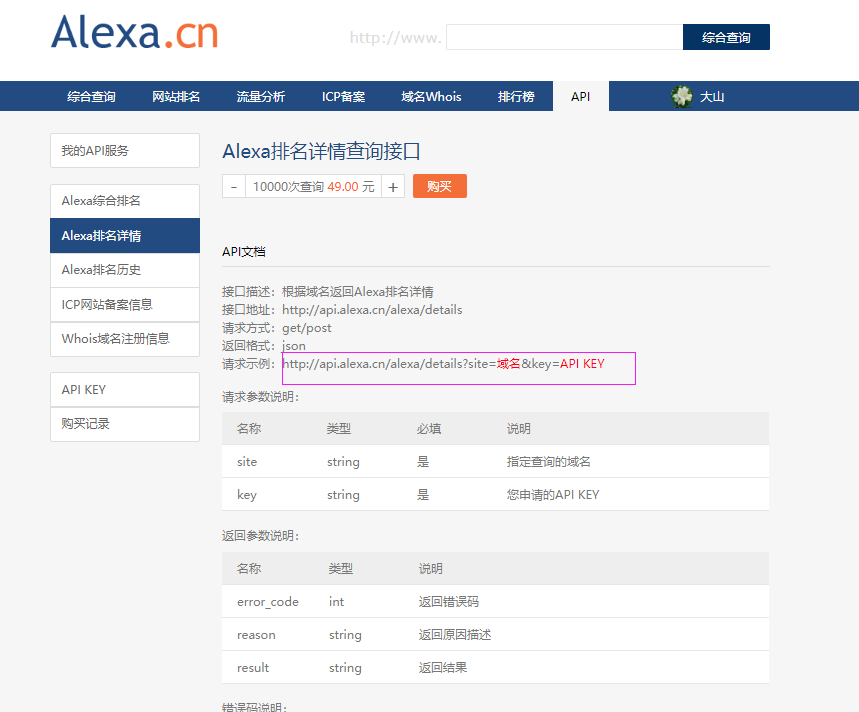
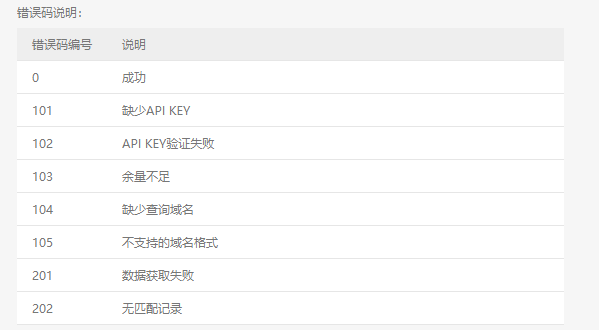

上面的API KEY值需要花钱买的(注意开通会员的方式不行,必须以10000次查询 49.00 元这种方式,比较坑爹啊)
具体python代码
# coding=utf-8
import json
import httplib2
import json
import xlrd
import xlwt
import os
import datetime
import time
class alexa: def __init__(self,key="7Z4ddd6ywaQuo6RkKfI3SzGeKn8Mavde"):
self.key = key def WriteLog(self, message,date):
fileName = os.path.join(os.getcwd(), 'alexa/' + date + '.txt')
with open(fileName, 'a') as f:
f.write(message) def WriteSheetRow(self,sheet, rowValueList, rowIndex, isBold):
i = 0
style = xlwt.easyxf('font: bold 1')
# style = xlwt.easyxf('font: bold 0, color red;')#红色字体
style2 = xlwt.easyxf('pattern: pattern solid, fore_colour yellow; font: bold on;') # 设置Excel单元格的背景色为黄色,字体为粗体
for svalue in rowValueList:
if isBold:
sheet.write(rowIndex, i, svalue, style2)
else:
sheet.write(rowIndex, i, svalue)
i = i + 1 def save_Excel(self,headList,valuelist,fileName):
wbk = xlwt.Workbook()
sheet = wbk.add_sheet('sheet1', cell_overwrite_ok=True)
# headList = ['周期', '全球网站排名', '变化趋势', '日均UV']
rowIndex = 0
self.WriteSheetRow(sheet, headList, rowIndex, True)
for lst in valuelist:
rowIndex+=1
self.WriteSheetRow(sheet, lst, rowIndex, False)
wbk.save(fileName) def getAlexaData(self,domain):
url="http://api.alexa.cn/alexa/details?site=%s&key=%s"%(domain,self.key)
try:
h = httplib2.Http(".cache")
(resp_headers, content) = h.request(url, "GET")
data = json.loads(content.decode('utf8'))
self.parserData(data)
# print(data) except Exception as e1:
error = "ex" def parserData(self,data):
# f = open("alexa.txt", "r")
# txt = f.read()
# data = json.loads(txt) traffic_dict = data["result"]["traffic_data"]
day = traffic_dict["day"] week = traffic_dict["week"]
month = traffic_dict["month"]
three_month = traffic_dict["three_month"] trafic_headList = ['周期', '全球网站排名', '变化趋势', '日均UV', '日均PV']
traffic_data_list =[]
day_list = ["当日"]
week_list = ["周平均"]
month_list = ["月平均"]
three_month_list = ["三月平均"]
trafic = ["time_range", "traffic_rank", "traffic_rank_delta", "avg_daily_uv", "avg_daily_pv"]
length = len(trafic)
for i in range(1,length):
day_list.append(day[trafic[i]])
week_list.append(week[trafic[i]])
month_list.append(month[trafic[i]])
three_month_list.append(three_month[trafic[i]]) traffic_data_list.append(day_list)
traffic_data_list.append(week_list)
traffic_data_list.append(month_list)
traffic_data_list.append(three_month_list) fileName = datetime.datetime.now().strftime('%Y-%m-%d')+"_traffic.xlsx"
fileName = os.path.join(os.getcwd(),fileName)
self.save_Excel(trafic_headList,traffic_data_list,fileName) country_headList = ['国家/地区名称', '国家/地区代码', '国家/地区排名', '网站访问比例', '页面浏览比例']
country_data_list = []
country_data = data["result"]["country_data"]
col_list = ["country","code","rank","per_users","per_pageviews"]
length = len(col_list)
for item in country_data:
lst =[]
for i in range(0,length):
lst.append(item[col_list[i]])
country_data_list.append(lst) fileName = datetime.datetime.now().strftime('%Y-%m-%d') + "_country.xlsx"
fileName = os.path.join(os.getcwd(), fileName)
self.save_Excel(country_headList, country_data_list, fileName) subdomains_headList = ['被访问网址', '近月网站访问比例', '近月页面访问比例', '人均页面浏览量']
subdomains_data_list = []
subdomains_data = data["result"]["subdomains_data"]
sub_col_list = ["subdomain", "reach_percentage", "pageviews_percentage", "pageviews_peruser"]
length = len(sub_col_list)
for item in subdomains_data:
lst = []
for i in range(0, length):
lst.append(item[sub_col_list[i]])
subdomains_data_list.append(lst) fileName = datetime.datetime.now().strftime('%Y-%m-%d') + "_subdomains.xlsx"
fileName = os.path.join(os.getcwd(), fileName)
self.save_Excel(subdomains_headList, subdomains_data_list, fileName) # print(("%s,%s,%s,%s,%s") % (day[trafic[0]], day[trafic[1]], day[trafic[2]], day[trafic[3]], day[trafic[4]]))
# print(("%s,%s,%s,%s,%s") % (week[trafic[0]], week[trafic[1]], week[trafic[2]], week[trafic[3]], week[trafic[4]]))
# print(("%s,%s,%s,%s,%s") % (month[trafic[0]], month[trafic[1]], month[trafic[2]], month[trafic[3]], month[trafic[4]]))
# print(("%s,%s,%s,%s,%s") % (three_month[trafic[0]], three_month[trafic[1]], three_month[trafic[2]], three_month[trafic[3]], three_month[trafic[4]]))
# print("\n") # print("country_data")
# country_data = data["result"]["country_data"]
# for item in country_data:
# print(("%s,%s,%s,%s,%s") % (item["country"], item["code"], item["rank"], item["per_users"], item["per_pageviews"]))
#
# print("\n")
# print("subdomains_data")
# subdomains_data = data["result"]["subdomains_data"]
# for item in subdomains_data:
# print(("%s,%s,%s,%s") % (item["subdomain"], item["reach_percentage"], item["pageviews_percentage"], item["pageviews_peruser"])) obj = alexa()
obj.getAlexaData("baidu.com")
# obj.parserData("")
python 抓取alexa数据的更多相关文章
- python 抓取金融数据,pandas进行数据分析并可视化系列 (一)
终于盼来了不是前言部分的前言,相当于杂谈,算得上闲扯,我觉得很多东西都是在闲扯中感悟的,比如需求这东西,一个人只有跟自己沟通好了,总结出某些东西了,才能更好的和别人去聊,去说. 今天这篇写的是明白需求 ...
- 利用python抓取页面数据
1.首先是安装python(注意python3.X和python2.X是不兼容的,我们最好用python3.X) 安装方法:安装python 2.安装成功后,再进行我们需要的插件安装.(这里我们需要用 ...
- 记录使用jQuery和Python抓取采集数据的一个实例
从现成的网站上抓取汽车品牌,型号,车系的数据库记录. 先看成果,大概4w条车款记录 一共建了四张表,分别存储品牌,车系,车型和车款 大概过程: 使用jQuery获取页面中呈现的大批内容 能通过页面一次 ...
- 使用python抓取App数据
App接口爬取数据过程使用抓包工具手机使用代理,app所有请求通过抓包工具获得接口,分析接口反编译apk获取key突破反爬限制需要的工具:夜神模拟器FiddlerPycharm实现过程首先下载夜神模拟 ...
- 网络爬虫-使用Python抓取网页数据
搬自大神boyXiong的干货! 闲来无事,看看了Python,发现这东西挺爽的,废话少说,就是干 准备搭建环境 因为是MAC电脑,所以自动安装了Python 2.7的版本 添加一个 库 Beauti ...
- Python抓取双色球数据
数据来源网站http://baidu.lecai.com/lottery/draw/list/50?d=2013-01-01 HTML解析器http://pythonhosted.org/pyquer ...
- 使用 Python 抓取欧洲足球联赛数据
Web Scraping在大数据时代,一切都要用数据来说话,大数据处理的过程一般需要经过以下的几个步骤 数据的采集和获取 数据的清洗,抽取,变形和装载 数据的分析,探索和预测 ...
- 如何用python抓取js生成的数据 - SegmentFault
如何用python抓取js生成的数据 - SegmentFault 如何用python抓取js生成的数据 1赞 踩 收藏 想写一个爬虫,但是需要抓去的的数据是js生成的,在源代码里看不到,要怎么才能抓 ...
- Python抓取百度百科数据
前言 本文整理自慕课网<Python开发简单爬虫>,将会记录爬取百度百科"python"词条相关页面的整个过程. 抓取策略 确定目标:确定抓取哪个网站的哪些页面的哪部分 ...
随机推荐
- Bomb HDU 3555 dp状态转移
题目:http://acm.hdu.edu.cn/showproblem.php?pid=3555 题意: 给出一个正整数N,求出1~N中含有数字“49”的数的个数 思路: 采用数位dp的状态转移方程 ...
- nc工具学习
0x00.命令详解 基本使用 想要连接到某处:nc [-options] ip port 绑定端口等待连接:nc -l -p port ip 参数: -e prog 程序重定向,一旦连接,就执行 [ ...
- To 初识Java的小菜菜们 嘻嘻~
一.Java Java是一种可以撰写跨平台应用软件的面向对象的程序设计语言.Java 技术具有卓越的通用性.高效性.平台移植性和安全性,广泛应用于PC.数据中心.游戏控制台.科学超级计算机.移动电话和 ...
- iOS 9应用开发教程之定制应用程序图标以及真机测试
iOS 9应用开发教程之定制应用程序图标以及真机测试 定制ios9应用程序图标 在图1.12中可以看到应用程序的图标是网状白色图像,它是iOS模拟器上的应用程序默认的图标.这个图标是可以进行改变的.以 ...
- luoguP4571 [JSOI2009]瓶子和燃料 裴蜀定理
裴蜀定理的扩展 最后返回的一定是\(k\)个数的\(gcd\) 因此对于每个数暴力分解因子统计即可 #include <map> #include <cstdio> #incl ...
- hashmap的遍历方法
How to iterate over the entries of a Map? What is the order of iteration - if you are just using Map ...
- 216. 组合总和 III
216. 组合总和 III 题意 找出所有相加之和为 n 的 k 个数的组合.组合中只允许含有 1 - 9 的正整数,并且每种组合中不存在重复的数字. 说明: 所有数字都是正整数. 解集不能包含重复的 ...
- HDU 1269 移动城堡 联通分量 Tarjan
迷宫城堡 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submis ...
- Git_忽略特殊文件
有些时候,你必须把某些文件放到Git工作目录中,但又不能提交它们,比如保存了数据库密码的配置文件啦,等等,每次git status都会显示“Untracked files ...”,有强迫症的童鞋心里 ...
- .Net C#向远程服务器Api上传文件
Api服务代码一: /// <summary> /// 服务器接收接口 /// </summary> [HttpPost] [Route("ReceiveFile&q ...