利用python抓取页面数据
1、首先是安装python(注意python3.X和python2.X是不兼容的,我们最好用python3.X)
安装方法:安装python
2、安装成功后,再进行我们需要的插件安装。(这里我们需要用到requests和pymssql两个插件re是自带的)注:这里我们使用的是sqlserver所以安装的是pymssql,如果使用的是mysql可以参考:安装mysql驱动
安装插件的方法为
安装pymssql->进入命令行输入命令:pip install pymssql
安装requests->进入命令行输入命令:pip install requests
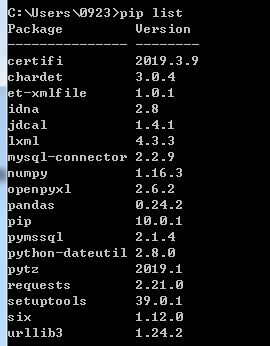
可以通过命令pip list来查看是否安装成功。
3、安装完成后,我们编写代码如下:
import requests
from requests.exceptions import RequestException
import re
import pymssql #通过url获得页面内容
def get_one_page(url):
try:
response = requests.get(url)
#解决乱码问题
response.encoding = response.apparent_encoding
if response.status_code == 200:
return response.text
return None
except RequestException:
return None #通过正则表达式抓取我们所需要的页面内容
def parse_one_page(html):
pattern = re.compile('<div class="newBox">.*?src="(.*?)".*?<h4>.*?<div class="fp_subtitle">.*?>(.*?)</a></div>.*?</h4>.*?<p>(.*?)</p>.*?<span>(.*?)</span>.*?<span>(.*?)</span>.*?<span>(.*?)</span>.*?</div>',re.S)
items = re.findall(pattern,html)
return items; #数据库连接
def db_conn():
server = '192.168.6.111\mssqlzf'
user = 'sa'
password = 'sa@2016'
database = 'zfnewdb'
return pymssql.connect(server, user, password, database) #定义main()
def main():
conn = db_conn()
url = 'http://www.stdaily.com/cxzg80/index.shtml'
html = get_one_page(url)
cursor = conn.cursor()
#将抓取回来的数据循环插入到数据库中,注意:parse_one_page返回的数据类型为
for item in parse_one_page(html):
cursor.execute("INSERT INTO tblGrabNews VALUES (%s,%s,%s,%s,%s,%s)",(item[1], item[2], item[0], item[5], item[3], item[4]))
conn.commit()
conn.close() #执行main()
if __name__ == '__main__':
main()
注意,parse_one_page(html)函数返回的数据类型如下:[(),(),()...],所以上面程序要的for循环才会那么去写,如果不知道什么是list和tuple的同学可以看一下这篇文章list和tuple。

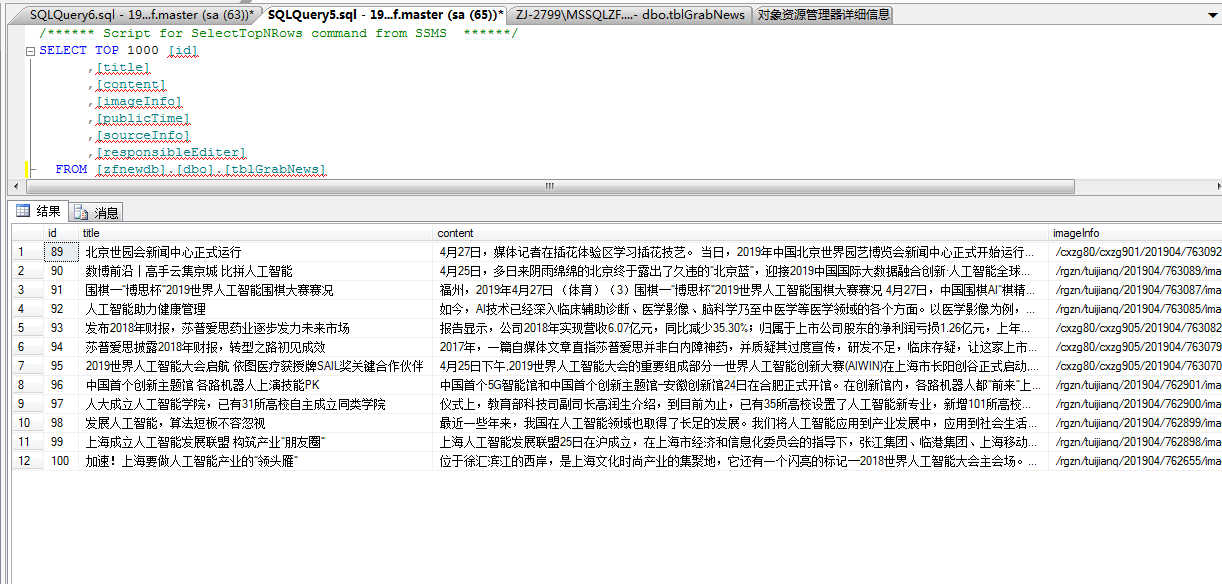
运行上述代码后,可在数据库中看到爬下来的数据。
数据表结构为:
create table [zfnewdb].[dbo].[tblGrabNews] (
id int identity (1,1) primary key,
title varchar(255),
content text,
imageInfo text,
publicTime varchar(100),
sourceInfo varchar(100),
responsibleEditer varchar(100)
)
希望能帮助到有需要的人。
利用python抓取页面数据的更多相关文章
- 爬虫抓取页面数据原理(php爬虫框架有很多 )
爬虫抓取页面数据原理(php爬虫框架有很多 ) 一.总结 1.php爬虫框架有很多,包括很多傻瓜式的软件 2.照以前写过java爬虫的例子来看,真的非常简单,就是一个获取网页数据的类或者方法(这里的话 ...
- Python抓取页面中超链接(URL)的三中方法比较(HTMLParser、pyquery、正则表达式) <转>
Python抓取页面中超链接(URL)的3中方法比较(HTMLParser.pyquery.正则表达式) HTMLParser版: #!/usr/bin/python # -*- coding: UT ...
- 对比使用Charles和Fiddler两个工具及利用Charles抓取https数据(App)
对比使用Charles和Fiddler两个工具及利用Charles抓取https数据(App) 实验目的:对比使用Charles和Fiddler两个工具 实验对象:车易通App,易销通App 实验结果 ...
- python 抓取alexa数据
要抓取http://www.alexa.cn/rank/baidu.com网站的排名信息:例如抓取以下信息: 需要微信扫描登录 因为这个网站抓取数据是收费,所以就利用网站提供API服务获取json信息 ...
- 记录使用jQuery和Python抓取采集数据的一个实例
从现成的网站上抓取汽车品牌,型号,车系的数据库记录. 先看成果,大概4w条车款记录 一共建了四张表,分别存储品牌,车系,车型和车款 大概过程: 使用jQuery获取页面中呈现的大批内容 能通过页面一次 ...
- python 抓取金融数据,pandas进行数据分析并可视化系列 (一)
终于盼来了不是前言部分的前言,相当于杂谈,算得上闲扯,我觉得很多东西都是在闲扯中感悟的,比如需求这东西,一个人只有跟自己沟通好了,总结出某些东西了,才能更好的和别人去聊,去说. 今天这篇写的是明白需求 ...
- js 抓取页面数据
数据抓取 主要思路和原理 在根节点document中监听所有需要抓取的事件 在元素事件传递中,捕获阶段获取事件信息,进行埋点 通过getBoundingClientRect() 方法可获取元素的大小和 ...
- 使用python抓取App数据
App接口爬取数据过程使用抓包工具手机使用代理,app所有请求通过抓包工具获得接口,分析接口反编译apk获取key突破反爬限制需要的工具:夜神模拟器FiddlerPycharm实现过程首先下载夜神模拟 ...
- 网络爬虫-使用Python抓取网页数据
搬自大神boyXiong的干货! 闲来无事,看看了Python,发现这东西挺爽的,废话少说,就是干 准备搭建环境 因为是MAC电脑,所以自动安装了Python 2.7的版本 添加一个 库 Beauti ...
随机推荐
- 接线端子VH,CH,XH
- oracle 表 库实例 空间
地址 http://blog.csdn.net/g15738290530/article/details/51859048 1:个人理解 数据库可以有多个实例,其中 orcl 为默认 一般情况下,一个 ...
- wordpress chronus主题 显示文章阅读数
wordpress chronus主题 显示文章阅读数 第一步:将下面的代码拷贝到文件 /wp-content/themes/chronus/inc/template-tags.php 中 funct ...
- CentOS7 64位安装mysql教程
参考链接:http://baijiahao.baidu.com/s?id=1597184796823517712&wfr=spider&for=pc https://www.cnblo ...
- rbac权限控制,基于无线分类
2018年9月18日11:21:28 数据库结构 CREATE TABLE `admin` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `c ...
- EF Core 相关的千倍性能之差: AutoMapper ProjectTo VS Mapster ProjectToType
在前两天遇到 .NET Core 中 EF Core 的异步与同步查询的百倍性能之差(详情之前的博文)之后,这两天又遇到了 AutoMapper ProjectTo<T> 与 Mapste ...
- robotframework RF使用中需要安装的工具和库
确保 Python 3.6.2 安装成功 安装 如下 RF使用中需要的工具和库 1. RF 在两个Python中安装 robotframework执行命令 pip install robotframe ...
- webservice学习教程(一):理论
一. WebService到底是什么? webservice是一种跨平台,跨语言的规范,用于不同平台,不同语言开发的应用之间的交互 WebService是一个SOA(面向服务的编程)的架构,它是不依赖 ...
- fastJson解析报错:com.alibaba.fastjson.JSONException: can't create non-static inner class instance.
原因: 如果出现类嵌套类的情况,需要将被嵌套的那个类设置为static. 比如: public class AA { // 相关属性 public class BB {//会报错 // 相关属性 } ...
- vue中$refs、$slot、$nextTick相关的语法
Vue 实例还暴露了一些有用的实例属性与方法.它们都有前缀 $,以便与用户定义的属性区分开来 1.$data和$el var data = { a: 1 } var vm = new Vue({ el ...