hadoop集群安装_实战
spark1.6.2+ hadoop2.6.2
词频统计完整案例:http://blog.csdn.net/zythy/article/details/17852579
hadoop学习:http://www.cnblogs.com/admln/category/618480.html
hadoop提交作业:http://weixiaolu.iteye.com/blog/1402919
所以,如果要永久修改RedHat的hostname,就修改/etc/sysconfig/network文件,将里面的HOSTNAME这一行修改成HOSTNAME=NEWNAME,其中NEWNAME就是你要设置的hostname。
1.机器准备:
关闭防火墙:
service iptables stop
service iptables status
10.112.29.177 vm-10-112-29-177 namenode
10.112.29.172 vm-10-112-29-172 datanode
10.112.29.174 vm-10-112-29-174 datanode
2.无密码登录:
生成master公钥:
- cd ~/.ssh (进入用户目录下的隐藏文件.ssh)
- ssh-keygen -t rsa (用rsa生成密钥)
- cp id_rsa.pub authorized_keys (把公钥复制一份,并改名为authorized_keys,这步执行完,应该ssh localhost可以无密码登录本机了,可能第一次要密码)
- scp authorized_key root@vm-10-112-29-172:~/.ssh (把重命名后的公钥通过ssh提供的远程复制文件复制到从机vm-10-112-29-172上面)
- chmod 600 authorized_keys (更改公钥的权限,也需要在从机vm-10-112-29-172中执行同样代码)
- ssh vm-10-112-29-172 (可以远程无密码登录vm-10-112-29-172这台机子了,注意是ssh不是sudo ssh。第一次需要密码,以后不再需要密码)
方法2:
cat id_rsa.pub >> authorized_keys
scp root@master:~/.ssh/id_dsa.pub ~/.ssh/master_dsa.pub
cat~/.ssh/master_dsa.pub >> ~/.ssh/authorized_keys

3.安装目录下创建数据存放的文件夹,tmp、hdfs、hdfs/data、hdfs/name
4.
修改/usr/bigdata/hadoop-2.7.1/etc/hadoop下的配置文件
修改core-site.xml,加上
<property>
<name>fs.defaultFS</name>
<value>hdfs://vm-10-112-29-177:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/bigdata/hadoop-2.7.1/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
5.修改hdfs-site.xml,加上
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/bigdata/hadoop-2.7.1/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/bigdata/hadoop-2.7.1/hdfs/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>vm-10-112-29-177:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
6.修改mapred-site.xml,加上
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>vm-10-112-29-177:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>vm-10-112-29-177:19888</value>
</property>
7.修改yarn-site.xml,加上
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>vm-10-112-29-177:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>vm-10-112-29-177:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>vm-10-112-29-177:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>vm-10-112-29-177:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>vm-10-112-29-177:8088</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
</property>
注意:2048,2 设置过小,nodemanager启动失败 或者log中显示无法分配必要的资源 提交作业有可能一直 accpeted状态
8.
配置/user/bigdata/hadoop-2.7.1/etc/hadoop目录下hadoop-env.sh、yarn-env.sh的JAVA_HOME,否则启动时会报error
export JAVA_HOME=/usr/java/jdk1.7.0_80
9.
配置/user/bigdata/hadoop-2.7.1/etc/hadoop目录下slaves
加上你的从服务器,
vm-10-112-29-172
vm-10-112-29-174
配置成功后,将hadhoop复制到各个从服务器上
scp -r /user/bigdata/hadoop-2.7.1 root@vm-10-112-29-172:/user/bigdata/
scp -r /user/bigdata/hadoop-2.7.1 root@vm-10-112-29-174:/user/bigdata/
scp /usr/bigdata/hadoop-2.6.2/etc/hadoop/yarn-site.xml root@vm-10-112-29-174:/usr/bigdata/hadoop-2.6.2/etc/hadoop
10.
主服务器上执行bin/hdfs namenode -format
进行初始化
sbin目录下执行 ./start-all.sh
可以使用jps查看信息
停止的话,输入命令,sbin/stop-all.sh
11.
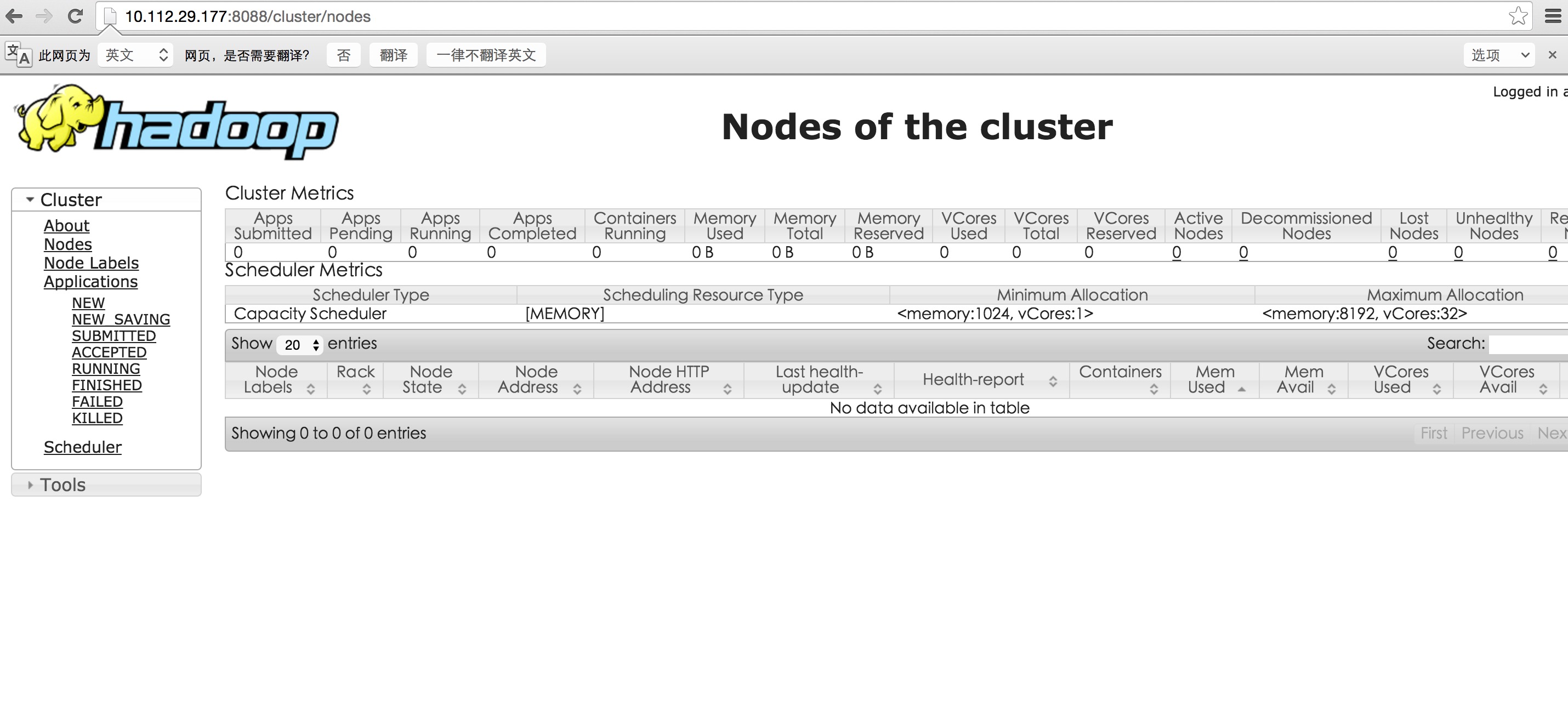
这时可以浏览器打开10.112.29.177:8088查看集群信息啦
到此配置就成功啦,开始你的大数据旅程吧。。。
解决nodemanager 启动问题以后:

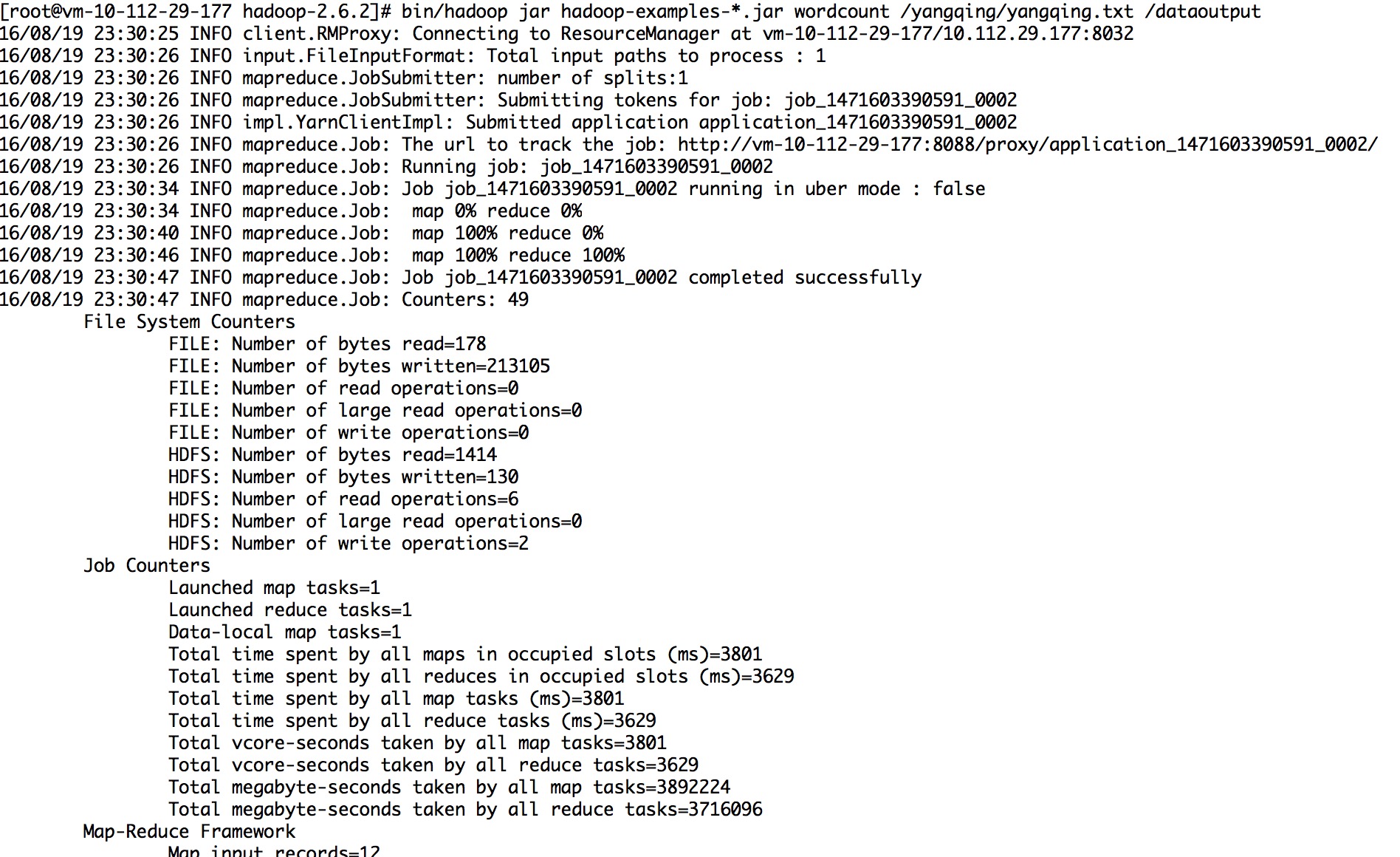
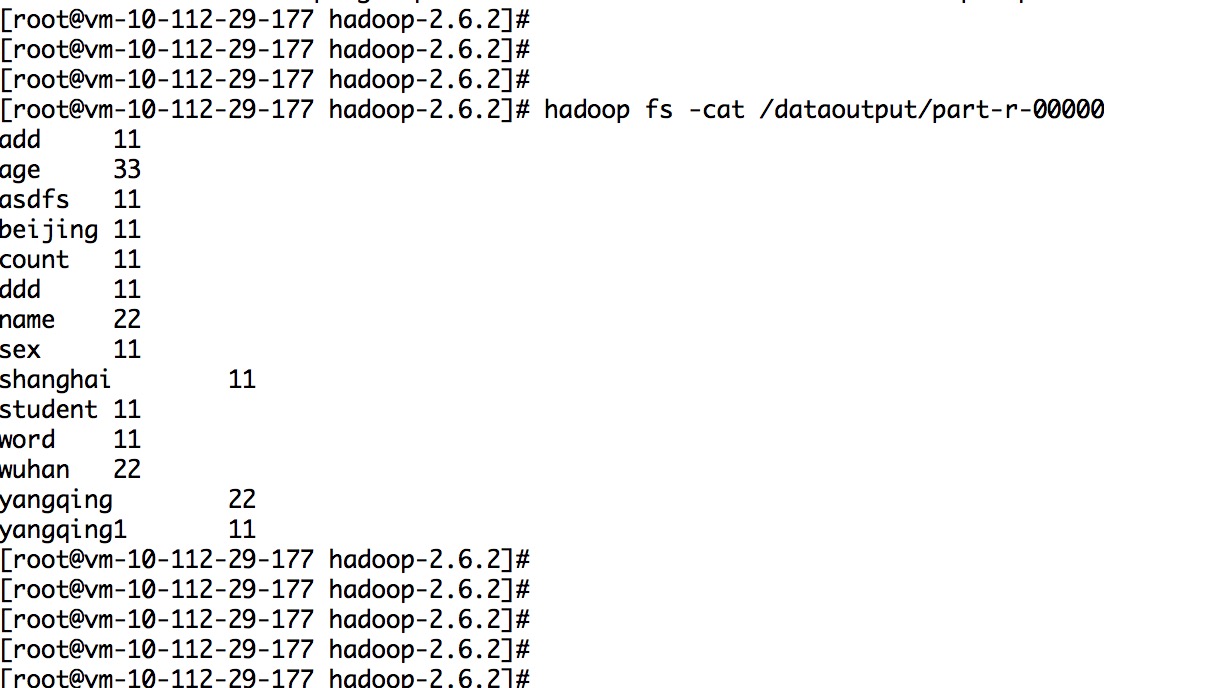
10.实例代码:
http://blog.csdn.net/ylchou/article/details/9264899
sh bin/hadoop fs -mkdir /tttt bin/hadoop fs -put /root/test/tttt.txt /tttt scp -r /usr/bigdata/hadoop-2.6.2 root@vm-10-112-29-174:/usr/bigdata/
hadoop集群安装_实战的更多相关文章
- Apache Hadoop 集群安装文档
简介: Apache Hadoop 集群安装文档 软件:jdk-8u111-linux-x64.rpm.hadoop-2.8.0.tar.gz http://www.apache.org/dyn/cl ...
- 1.Hadoop集群安装部署
Hadoop集群安装部署 1.介绍 (1)架构模型 (2)使用工具 VMWARE cenos7 Xshell Xftp jdk-8u91-linux-x64.rpm hadoop-2.7.3.tar. ...
- Apache Hadoop集群安装(NameNode HA + SPARK + 机架感知)
1.主机规划 序号 主机名 IP地址 角色 1 nn-1 192.168.9.21 NameNode.mr-jobhistory.zookeeper.JournalNode 2 nn-2 ).HA的集 ...
- Apache Hadoop集群安装(NameNode HA + YARN HA + SPARK + 机架感知)
1.主机规划 序号 主机名 IP地址 角色 1 nn-1 192.168.9.21 NameNode.mr-jobhistory.zookeeper.JournalNode 2 nn-2 192.16 ...
- 2 Hadoop集群安装部署准备
2 Hadoop集群安装部署准备 集群安装前需要考虑的几点硬件选型--CPU.内存.磁盘.网卡等--什么配置?需要多少? 网络规划--1 GB? 10 GB?--网络拓扑? 操作系统选型及基础环境-- ...
- Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS
摘自:http://www.powerxing.com/install-hadoop-cluster/ 本教程讲述如何配置 Hadoop 集群,默认读者已经掌握了 Hadoop 的单机伪分布式配置,否 ...
- hadoop集群安装故障解决
nodemanager进程解决:http://blog.csdn.net/baiyangfu_love/article/details/13504849 编译安装:http://blog.csdn.n ...
- linux hadoop 集群安装步骤
http://blog.csdn.net/xjavasunjava/article/details/12013677 1,时间同步hadoop集群的每台机器的时间不能相差太大. 安装集群前最好进行一下 ...
- hadoop集群安装
首现非常感谢 虾皮(http://www.cnblogs.com/xia520pi/archive/2012/05/16/2503949.html) 安装过程是参照他的<Hadoop集群(第5期 ...
随机推荐
- makefile之变量赋值
makefile中变量赋值有4种方法: = , := , += , ?= = :直接赋值 变量 = 值 := :位置相关赋值 如果右值为一个值,那么它和=没区别,如果右值为变量,那么左边变 ...
- JS入门学习,编写一个简易月历
//今天最头疼的地方在于 getElementsByClassName()的 [] ~~ //错了N遍后只能说有点点头绪,如果不加[] 查找的就是全部吧 加上[]能精确控制的标签或者class < ...
- BZOJ 2038: [2009国家集训队]小Z的袜子(hose) [莫队算法]【学习笔记】
2038: [2009国家集训队]小Z的袜子(hose) Time Limit: 20 Sec Memory Limit: 259 MBSubmit: 7687 Solved: 3516[Subm ...
- SPOJ GSS3 Can you answer these queries III[线段树]
SPOJ - GSS3 Can you answer these queries III Description You are given a sequence A of N (N <= 50 ...
- 服务器504——一般情况下是由nginx默认的fastcgi进程响应慢引起的
情况一解决办法: 默认的fastcgi进程响应的缓冲区是8K,我们可以设置大一点,在nginx.conf里,加入:fastcgi_buffers 8 128k 这表示设置fastcgi缓冲区为8块12 ...
- 让 http 2来得更猛烈些吧
今早在公交车上,把http2的官方讲解文档(还在草案之中)看了一圈,发现相对http 1.1确实改进了不少,完整的文档可通过:://www.gitbook.com/book/ye11ow/http2- ...
- jQuery EasyUI视频教程合集
下载地址:http://www.fu83.cn/thread-269-1-1.html 教程内容: 尚学堂科技_jqueryeasyui视频教程_白贺翔 李炎恢jQuery EasyUI视频教程全集 ...
- 通过COOKIE欺骗登录网站后台
1.今天闲着没事看了看关于XSS(跨站脚本攻击)和CSRF(跨站请求伪造)的知识,xss表示Cross Site Scripting(跨站脚本攻击),它与SQL注入攻击类似,SQL注入攻击中以SQL语 ...
- 转载(sublime text 2 调试python时结果空白)
sublime text 2 调试python时结果空白 之前用的时候都一切正常,今天突然就出现了这个问题.按ctrl+b执行的时候结果只有空白,查了很多文章都只提到了中文路径.系统路径等等,没有解决 ...
- Windows phone应用开发[21]-图片性能优化
在windows phone 中常在列表中会常包含比较丰富文字和图片混排数据信息. 针对列表数据中除了谈到listbox等控件自身数据虚拟化问题外.虽然wp硬件设备随着SDK 8.0 发布得到应用可使 ...