hadoop集群安装_实战
spark1.6.2+ hadoop2.6.2
词频统计完整案例:http://blog.csdn.net/zythy/article/details/17852579
hadoop学习:http://www.cnblogs.com/admln/category/618480.html
hadoop提交作业:http://weixiaolu.iteye.com/blog/1402919
所以,如果要永久修改RedHat的hostname,就修改/etc/sysconfig/network文件,将里面的HOSTNAME这一行修改成HOSTNAME=NEWNAME,其中NEWNAME就是你要设置的hostname。
1.机器准备:
关闭防火墙:
service iptables stop
service iptables status
10.112.29.177 vm-10-112-29-177 namenode
10.112.29.172 vm-10-112-29-172 datanode
10.112.29.174 vm-10-112-29-174 datanode
2.无密码登录:
生成master公钥:
- cd ~/.ssh (进入用户目录下的隐藏文件.ssh)
- ssh-keygen -t rsa (用rsa生成密钥)
- cp id_rsa.pub authorized_keys (把公钥复制一份,并改名为authorized_keys,这步执行完,应该ssh localhost可以无密码登录本机了,可能第一次要密码)
- scp authorized_key root@vm-10-112-29-172:~/.ssh (把重命名后的公钥通过ssh提供的远程复制文件复制到从机vm-10-112-29-172上面)
- chmod 600 authorized_keys (更改公钥的权限,也需要在从机vm-10-112-29-172中执行同样代码)
- ssh vm-10-112-29-172 (可以远程无密码登录vm-10-112-29-172这台机子了,注意是ssh不是sudo ssh。第一次需要密码,以后不再需要密码)
方法2:
cat id_rsa.pub >> authorized_keys
scp root@master:~/.ssh/id_dsa.pub ~/.ssh/master_dsa.pub
cat~/.ssh/master_dsa.pub >> ~/.ssh/authorized_keys

3.安装目录下创建数据存放的文件夹,tmp、hdfs、hdfs/data、hdfs/name
4.
修改/usr/bigdata/hadoop-2.7.1/etc/hadoop下的配置文件
修改core-site.xml,加上
<property>
<name>fs.defaultFS</name>
<value>hdfs://vm-10-112-29-177:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/bigdata/hadoop-2.7.1/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
5.修改hdfs-site.xml,加上
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/bigdata/hadoop-2.7.1/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/bigdata/hadoop-2.7.1/hdfs/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>vm-10-112-29-177:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
6.修改mapred-site.xml,加上
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>vm-10-112-29-177:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>vm-10-112-29-177:19888</value>
</property>
7.修改yarn-site.xml,加上
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>vm-10-112-29-177:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>vm-10-112-29-177:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>vm-10-112-29-177:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>vm-10-112-29-177:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>vm-10-112-29-177:8088</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
</property>
注意:2048,2 设置过小,nodemanager启动失败 或者log中显示无法分配必要的资源 提交作业有可能一直 accpeted状态
8.
配置/user/bigdata/hadoop-2.7.1/etc/hadoop目录下hadoop-env.sh、yarn-env.sh的JAVA_HOME,否则启动时会报error
export JAVA_HOME=/usr/java/jdk1.7.0_80
9.
配置/user/bigdata/hadoop-2.7.1/etc/hadoop目录下slaves
加上你的从服务器,
vm-10-112-29-172
vm-10-112-29-174
配置成功后,将hadhoop复制到各个从服务器上
scp -r /user/bigdata/hadoop-2.7.1 root@vm-10-112-29-172:/user/bigdata/
scp -r /user/bigdata/hadoop-2.7.1 root@vm-10-112-29-174:/user/bigdata/
scp /usr/bigdata/hadoop-2.6.2/etc/hadoop/yarn-site.xml root@vm-10-112-29-174:/usr/bigdata/hadoop-2.6.2/etc/hadoop
10.
主服务器上执行bin/hdfs namenode -format
进行初始化
sbin目录下执行 ./start-all.sh
可以使用jps查看信息
停止的话,输入命令,sbin/stop-all.sh
11.
这时可以浏览器打开10.112.29.177:8088查看集群信息啦
到此配置就成功啦,开始你的大数据旅程吧。。。
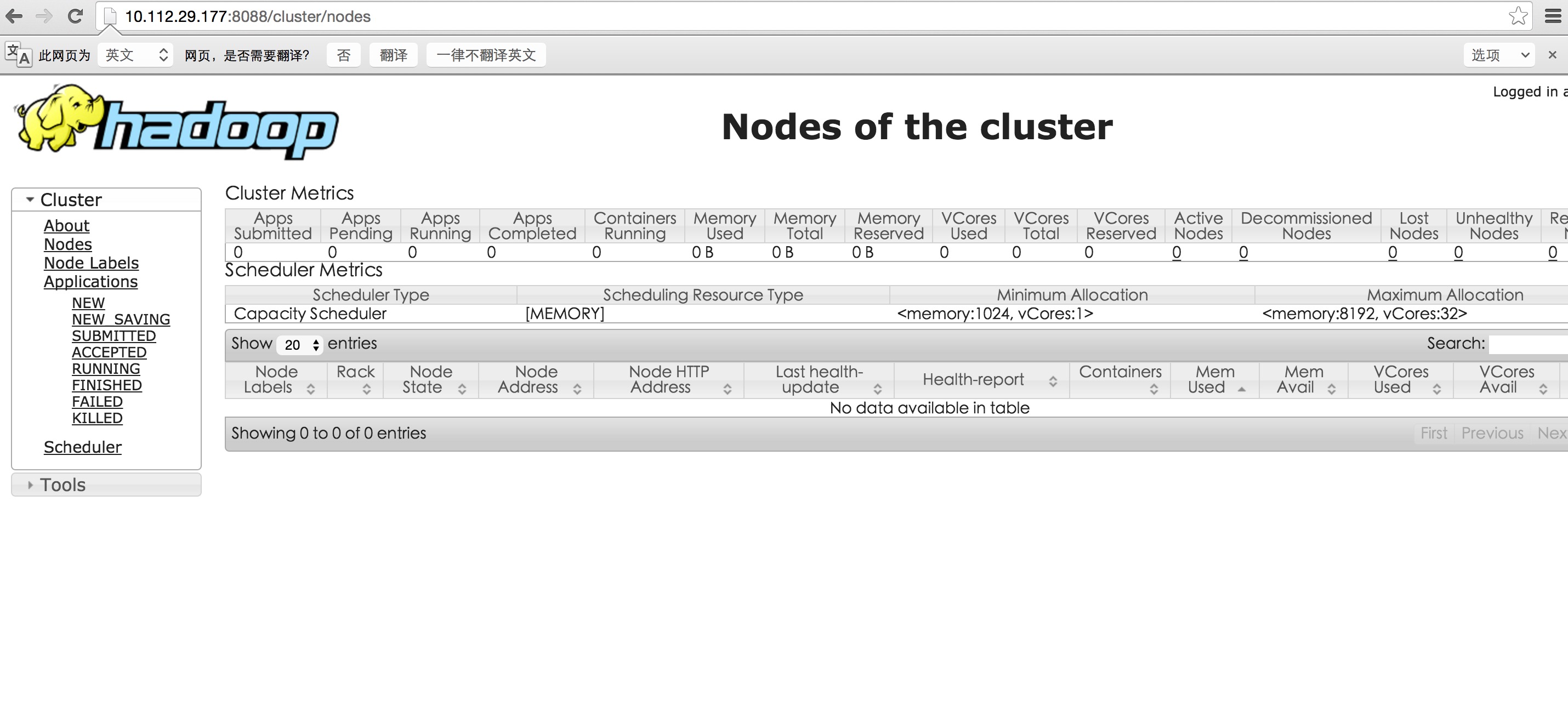
解决nodemanager 启动问题以后:

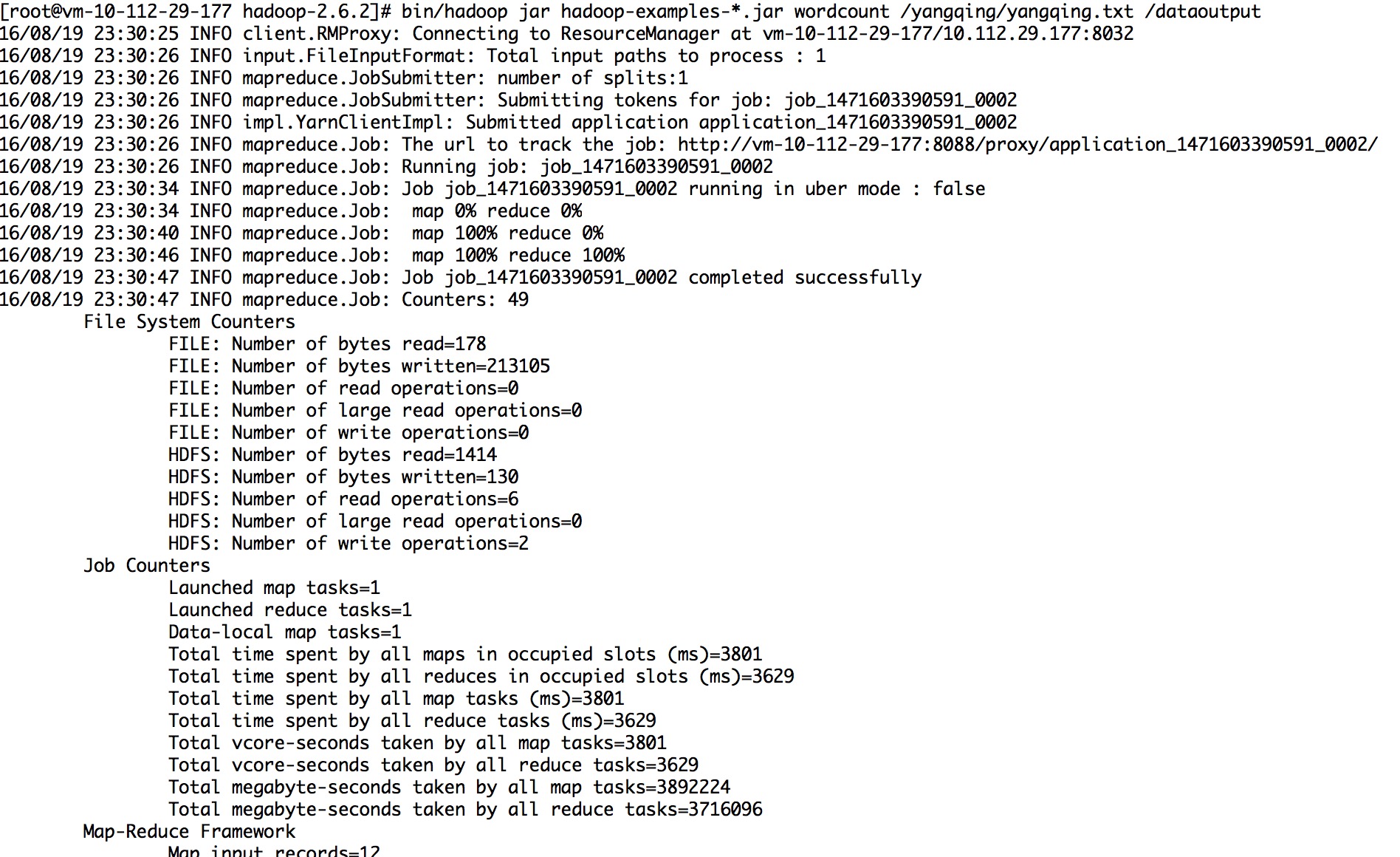
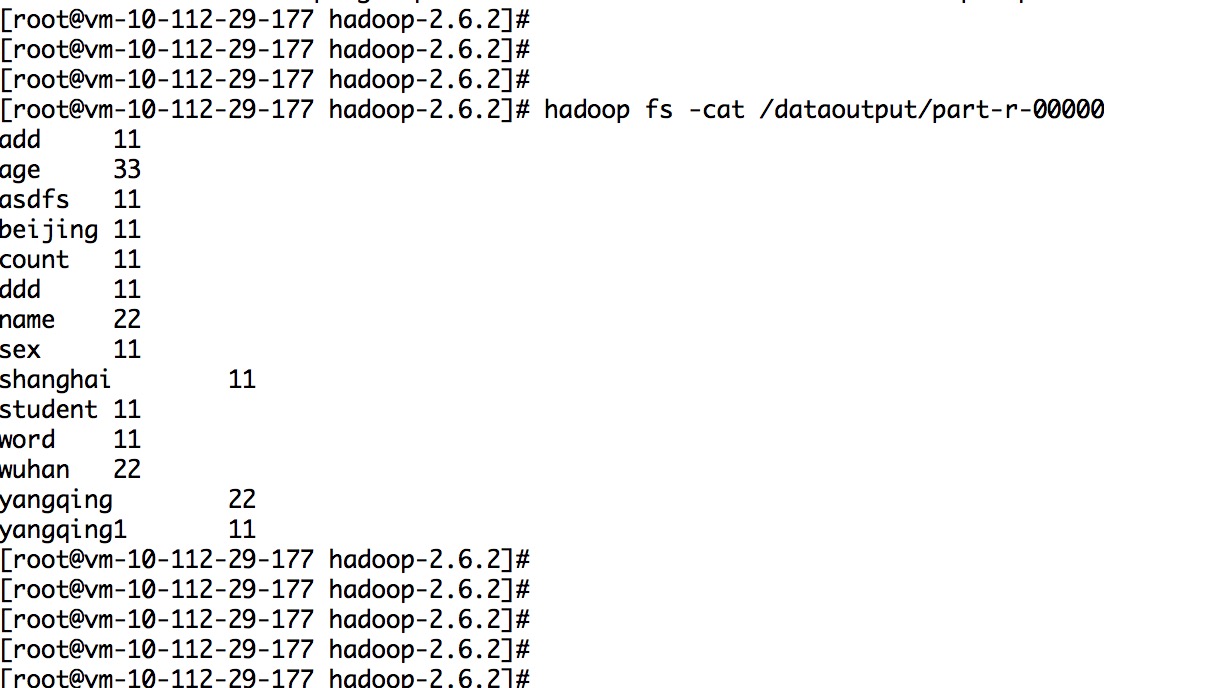
10.实例代码:
http://blog.csdn.net/ylchou/article/details/9264899
sh bin/hadoop fs -mkdir /tttt bin/hadoop fs -put /root/test/tttt.txt /tttt scp -r /usr/bigdata/hadoop-2.6.2 root@vm-10-112-29-174:/usr/bigdata/
hadoop集群安装_实战的更多相关文章
- Apache Hadoop 集群安装文档
简介: Apache Hadoop 集群安装文档 软件:jdk-8u111-linux-x64.rpm.hadoop-2.8.0.tar.gz http://www.apache.org/dyn/cl ...
- 1.Hadoop集群安装部署
Hadoop集群安装部署 1.介绍 (1)架构模型 (2)使用工具 VMWARE cenos7 Xshell Xftp jdk-8u91-linux-x64.rpm hadoop-2.7.3.tar. ...
- Apache Hadoop集群安装(NameNode HA + SPARK + 机架感知)
1.主机规划 序号 主机名 IP地址 角色 1 nn-1 192.168.9.21 NameNode.mr-jobhistory.zookeeper.JournalNode 2 nn-2 ).HA的集 ...
- Apache Hadoop集群安装(NameNode HA + YARN HA + SPARK + 机架感知)
1.主机规划 序号 主机名 IP地址 角色 1 nn-1 192.168.9.21 NameNode.mr-jobhistory.zookeeper.JournalNode 2 nn-2 192.16 ...
- 2 Hadoop集群安装部署准备
2 Hadoop集群安装部署准备 集群安装前需要考虑的几点硬件选型--CPU.内存.磁盘.网卡等--什么配置?需要多少? 网络规划--1 GB? 10 GB?--网络拓扑? 操作系统选型及基础环境-- ...
- Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS
摘自:http://www.powerxing.com/install-hadoop-cluster/ 本教程讲述如何配置 Hadoop 集群,默认读者已经掌握了 Hadoop 的单机伪分布式配置,否 ...
- hadoop集群安装故障解决
nodemanager进程解决:http://blog.csdn.net/baiyangfu_love/article/details/13504849 编译安装:http://blog.csdn.n ...
- linux hadoop 集群安装步骤
http://blog.csdn.net/xjavasunjava/article/details/12013677 1,时间同步hadoop集群的每台机器的时间不能相差太大. 安装集群前最好进行一下 ...
- hadoop集群安装
首现非常感谢 虾皮(http://www.cnblogs.com/xia520pi/archive/2012/05/16/2503949.html) 安装过程是参照他的<Hadoop集群(第5期 ...
随机推荐
- [django]django xlrd处理xls中日期转换问题
xlrd会把xls文件中比如20160--03-01类型的时间转换成整数,那么我们如何保证xlrd读取进来的时间为2016-03-01格式呢? 使用xlrd中的xldate_as_tuple函数 代码 ...
- 报表软件FineReport如何连接SAP HANA
1. 环境搭建 1.1 环境准备 首先确认HANA Studio的环境是否允许工程进行NewFile的操作,不行的话要考虑更新Studio的版本. HANAStudio需要依赖Java jdk1.6或 ...
- PhotoShop算法原理解析系列 - 风格化---》查找边缘。
之所以不写系列文章一.系列文章二这样的标题,是因为我不知道我能坚持多久.我知道我对事情的表达能力和语言的丰富性方面的天赋不高.而一段代码需要我去用心的把他从基本原理-->初步实现-->优化 ...
- 如何用ZBrush快速绘制身体
Fisker老师用了5节课详细讲解了僵尸的头部制作过程,用了大量时间完善细节部分,在ZBrush3D图形绘制软件中雕刻模型就是这样,需要反复调整与修改,每一个细节都做到极致才是最理想的状态.头部雕刻好 ...
- LeetCode Single Number I / II / III
[1]LeetCode 136 Single Number 题意:奇数个数,其中除了一个数只出现一次外,其他数都是成对出现,比如1,2,2,3,3...,求出该单个数. 解法:容易想到异或的性质,两个 ...
- WebService基本使用
不使用任何框架,纯粹使用JDK开发一个服务端与客户端 服务端 package org.zln.ws.server;import org.slf4j.Logger;import org.slf4j.Lo ...
- java多线程系类:JUC原子类:04之AtomicReference原子类
概要 本章对AtomicReference引用类型的原子类进行介绍.内容包括:AtomicReference介绍和函数列表AtomicReference源码分析(基于JDK1.7.0_40)Atomi ...
- C#.NET 大型企业信息化系统集成快速开发平台 4.2 版本 - 访问频率限制功能实现、防止黑客扫描、防止恶意刷屏
很多软件组件,大家都能想到了,大家也能做出来,但是成熟稳定.可靠.易用.功能全面,可信任,可相信,可开源就不是很容易,需要树立良好的口碑才可以. 1:往往会有黑客,进行撞库挖掘漏洞,很多系统的账户有可 ...
- LeetCode-9-Palindrome Number
Determine whether an integer is a palindrome. Do this without extra space. 判断一个整数是否是回文数. 思路:求出数字abcd ...
- 更好的pip工作流
转自:http://codingpy.com/article/a-better-pip-workflow-recommended-by-kenneth/ 现在大家开发Python应用时,在代码库的根目 ...