elasticsearch映射及分析-----3
首先我们看下不同的索引方式相同的字段指定字段类型与不指定字段类型es会怎么处理
1、不指定类型,直接创建索引及类型文档

我们看下他默认的索引映射

2、创建索引和类型时指定字段类型

这里创建了一个索引为index2类型为manager的索引并指定了数据类型
查看es的索引方式

这里我们也可以指定索引类型(准确说应该是索引模式)

上图中,索引index3,类型emplyee中age字段的索引模式为not_analyzed,而那么字段为analyzed,其中还有一种我们未使用的,三者有何区别见下图:

具体什么意思呢?
analyzed表示,如我们有个文档为:Obama is a good man,分析后为全小写的但个单词(term)分析后的内容为:obama,is,a,good,man (逗号是我加上的,以便于区分,实际分析后的是没有的)。
not_analyzed表示会被索引,也就是可以被搜索到,但是不会去分析,原文怎么样索引后就是怎么样,所以Obama is a good man这句话不会做任何改变,证据完整的被索引。
no表示既不索引也不会被分析,我们是搜不到的。
3、分析器
分析器的作用:
我们保存一个文档,比如一句话"I have a dream",保存的时候es会采用默认分析器分析这段话,这段话将拆成i,have,a,dream,如果其中有大写会自动转换成小写。
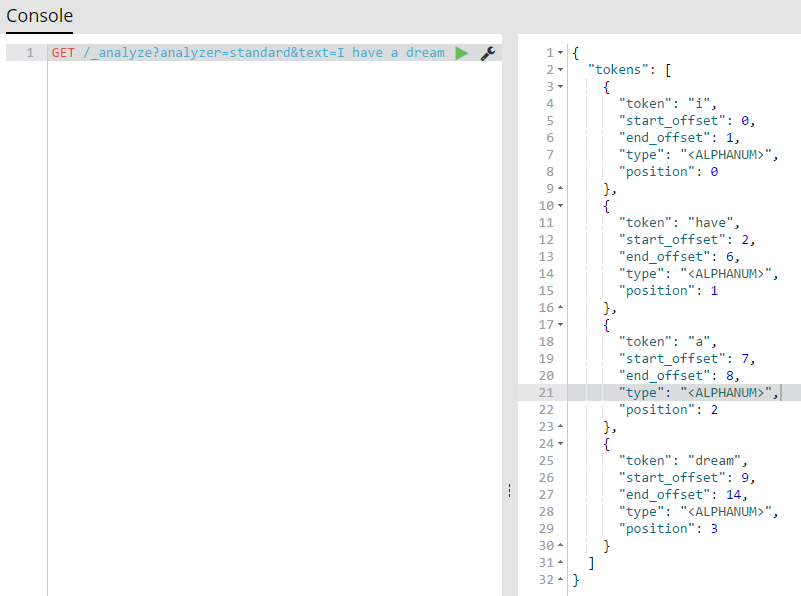
token 是一个实际被存储在索引中的词。 position 指明词在原文本中是第几个出现的。 start_offset 和 end_offset 表示词
在原文本中占据的位置(来自es指南)。
4、自定义分析器

这里我们定义hostname字段类型为string,分析器为english.
5、更新映射
更新映射指的是往索引某类型中添加字段,而不是对某个字段做修改,因为该字段已经有值且已利用之前的分析器做分析,如果修改属性之前的分析结果全部出错,所以不允许对已有字段做索引更新。
我们之前采用手动映射到方式创建了一个index3的索引employee的类型,name字段没有指定分析器类型,我们现在对这个映射做下修改,指定name字段的分析其为english:,es提示不允许:

我们尝试往索引index3类型employee类型中更新映射新增一个字段tag,这样是允许的(只需添加新字段的映射,索引中原来的字段不需要列出会自动合并):

好了,我们往该索引中添加数据试试:

我们看下这条数据:

6、创建复杂索引(嵌套索引)

这里每一个嵌套层都会被当成一个object对象,然后再指定字段属性。
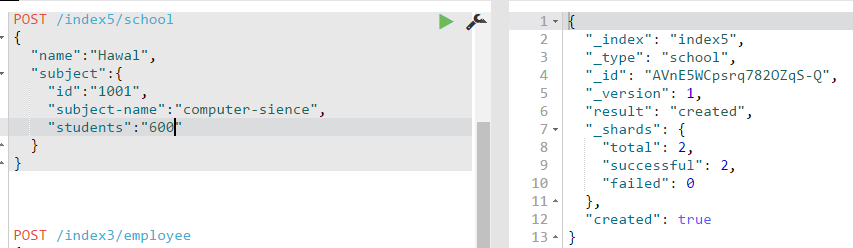

最终数据存储的json结构:

elasticsearch映射及分析-----3的更多相关文章
- ElasticSearch 5学习(9)——映射和分析(string类型废弃)
在ElasticSearch中,存入文档的内容类似于传统数据每个字段一样,都会有一个指定的属性,为了能够把日期字段处理成日期,把数字字段处理成数字,把字符串字段处理成字符串值,Elasticsearc ...
- ElasticSearch权威指南学习(映射和分析)
概念 映射(mapping)机制用于进行字段类型确认,将每个字段匹配为一种确定的数据类型(string, number, booleans, date等).+ 分析(analysis)机制用于进行全文 ...
- fluentd结合kibana、elasticsearch实时搜索分析hadoop集群日志<转>
转自 http://blog.csdn.net/jiedushi/article/details/12003171 Fluentd是一个开源收集事件和日志系统,它目前提供150+扩展插件让你存储大数据 ...
- Elasticsearch源码分析 - 源码构建
原文地址:https://mp.weixin.qq.com/s?__biz=MzU2Njg5Nzk0NQ==&mid=2247483694&idx=1&sn=bd03afe5a ...
- Elasticsearch tshark 封包分析 (转)
Elasticsearch tshark 封包分析 使用wireshark能解決許多網路問題,將側錄下來的封包傳至Elasticsearch上方便分析製作及時報表.tshark為wireshark的命 ...
- Elasticsearch源码分析—线程池(十一) ——就是从队列里处理请求
Elasticsearch源码分析—线程池(十一) 转自:https://www.felayman.com/articles/2017/11/10/1510291570687.html 线程池 每个节 ...
- elasticsearch源码分析之search模块(server端)
elasticsearch源码分析之search模块(server端) 继续接着上一篇的来说啊,当client端将search的请求发送到某一个node之后,剩下的事情就是server端来处理了,具体 ...
- elasticsearch源码分析之search模块(client端)
elasticsearch源码分析之search模块(client端) 注意,我这里所说的都是通过rest api来做的搜索,所以对于接收到请求的节点,我姑且将之称之为client端,其主要的功能我们 ...
- elasticsearch(6) 映射和分析
类似关系型数据库中每个字段都有对应的数据类型,例如nvarchar.int.date等等,elasticsearch也会将文档中的字段映射成对应的数据类型,这一映射可以使ES自动生成的,也是可以由我们 ...
随机推荐
- c语言参考书籍
很惭愧没能把c++学的很好,毕竟离开始工作只有2年时间,对自己要求不要过高,慢慢来吧.话说知道自己的不足,以后要更加抓紧了!fighting~ 现在计划着把c语言给学习一下了,当然这次指的是深入地学习 ...
- loj #2254. 「SNOI2017」一个简单的询问
#2254. 「SNOI2017」一个简单的询问 题目描述 给你一个长度为 NNN 的序列 aia_iai,1≤i≤N1\leq i\leq N1≤i≤N,和 qqq 组询问,每组询问读入 l1 ...
- bzoj3140: [Hnoi2013]消毒(二分图)
题目描述 最近在生物实验室工作的小T遇到了大麻烦. 由于实验室最近升级的缘故,他的分格实验皿是一个长方体,其尺寸为a*b*c,a.b.c 均为正整数.为了实验的方便,它被划分为a*b*c个单位立方体区 ...
- python web框架之Tornado的简单使用
python web框架有很多,比如常用的有django,flask等.今天主要介绍Tornado ,Tornado是一个用Python写的相对简单的.不设障碍的Web服务器架构,用以处理上万的同时的 ...
- 2019.2.26考试T2 矩阵快速幂加速DP
\(\color{#0066ff}{题解 }\) 可以发现, 数据范围中的n特别小,容易想到状压 可以想到类似于状压DP的思路,按列进行转移 那么应该有3维,\(f[i][j][k]\)代表到第i列, ...
- js按回车事件提交
$(document).keyup(function (event) { if (event.keyCode == "13") { document.getElementById( ...
- 复习一知识点:回调函数callback
比如我们常用的异步请求: $.ajax({ url:"test.json", type: "GET", data: {username:$("#use ...
- Django-redis 缓存
存在内存中 Diango-redis redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集 ...
- LeeCode(No3 - Longest Substring Without Repeating Characters)
题目: Given a string, find the length of the longest substring without repeating characters. 示例: Given ...
- Spring Cloud 监控相关
因为最近客户提出想监控Spring Cloud运行状况的需求,所以稍稍做了调研.目前了解的方法如下: Eureka Server启动后可以在根目录路径看到所有注册的Eureka Client状况 各个 ...