scrapy--cnblogs
之前一直在学习关于滑块验证码的爬虫知识,最接近的当属于模拟人的行为进行鼠标移动,登录页面之后在获取了,由于一直找不到滑块验证码的原图,无法通过openCV获取当前滑块所需要移动的距离。
1.机智如我开始找关系通过截取滑块图片,然后经过PS,再进行比较(就差最后的验证了) 2.Selenium+Scrapy:登录部分--自己操作鼠标通过验证,登录之后页面--爬取静态页面
给大家讲了答题思路,现在就来拿实例验证一下可行性,拿自己博客开刀--"https://i.cnblogs.com"
二、先给大家看下效果,我不坑人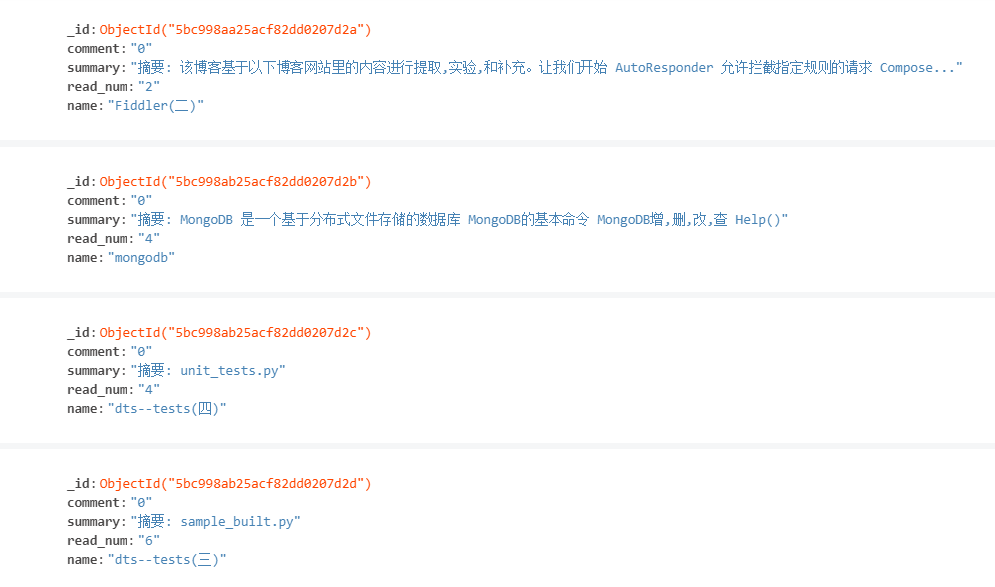
一、配置代码
1.1_items.py
import scrapy class BokeItem(scrapy.Item):
name = scrapy.Field()
summary = scrapy.Field()
read_num = scrapy.Field()
comment = scrapy.Field()
1.2_middlewares.py(设置代理)
class BokeSpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
def __init__(self,ip=''):
self.ip = ip
def process_request(self,request,spider):
print('http://10.240.252.16:911')
request.meta['proxy']= 'http://10.240.252.16:911'
1.3_pipelines.py(存储mongodb)
import scrapy
import pymongo
from scrapy.item import Item class BokePipeline(object):
def process_item(self, item, spider):
return item class MongoDBPipeline(object): #存储到mongodb中
@classmethod
def from_crawler(cls,crawler):
cls.DB_URL = crawler.settings.get("MONGO_DB_URL",'mongodb://localhost:27017/')
cls.DB_NAME = crawler.settings.get("MONGO_DB_NAME",'scrapy_data')
return cls() def open_spider(self,spider):
self.client = pymongo.MongoClient(self.DB_URL)
self.db = self.client[self.DB_NAME] def close_spider(self,spider):
self.client.close() def process_item(self,item,spider):
collection = self.db[spider.name]
post = dict(item) if isinstance(item,Item) else item
collection.insert(post) return item
1.4_settings.py(重要设置)
import random BOT_NAME = 'Boke' SPIDER_MODULES = ['Boke.spiders']
NEWSPIDER_MODULE = 'Boke.spiders' MONGO_DB_URL = 'mongodb://localhost:27017/'
MONGO_DB_NAME = 'myboke' USER_AGENT =[ #设置浏览器的User_agent
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
] FEED_EXPORT_FIELDS = ['name','summary','read_num','comment'] ROBOTSTXT_OBEY = False
CONCURRENT_REQUESTS = 10
DOWNLOAD_DELAY = 0.5
COOKIES_ENABLED = False
# Crawled (400) <GET https://www.cnblogs.com/eilinge/> (referer: None)
DEFAULT_REQUEST_HEADERS = { 'User-Agent': random.choice(USER_AGENT), 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', } DOWNLOADER_MIDDLEWARES = {
#'Boss.middlewares.BossDownloaderMiddleware': 543,
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware':543,
'Boke.middlewares.BokeSpiderMiddleware':123, } ITEM_PIPELINES = {
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware':1,
'Boke.pipelines.MongoDBPipeline': 300, }
1.5_spiders/boke.py
#-*- coding:utf-8 -*-
import time
from selenium import webdriver
import pdb
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
from lxml import etree
import re
from bs4 import BeautifulSoup
import scrapy
from Boke.items import BokeItem
from Boke.settings import USER_AGENT
from scrapy.linkextractors import LinkExtractor
import random
import re chrome_options = Options()
driver = webdriver.Chrome() class BokeSpider(scrapy.Spider):
name = 'boke'
allowed_domains = ['www.cnblogs.com','passport.cnblogs.com']
start_urls = ['https://passport.cnblogs.com/user/signin'] def start_requests(self): driver.get(
self.start_urls[0]
)
time.sleep(3)
driver.find_element_by_id('input1').send_keys(u'xxx')
time.sleep(3)
driver.find_element_by_id('input2').send_keys(u'xxx')
time.sleep(3)
driver.find_element_by_id('signin').click()
time.sleep(20) new_url = driver.current_url.encode('utf8')
print(driver.current_url.encode('utf8')) yield scrapy.Request(new_url) def parse(self, response): bokeitem = BokeItem()
sels = response.css('div.day')
for sel in sels:
bokeitem['name'] = sel.css('div.postTitle>a ::text').extract()[0]
bokeitem['summary'] = sel.css('div.c_b_p_desc ::text').extract()[0]
summary = sel.css('div.postDesc ::text').extract()[0]
bokeitem['read_num'] = re.findall(r'\((\d{0,5})',summary)[0]
bokeitem['comment'] = re.findall(r'\((\d{0,5})', summary)[1] print bokeitem
yield bokeitem
scrapy--cnblogs的更多相关文章
- scrapy爬取cnblogs文章列表
scrapy爬取cnblogs文章 目标任务 安装爬虫 创建爬虫 编写 items.py 编写 spiders/cnblogs.py 编写 pipelines.py 编写 settings.py 运行 ...
- cnblogs 博客爬取 + scrapy + 持久化 + 分布式
目录 普通 scrapy 分布式爬取 cnblogs_spider.py 普通 scrapy # -*- coding: utf-8 -*- import scrapy from ..items im ...
- scrapy架构与目录介绍、scrapy解析数据、配置相关、全站爬取cnblogs数据、存储数据、爬虫中间件、加代理、加header、集成selenium
今日内容概要 scrapy架构和目录介绍 scrapy解析数据 setting中相关配置 全站爬取cnblgos文章 存储数据 爬虫中间件和下载中间件 加代理,加header,集成selenium 内 ...
- python3 安装scrapy
twisted(网络异步框架) wget https://pypi.python.org/packages/dc/c0/a0114a6d7fa211c0904b0de931e8cafb5210ad82 ...
- scrapy爬虫结果插入mysql数据库
1.通过工具创建数据库scrapy
- Scrapy爬取自己的博客内容
python中常用的写爬虫的库有urllib2.requests,对于大多数比较简单的场景或者以学习为目的,可以用这两个库实现.这里有一篇我之前写过的用urllib2+BeautifulSoup做的一 ...
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
- scrapy爬虫笔记(三)------写入源文件的爬取
开始爬取网页:(2)写入源文件的爬取 为了使代码易于修改,更清晰高效的爬取网页,我们将代码写入源文件进行爬取. 主要分为以下几个步骤: 一.使用scrapy创建爬虫框架: 二.修改并编写源代码,确定我 ...
- [转]Scrapy入门教程
关键字:scrapy 入门教程 爬虫 Spider 作者:http://www.cnblogs.com/txw1958/ 出处:http://www.cnblogs.com/txw1958/archi ...
随机推荐
- c# 字符串大小写混合转换
我是个.net萌新,在大学是计算机应用专业 学的比较杂 出来准备走net方向 培训了两个月了 今天被出了一道上机题 题本来是挺简单的 输入一个字符 如果是大写则转换为小写 如果是小写则转换为大 ...
- maven课程 项目管理利器-maven 3-4 eclipse安装maven插件和新建maven项目
本节主要讲了两个主要内容, 1 eclipse安装maven插件 2 新建maven项目 3 本人实操 1 eclipse安装maven插件 eclipse4.0以上和myec ...
- Day3 Form表单
Day3 Form表单 一.form表单 :提交数据 表单在网页中主要负责数据采集功能,它用<form>标签定义. 用户输入的信息都要包含在form标签中,点击提交后,< ...
- 解决 Maven 项目中找不到 jdk 的 tools.jar 文件的办法(多数情况下适用)
<dependency> <groupId>jdk.tools</groupId> <artifactId>jdk.tools</artifact ...
- sublime介绍常用插件和快捷键
简介 Sublime Text是由程序员Jon Skinner于2008年1月份所开发出来的,它最初被设计为一个具有丰富扩展功能的Vim. 是一个跨平台的编辑器,同时支持Windows.Linux.M ...
- 移动web基础
接触retina屏 基础知识(移动Web的基础知识)排版布局(高效的移动Web布局)开发效率终端交互优化 pixel像素基础viewport视图viewport_meta标签viewport_codi ...
- SpringCloud的学习记录(2)
这一章节主要讲如何搭建eureka-client项目. 在我们生成的Demo项目上右键点击New->Module->spring Initializr, 然后next, 填写Group和A ...
- 聪明的Azure CDN,帮你找到云端捷径
你知道吗?身处上海和纽约的两个用户同时通过网络收看“春晚”直播,纽约播放得可能比上海还要更流畅,这当然不是因为纽约距离北京的直播机房更近或者网速更快,而是因为大年夜在大洋彼岸围观“春晚”的观众相对较少 ...
- 只为更快、更省、更安全的 Azure CDN
来来来!小编今天要公布一件大事啦: 经过最近一次更新,Azure CDN 高级版服务 HTTPS SSL 证书的申请方式有所改进啦,除了现有的 Azure CDN 代为申请证书外,还支持用户自己申请的 ...
- TeamViewer 软件完全卸载
TeamViewer 软件似乎用于商业环境中 - 彻底卸载 Windows 1. 检测为商业用途该软件似乎用于商业环境中.请注意:免费版仅供个人使用.您的会话将在 5 分钟后终止. 2.1 Close ...