决策树的基本ID3算法
一 ID3算法的大致思想
基本的ID3算法是通过自顶向下构造决策树来进行学习的。我们首先思考的是树的构造从哪里开始,这就涉及到选择属性进行树的构造了,那么怎样选择属性呢?为了解决这个问题,我们使用统计测试来确定每一个实例属性单独分类训练样例的能力,把分类能力最好的属性作为树根节点的测试。然后为根节点属性的每个可能值产生一个分支,并把训练样例排列到适当的分支之下。然后重复整个过程,用每个分支节点关联的训练样例来选取在该点被测试的最佳属性。这形成了对合格决策树的贪婪搜索,也就是算法从不回溯重新考虑以前的选择。
下面是ID3算法进行二分类的流程
从图中我们可以看出决策树的构造是一个递归的过程
二 熵(entropy)和信息增益(information gain)

ID3算法的核心问题是选取在树的每个结点要测试的属性,这里我们用属性的信息增益来衡量属性对训练样例的区分能力,属性的信息增益越大,表示区分能力越强。ID3算法在增长树的每一步使用信息增益标准从候选属性中选择属性。
首先在这里说一下 熵的概念,在信息论中广泛使用的一个度量标准,称为熵,它刻画了任意样例集的纯度。
给定包含关于某个目标概念的正反样例的样例集S,那么S相对这个布尔型分类的熵为:
Entropy(S) ≡-p⊕log2p⊕-pΘlog2pΘ其中p⊕是S中正例的比例,pΘ是在S中反例的比例。如果S的所有成员属于同一类,辣么S的熵为0,当集合中正反样例的数量相等时熵为1,其他情况介于0和1之间。
上面是关于目标分类为bool类型下的熵,更一般的,如果目标属性具有c个不同的值,那么S相对于c个状态的分类的熵定义为:
其中pi 是S中属于类别i的比例。
用信息增益度量期望的熵降低
有了熵作为衡量训练样例集合纯度的标准,现在可以定义属性分类数据的效力的度量标准。这个标准被称为信息增益。简单的说,一个属性的信息增益就是由于使用这个属性分割样例而导致的期望熵降低。更精确地说,一个属性A相对样例集合S的信息增益Gain(S,A)被定义为:
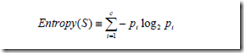
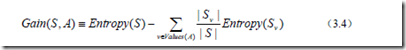
其中Values(A)是属性A所有可能值的集合,Sv是属性A的值为v的子集。等式的第一项就是原来集合S的熵,第二项是用A分类S后熵的期望值。这个第二项描述的期望熵就是每个子集的熵的加权和,权值为属于Sv的样例占原始样例S的比例,所以Gain(S,A)是由于知道属性A的值而导致的期望熵减少。
三 使用python实现一个简单的决策树的生成
1. 计算数据集的香农熵
"""
Created on Sat May 14 13:58:26 2016 @author: MyHome
"""
'''计算给定数据集的香农熵''' from math import log def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
labelCounts[currentLabel] = labelCounts.get(currentLabel,0) + 1
shannonEnt = 0.0
for key in labelCounts:
pro = float(labelCounts[key])/numEntries
shannonEnt = -pro * log(pro,2) return shannonEnt
2.创建数据
def createDataSet():
dataSet = [['Sunny','Hot','High','Weak','No'],['Sunny','Hot','High','Strong','No'],\
['Overcast','Hot','High','Weak','Yes'],['Rain','Mild','High','Weak','Yes'],\
['Rain','Cool','Normal','Weak','Yes'],['Rain','Cool','Normal','Strong','No'],\
['Overcast','Cool','Normal','Strong','Yes'],['Sunny','Mild','High','Weak','No'],\
['Sunny','Cool','Normal','Weak','Yes'],['Rain','Mild','Normal','Weak','Yes'],\
['Sunny','Mild','Normal','Strong','Yes'],['Overcast','Mild','High','Strong','Yes'],\
['Overcast','Hot','Normal','Weak','Yes'],['Rain','Mild','High','Strong','No']]
labels = ['Outlook','Temperature','Humidity','Wind']
return dataSet,labels
3.按照给定的特征划分数据集(根据某一属性的属性值对数据集进行划分)
def splitDataSet(dataSet,axis,value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis + 1 :])
retDataSet.append(reducedFeatVec) return retDataSet
4.计算数据集中各属性的信息增益,选出当前最佳分类属性
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet,i,value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob *calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if (infoGain >bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
5.如果数据集已经处理了所有属性,但是类标签依然不是唯一的,此时我们需要决定如何定义该叶子节点,在这种情况下,我们通常会采用多数表决的方法决定该叶子节点的分类
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1 sortedClassCount = sorted(classCount.iteritems(),key = operator.itemgetter(1),reverse = True) return sortedClassCount[0][0]
6. 构造树
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat,value),subLabels)
return myTree
7.运行结果
dataSet,labels = createDataSet() createTree(dataSet,labels)
Out[10]:
{'Outlook': {'Overcast': 'Yes',
'Rain': {'Wind': {'Strong': 'No', 'Weak': 'Yes'}},
'Sunny': {'Humidity': {'High': 'No', 'Normal': 'Yes'}}}}
根据结果我们可以画出决策树
四 总结
我们通过不断选取当前最佳属性来把数据集进行划分,直到遍历所有属性或每个分支下的所有样例都为同一类为止,这是一个不断递归生成树的过程。
决策树的基本ID3算法的更多相关文章
- python数据分析算法(决策树2)CART算法
CART(Classification And Regression Tree),分类回归树,,决策树可以分为ID3算法,C4.5算法,和CART算法.ID3算法,C4.5算法可以生成二叉树或者多叉树 ...
- ID3算法Java实现
ID3算法java实现 1 ID3算法概述 1.1 信息熵 熵是无序性(或不确定性)的度量指标.假如事件A的全概率划分是(A1,A2,...,An),每部分发生的概率是(p1,p2,...,pn).那 ...
- 深入了解机器学习决策树模型——C4.5算法
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第22篇文章,我们继续决策树的话题. 上一篇文章当中介绍了一种最简单构造决策树的方法--ID3算法,也就是每次选择一个特 ...
- 决策树ID3算法的java实现(基本试用所有的ID3)
已知:流感训练数据集,预定义两个类别: 求:用ID3算法建立流感的属性描述决策树 流感训练数据集 No. 头痛 肌肉痛 体温 患流感 1 是(1) 是(1) 正常(0) 否(0) 2 是(1) 是(1 ...
- 数据挖掘之决策树ID3算法(C#实现)
决策树是一种非常经典的分类器,它的作用原理有点类似于我们玩的猜谜游戏.比如猜一个动物: 问:这个动物是陆生动物吗? 答:是的. 问:这个动物有鳃吗? 答:没有. 这样的两个问题顺序就有些颠倒,因为一般 ...
- 决策树 -- ID3算法小结
ID3算法(Iterative Dichotomiser 3 迭代二叉树3代),是一个由Ross Quinlan发明的用于决策树的算法:简单理论是越是小型的决策树越优于大的决策树. 算法归 ...
- 决策树-预测隐形眼镜类型 (ID3算法,C4.5算法,CART算法,GINI指数,剪枝,随机森林)
1. 1.问题的引入 2.一个实例 3.基本概念 4.ID3 5.C4.5 6.CART 7.随机森林 2. 我们应该设计什么的算法,使得计算机对贷款申请人员的申请信息自动进行分类,以决定能否贷款? ...
- 决策树笔记:使用ID3算法
决策树笔记:使用ID3算法 决策树笔记:使用ID3算法 机器学习 先说一个偶然的想法:同样的一堆节点构成的二叉树,平衡树和非平衡树的区别,可以认为是"是否按照重要度逐渐降低"的顺序 ...
- ID3算法 决策树的生成(2)
# coding:utf-8 import matplotlib.pyplot as plt import numpy as np import pylab def createDataSet(): ...
随机推荐
- js控制TR的显示隐藏
在很多现实的场景中,有的文本框我们希望在选择“是”的按钮之后才出现,这就需要js控制TR的隐藏和显示,如何控制,本文为大家揭晓 下文分享的一段代码:选择是的按钮就显示身高和体重的文本框的代码.注意:r ...
- 组合vs继承
继承,建立子类. 组合(或聚集),在类定义中引用其它类的实例.
- Flex 4 不同主题下容器子元素的管理方法
Flex 下,容器主要分两类:Spark容器, Halo容器. Spark容器 Halo容器 说明 numElements numChildern 容器的子元素数量. addElement( ) ad ...
- SDUT 3345 数据结构实验之二叉树六:哈夫曼编码
数据结构实验之二叉树六:哈夫曼编码 Time Limit: 1000MS Memory Limit: 65536KB Submit Statistic Problem Description 字符的编 ...
- 学习资料 经典SQL语句大全
一.基础 1.说明:创建数据库CREATE DATABASE database-name 2.说明:删除数据库drop database dbname3.说明:备份sql server--- 创建 备 ...
- No.011 Container With Most Water
11. Container With Most Water Total Accepted: 86363 Total Submissions: 244589 Difficulty: Medium Giv ...
- ASP.NET运行机制原理 ---浏览器与IIS的交互过程 自己学习 网上查了下别人写的总结的很好 就转过来了 和自己写的还好里嘻嘻
一.浏览器和服务器的交互原理 (一).浏览器和服务器交互的简单描述: 1.通俗描述:我们平时通过浏览器来访问网站,其实就相当于你通过浏览器去访问一台电脑上访问文件一样,只不过浏览器的访问请求是由被访问 ...
- 【Hibernate 7】浅谈Hibernate的缓存机制
一.Hibernate缓存机制简介 对于Hibernate本身来说,它的缓存主要包括三部分:session缓存(一级缓存).二级缓存.查询缓存. 1.1,session缓存 随着session的关闭而 ...
- mount挂载
与ln -s 功能类似 # mount --bind /data/public /home/user/public /etc/fstab # <file system> <mount ...
- 见怪不怪的typedef
typedef是C++中的一个十分重要的关键字,它有强大的功能和方法的用途.但是有时候,碰到一些用到typedef的地方却感到很奇怪了. 给个栗子尝尝: typedef void(*pFun)(voi ...