Spark RDD概念学习系列之RDD的操作(七)
RDD的操作
RDD支持两种操作:转换和动作。
1)转换,即从现有的数据集创建一个新的数据集。
2)动作,即在数据集上进行计算后,返回一个值给Driver程序。
例如,map就是一种转换,它将数据集每一个元素都传递给函数,并返回一个新的分布式数据集表示结果。另一个方面,reduce是一种动作,通过一些函数将所有元素叠加起来,并将最终结果返回Driver(还有一个并行的reduceByKey,能返回一个分布式数据集)。
下图描述了从外部数据源创建RDD,经过多次转换,通过一个动作操作将结果写回外部存储系统的逻辑运行图。整个过程的计算都是在Worker中的Executor中运行。

图 1 RDD的创建、转换和动作的逻辑计算图
RDD的转换
RDD中的所有转换都是惰性的,也就是说,它们并不会直接计算结果。相反的,它们只是记住这些应用到基础数据集(例如一个文件)上的转换动作。只有当发生一个要求返回结果给Driver的动作时,这些转换才会真正运行。这个设计让Spark更加有效率地运行。例如我们可以实现:通过map创建的一个新数据集,并在reduce中使用,最终只返回reduce的结果给Driver,而不是整个大的新数据集。图2描述了RDD在进行groupByRey时的内部RDD转换的实现逻辑图。图3描述了reduceByKey的实现逻辑图。

图2 RDD groupByKey的逻辑转换图
在groupByKey的操作中,会在MapPartitionsRDD做一次Shuffle,图2中设置的分片数量是3,因此ShuffledRDD会有3个分片,ShuffledRDD实际上仅仅是从上游的任务中读取Shuffle的结果,因此图的箭头是指向上游的MapPartitionsRDD的。关于Shuffle的实现实际上要比图中展示得复杂得多。reduceByKey和groupByKey的实现差不多,它在Shuffle完成之后,需要做一次reduce。
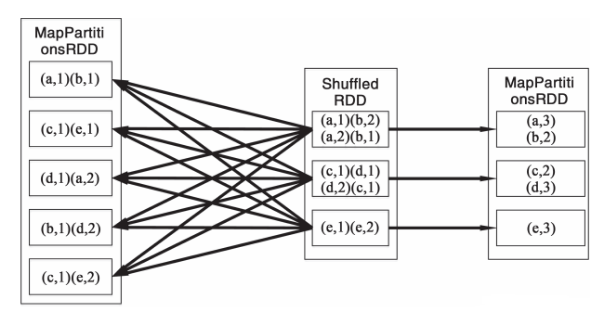
图3 RDD reduceByKey 的逻辑转换图
默认情况下,每一个转换过的RDD都会在它执行一个动作时被重新计算。不过也可以使用persist(或者cache)方法,在内存中持久化一个RDD。在这种情况下,Spark将会在集群中保存相关元素,下次查询这个RDD时能更快访问它。也支持在磁盘上持久化数据集,或在集群间复制数据集。
Spark RDD概念学习系列之RDD的操作(七)的更多相关文章
- Spark RDD概念学习系列之RDD的checkpoint(九)
RDD的检查点 首先,要清楚.为什么spark要引入检查点机制?引入RDD的检查点? 答:如果缓存丢失了,则需要重新计算.如果计算特别复杂或者计算耗时特别多,那么缓存丢失对于整个Job的影响是不容 ...
- Spark RDD概念学习系列之RDD的缓存(八)
RDD的缓存 RDD的缓存和RDD的checkpoint的区别 缓存是在计算结束后,直接将计算结果通过用户定义的存储级别(存储级别定义了缓存存储的介质,现在支持内存.本地文件系统和Tachyon) ...
- Spark RDD概念学习系列之RDD是什么?(四)
RDD是什么? 通俗地理解,RDD可以被抽象地理解为一个大的数组(Array),但是这个数组是分布在集群上的.详细见 Spark的数据存储 Spark的核心数据模型是RDD,但RDD是个抽象类 ...
- Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系? RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency). 1)窄依赖指的是每 ...
- Spark RDD概念学习系列之RDD的缺点(二)
RDD的缺点? RDD是Spark最基本也是最根本的数据抽象,它具备像MapReduce等数据流模型的容错性,并且允许开发人员在大型集群上执行基于内存的计算. 为了有效地实现容错,(详细见ht ...
- Spark RDD概念学习系列之RDD与DSM的异同分析(十三)
RDD是一种分布式的内存抽象,下表列出了RDD与分布式共享内存(Distributed Shared Memory,DSM)的对比. 在DSM系统[1]中,应用可以向全局地址空间的任意位置进行读写操作 ...
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
- Spark RDD概念学习系列之RDD的转换(十)
RDD的转换 Spark会根据用户提交的计算逻辑中的RDD的转换和动作来生成RDD之间的依赖关系,同时这个计算链也就生成了逻辑上的DAG.接下来以“Word Count”为例,详细描述这个DAG生成的 ...
- Spark RDD概念学习系列之RDD的创建(六)
RDD的创建 两种方式来创建RDD: 1)由一个已经存在的Scala集合创建 2)由外部存储系统的数据集创建,包括本地文件系统,还有所有Hadoop支持的数据集,比如HDFS.Cassandra.H ...
随机推荐
- git subtree有效管理公共第三方lib
如果你的项目中有很多第三方的lib,你希望使用它,并且也希望可能对该lib做修改并且贡献到原始的项目中去,或者你的项目希望模块化,分为几个repo单独维护,那么git subtree就是一个选择.gi ...
- github创建repo,本地导入git项目到github
一般地,在注册好github账号之后,你需要做的事情就是在github上创建一个repo,该repo将成为你的origin(central)repo,随后你就可以将本地的项目git repo导入到这个 ...
- win7x64安装wince6
Windows Embedded CE 安装方法 Wince的安装相对比较复杂,即使是一个Wince的老手,也可能遇到这样那样的问题.想来真是悲摧,Windows XP, Windows 7,64位, ...
- windows下github pages + hexo next 搭建个人博客
一.github pages 搭建个人博客一般需要购买域名和空间,github pages为我们提供了这两样东西,而且是免费的,相关介绍和使用方法参考这里 github pages. 二.Hexo 一 ...
- dom4j创建格式化的xml文件
import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java. ...
- iPad中控制器view的width和height
一.iPad中控制器view的width和height 1> 规律 * width 是宽高中最小的那个值 * height 是宽高中最大的那个值 2> 举例(比如窗口根控制器的view,有 ...
- java-过滤器-监听器-拦截器
1.过滤器 Servlet中的过滤器Filter是实现了javax.servlet.Filter接口的服务器端程序,主要的用途是过滤字符编码.做一些业务逻辑判断等.其工作原理是,只要你在web.xml ...
- [转]glew, glee与 gl glu glut glx glext的区别和关系
原文地址:http://blog.csdn.net/delacroix_xu/article/details/5881942 因为也是初接触,所以就当了解,等深入学习后再回顾这篇文章观点. GLEW是 ...
- 中小型数据库 RMAN CATALOG 备份恢复方案(一)
对于数据库的稳定性,高可用,跨平台以及海量数据库的处理,Oracle 数据库通常是大型数据库和大企业的首选.尽管如此,仍然不乏很多中小企业想要品尝一下Oracle腥味,因此在Oracle环境中也有不少 ...
- Android的IPC机制(一)——AIDL的使用
综述 IPC(interprocess communication)是指进程间通信,也就是在两个进程间进行数据交互.不同的操作系统都有他们自己的一套IPC机制.例如在Linux操作系统中可以通过管道. ...