Kafka之--python-kafka测试kafka集群的生产者与消费者
前面两篇博客已经完成了Kafka的搭建,今天再来点稍高难度的帖子。
测试一下kafka的消息消费行为。虽然,kafka有测试的shell脚本可以直接测试,但既然我最近在玩python,那还是用python程序来做个测试。
1)首先需要kafka-python安装包。
这个包依赖的是python 3以上的版本,但是linux7默认都是安装2.7版本。
当然,你也可以在linux下安装一个3.x版本,但是如此又会需要调整yum(依赖python 2.7)等一大堆东西。
还有我习惯于windows下调试程序,那我何不在windows下安装3.X版本。用它来访问我的linux虚拟机呢?
说干就干,首先安装pycharm,再安装python 3.7。
https://www.python.org/ftp/python/3.7.2/python-3.7.2.exe
安装完后,可以直接用CMD>pip install kafka-python
C:\Users\Lenovo>pip install kafka-python
WARNING: Ignoring invalid distribution -ip (d:\programs\python\python37\lib\site-packages)
WARNING: Ignoring invalid distribution -ip (d:\programs\python\python37\lib\site-packages)
Requirement already satisfied: kafka-python in d:\programs\python\python37\lib\site-packages (2.0.2)
WARNING: Ignoring invalid distribution -ip (d:\programs\python\python37\lib\site-packages)
WARNING: Ignoring invalid distribution -ip (d:\programs\python\python37\lib\site-packages)
WARNING: Ignoring invalid distribution -ip (d:\programs\python\python37\lib\site-packages) C:\Users\Lenovo>pip list kafka
WARNING: Ignoring invalid distribution -ip (d:\programs\python\python37\lib\site-packages)
Package Version
---------------------- -------
dnspython 1.16.0
kafka-python 2.0.2
mysql-connector-python 8.0.19
pip 21.1.3
psutil 5.8.0
pygame 1.9.4
setuptools 41.2.0
WARNING: Ignoring invalid distribution -ip (d:\programs\python\python37\lib\site-packages)
WARNING: Ignoring invalid distribution -ip (d:\programs\python\python37\lib\site-packages)
2)pycharm新建python项目,指定本地python环境(不要用默认的虚拟环境)
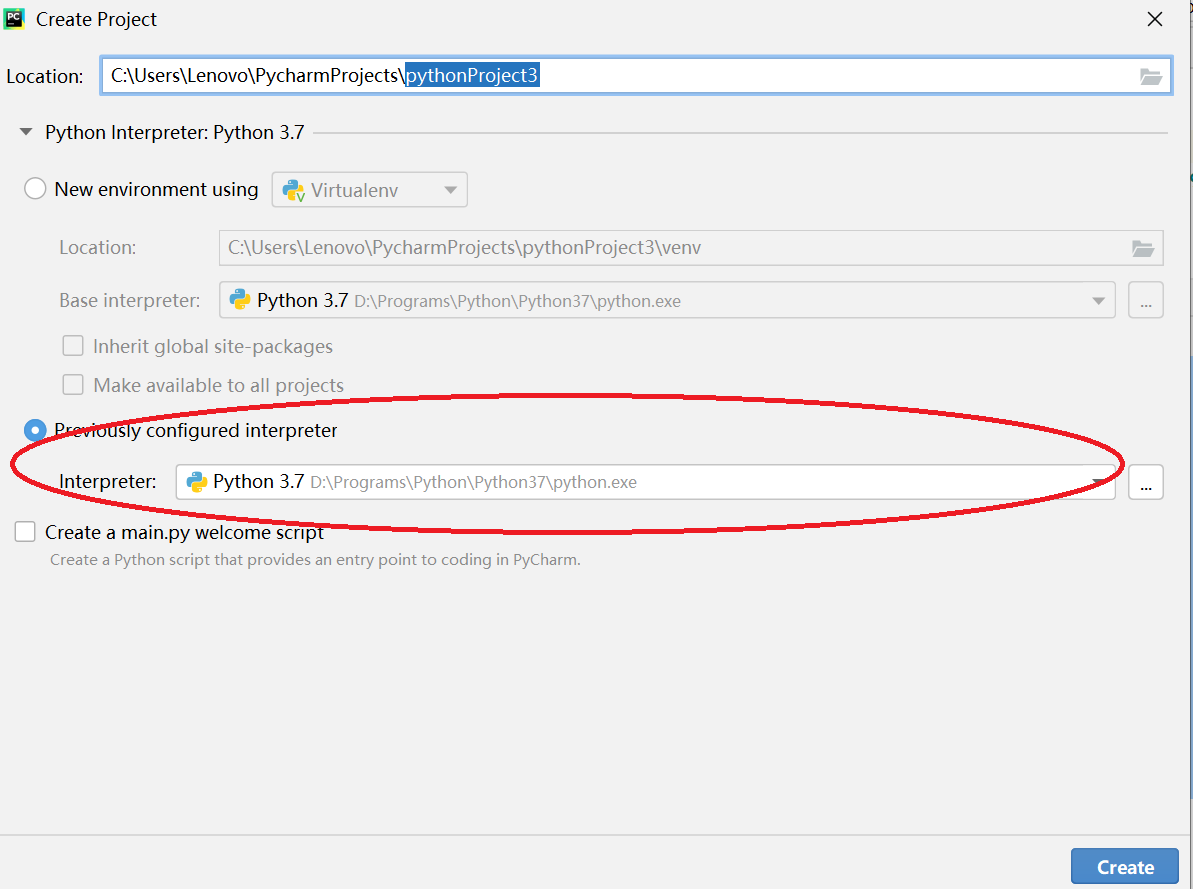
创建2个Python文件,producer.py & consumer.py
Producer.py
#!usr/bin/python
import json
import time
from kafka import KafkaProducer
from kafka.errors import KafkaError, KafkaTimeoutError topic = 'mytopic2'
producer = KafkaProducer(bootstrap_servers="192.168.56.151:9092,192.168.56.152:9092,192.168.56.153:9092")
msg_dict = {
'method':"post",
'header':'json',
'content':"17909",
} for i in range(100,1200):
si= str(i);
msg_dict['method'] = "post " + si;
msg_dict['content']=si;
msg = json.dumps(msg_dict).encode(encoding='utf-8')
print(msg)
try:
future = producer.send(topic, msg)
result = future.get(timeout=10)
print(result)
time.sleep(1)
except KafkaTimeoutError as err:
print(err)
except Exception as err:
print(err) producer.close()
Consumer.py
#!usr/bin/python
from kafka import KafkaConsumer
topic = 'mytopic2'
consumer = KafkaConsumer(topic, bootstrap_servers=['192.168.56.151:9092','192.168.56.152:9092','192.168.56.153:9092'],group_id='mygroup2')
for msg in consumer:
recv = "%s:%d:%d: key=%s value=%s" % (msg.topic, msg.partition, msg.offset, msg.key, msg.value)
print (recv)
3)执行过程
Producer每秒钟产生一个消息。
D:\Programs\Python\Python37\python.exe C:/Users/Lenovo/PycharmProjects/pythonProjectKafka2/Producer.py
b'{"method": "post 100", "header": "json", "content": "100"}'
RecordMetadata(topic='mytopic2', partition=1, topic_partition=TopicPartition(topic='mytopic2', partition=1), offset=0, timestamp=1626272823148, log_start_offset=0, checksum=None, serialized_key_size=-1, serialized_value_size=58, serialized_header_size=-1)
b'{"method": "post 101", "header": "json", "content": "101"}'
RecordMetadata(topic='mytopic2', partition=0, topic_partition=TopicPartition(topic='mytopic2', partition=0), offset=0, timestamp=1626272824211, log_start_offset=0, checksum=None, serialized_key_size=-1, serialized_value_size=58, serialized_header_size=-1)
b'{"method": "post 102", "header": "json", "content": "102"}'
Consumer接收消息。
当我只开始一个Consumer的时候,它可以接收到所有partition(我配置的parition=3)的消息。
当再启动2个Consumer的时候,可以看到每个consumer都只会消费某一个partition的数据了。
说明: mytopic2:1:1 对应的是 ( Topicname: parition-id: offset ),具体你看代码就清楚了。
D:\Programs\Python\Python37\python.exe C:/Users/Lenovo/PycharmProjects/pythonProjectKafka2/Consumer.py
mytopic2:1:1: key=None value=b'{"method": "post 103", "header": "json", "content": "103"}'
mytopic2:1:2: key=None value=b'{"method": "post 104", "header": "json", "content": "104"}'
mytopic2:1:3: key=None value=b'{"method": "post 105", "header": "json", "content": "105"}'
mytopic2:2:0: key=None value=b'{"method": "post 106", "header": "json", "content": "106"}'
mytopic2:1:4: key=None value=b'{"method": "post 107", "header": "json", "content": "107"}'
mytopic2:2:1: key=None value=b'{"method": "post 108", "header": "json", "content": "108"}'
mytopic2:0:2: key=None value=b'{"method": "post 109", "header": "json", "content": "109"}'
mytopic2:0:3: key=None value=b'{"method": "post 110", "header": "json", "content": "110"}'
mytopic2:1:5: key=None value=b'{"method": "post 111", "header": "json", "content": "111"}'
mytopic2:1:6: key=None value=b'{"method": "post 112", "header": "json", "content": "112"}'
mytopic2:0:4: key=None value=b'{"method": "post 114", "header": "json", "content": "114"}'
mytopic2:0:5: key=None value=b'{"method": "post 115", "header": "json", "content": "115"}'
mytopic2:1:7: key=None value=b'{"method": "post 116", "header": "json", "content": "116"}'
mytopic2:1:8: key=None value=b'{"method": "post 117", "header": "json", "content": "117"}'
mytopic2:0:6: key=None value=b'{"method": "post 118", "header": "json", "content": "118"}'
mytopic2:0:7: key=None value=b'{"method": "post 120", "header": "json", "content": "120"}'
mytopic2:0:8: key=None value=b'{"method": "post 121", "header": "json", "content": "121"}'
mytopic2:1:9: key=None value=b'{"method": "post 122", "header": "json", "content": "122"}'
mytopic2:1:10: key=None value=b'{"method": "post 123", "header": "json", "content": "123"}'
mytopic2:0:9: key=None value=b'{"method": "post 126", "header": "json", "content": "126"}'
mytopic2:0:10: key=None value=b'{"method": "post 127", "header": "json", "content": "127"}'
mytopic2:0:11: key=None value=b'{"method": "post 129", "header": "json", "content": "129"}'
mytopic2:0:12: key=None value=b'{"method": "post 130", "header": "json", "content": "130"}'
mytopic2:0:13: key=None value=b'{"method": "post 137", "header": "json", "content": "137"}'
mytopic2:0:14: key=None value=b'{"method": "post 138", "header": "json", "content": "138"}'
mytopic2:0:15: key=None value=b'{"method": "post 139", "header": "json", "content": "139"}'
mytopic2:0:16: key=None value=b'{"method": "post 140", "header": "json", "content": "140"}' Process finished with exit code -1
C:\Users\Lenovo\PycharmProjects\pythonProjectKafka2>python Consumer.py
mytopic2:2:2: key=None value=b'{"method": "post 113", "header": "json", "content": "113"}'
mytopic2:2:3: key=None value=b'{"method": "post 119", "header": "json", "content": "119"}'
mytopic2:2:4: key=None value=b'{"method": "post 124", "header": "json", "content": "124"}'
mytopic2:2:5: key=None value=b'{"method": "post 125", "header": "json", "content": "125"}'
mytopic2:1:11: key=None value=b'{"method": "post 131", "header": "json", "content": "131"}'
mytopic2:1:12: key=None value=b'{"method": "post 134", "header": "json", "content": "134"}'
mytopic2:1:13: key=None value=b'{"method": "post 144", "header": "json", "content": "144"}'
mytopic2:1:14: key=None value=b'{"method": "post 146", "header": "json", "content": "146"}'
C:\Users\Lenovo\PycharmProjects\pythonProjectKafka2>python Consumer.py
mytopic2:2:6: key=None value=b'{"method": "post 128", "header": "json", "content": "128"}'
mytopic2:2:7: key=None value=b'{"method": "post 132", "header": "json", "content": "132"}'
mytopic2:2:8: key=None value=b'{"method": "post 133", "header": "json", "content": "133"}'
mytopic2:2:9: key=None value=b'{"method": "post 135", "header": "json", "content": "135"}'
mytopic2:2:10: key=None value=b'{"method": "post 136", "header": "json", "content": "136"}'
mytopic2:2:11: key=None value=b'{"method": "post 141", "header": "json", "content": "141"}'
mytopic2:2:12: key=None value=b'{"method": "post 142", "header": "json", "content": "142"}'
mytopic2:2:13: key=None value=b'{"method": "post 143", "header": "json", "content": "143"}'
Kafka之--python-kafka测试kafka集群的生产者与消费者的更多相关文章
- 使用Kafka的一些简单介绍: 1集群 2原理 3 术语
目录 第一节 Kafka 集群 Kafka 集群搭建 Kafka 集群快速搭建 第二节 集群管理工具 集群管理工具 集群 Issues 第三节 使用命令操纵集群 第四节 Kafka 术语说明 第五节 ...
- Kafka 详解(二)------集群搭建
这里通过 VMware ,我们安装了三台虚拟机,用来搭建 kafka集群,虚拟机网络地址如下: hostname ipaddress ...
- python 连接 redis cluster 集群
一. redis集群模式有多种, cluster模式只是其中的一种实现方式, 其原理请自行谷歌或者百度, 这里只举例如何使用Python操作 redis cluster 集群 二. python 连接 ...
- python连接redis哨兵集群
一.redis集群模式有多种, 哨兵模式只是其中的一种实现方式, 其原理请自行谷歌或者百度 二.python 连接 redis 哨兵集群 1. 安装redis包 pip install redis 2 ...
- Kafka 0.9+Zookeeper3.4.6集群搭建、配置,新Client API的使用要点,高可用性测试,以及各种坑 (转载)
Kafka 0.9版本对java client的api做出了较大调整,本文主要总结了Kafka 0.9在集群搭建.高可用性.新API方面的相关过程和细节,以及本人在安装调试过程中踩出的各种坑. 关于K ...
- kafka项目经验之如何进行Kafka压力测试、如何计算Kafka分区数、如何确定Kaftka集群机器数量
@ 目录 Kafka压测 Kafka Producer(生产)压力测试 Kafka Consumer(消费)压力测试 计算Kafka分区数 Kafka机器数量计算 Kafka压测 用Kafka官方自带 ...
- kafka分布式消息队列介绍以及集群安装
简介 首先简单说下对kafka的理解: 1.kafka是一个分布式的消息缓存系统: 2.kafka集群中的服务器节点都被称作broker 3.kafka的客户端分为:一是producer(消息生产者) ...
- kafka 0.10.2 cetos6.5 集群部署
安装 zookeeper http://www.cnblogs.com/xiaojf/p/6572351.html安装 scala http://www.cnblogs.com/xiaojf/p/65 ...
- 05.kafka提前准备工作:搭建zookeeper集群环境
总体参考:http://www.cnblogs.com/zhangs1986/p/6564839.html 搭建之间同步下spark01.02.03的环境 复制/opt/flume这个文件夹到 spa ...
随机推荐
- 用 Flutter 和 Firebase 轻松构建 Web 应用
作者 / Very Good Ventures Team 我们 (Very Good Ventures 团队) 与 Google 合作,在今年的 Google I/O 大会上推出了 照相亭互动体验 ( ...
- Halcon 纹理缺陷检测 apply_texture_inspection_model
在纹理中找瑕疵.基于高斯混合模型(GMM)分类器的纹理检查模型,适用于图像金字塔,可以分析纹理的多个频率范围. [要求]训练样本,必须完美无瑕疵. [步骤] 1.创建模型 create_texture ...
- .Net Redis实战指南——常用命令
本问主要介绍rabbitmqctl工具的常用命令. vhost 一个RabbitMQ服务器可以创建多个虚拟的消息服务器,称之为虚拟主机(virtual host),简称为vhost.vhost之间是绝 ...
- 网页站点下载器teleport ultra
软件名称:teleport ultra 介绍:teleport ultra是一款专门的网页站点下载器,使用这款工具可以方便地下载网页数据,包括网站的文字.图片.flash动画等,可以轻松下载所有的网站 ...
- MySQL 页完全指南——浅入深出页的原理
之前写了一些关于 MySQL 的 InnoDB 存储引擎的文章,里面好几次都提到了页(Pages)这个概念,但是都只是简要的提了一下.例如之前在聊 InnoDB内存结构 时提到过,但当时的重点是内存架 ...
- 『无为则无心』Python基础 — 3、搭建Python开发环境
目录 1.Python开发环境介绍 2.Python解释器的分类 3.下载Python解释器 4.安装Python解释器 5.Python解释器验证 1.Python开发环境介绍 所谓"工欲 ...
- oracle中job无法正常运行,如何排查
1.生产环境Oracle中的job无法正常运行 select * from dba_jobs_running;(查看正在运行的job) 2.select * from dba_jobs(查看job历史 ...
- cisco交换机端口从errdisable状态恢复
故障描述 经用户反馈,一台cisco2960x接入交换机的一个端口插网线不通,ip电话也没有poe供电. 排查过程 查看交换机端口状态,发现变成了errdisable: ZH_HQN_SW2960X_ ...
- redis学习第一天
不同于其他的常用关系型数据库,redis是一个非常轻便,体积小,存放键值对的数据库,常用于构建高性能,可扩展的Web应用程序. 这是我第一次接触redis,之前没有使用过,只听说过.因为刚毕业,找工作 ...
- Android系统编程入门系列之清单文件
在上一篇文章中已经提到,Android系统加载应用程序之后,首先会读取该应用程序的AndroidManifest.xml清单文件,之后根据该清单文件加载后边的东西.所以要开发应用程序,自然要先知道清单 ...