HDFS 高可用(HA)环境搭建
步骤一:修改公共属性配置 core-site.xml 文件
[root@node-01 ~]# cd /root/apps/hadoop-3.2.1/etc/hadoop
[root@node-01 hadoop]# vim core-site.xml
<configuration>
<!-- 设置hdfs文件系统-->
<property>
<name>fs.defaultFs</name>
<value>hdfs://node-01:9000</value>
</property>
<!-- zookeeper 集群-->
<property>
<name>ha.zookeeper.quorum</name>
<value>node-01:2181,node-02:2181,node-03:2181</value>
</property>
</configuration>
步骤二:修改 HDFS 属性配置 hdfs-site.xml 文件
[root@node-01 ~]# cd /root/apps/hadoop-3.2.1/etc/hadoop
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/apps/hadoop-3.2.1/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/apps/hadoop-3.2.1/data/datanode</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node-02:9868</value>
</property>
<property>
<!-- 指定hdfs的命名服务,需要和core-site.xml中的保持一致 -->
<name>dfs.nameservices</name>
<value>hadoop</value>
</property>
<property>
<!-- hadoop下面有两个NameNode,分别是nn1,nn2 -->
<name>dfs.ha.namenodes.hadoop</name>
<value>nn1,nn2</value>
</property>
<property>
<!-- nn1的RPC通信地址 -->
<name>dfs.namenode.rpc-address.hadoop.nn1</name>
<value>node-01:9000</value>
</property>
<property>
<!-- nn1的http通信地址 -->
<name>dfs.namenode.http-address.hadoop.nn1</name>
<value>node-01:9870</value>
</property>
<property>
<!-- nn2的RPC通信地址 -->
<name>dfs.namenode.rpc-address.hadoop.nn2</name>
<value>node-02:9000</value>
</property>
<property>
<!-- nn2的http通信地址 -->
<name>dfs.namenode.http-address.hadoop.nn2</name>
<value>node-02:9870</value>
</property>
<property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node-01:8485;node-02:8485;node-03:8485/hadoop</value>
</property>
<property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<name>dfs.journalnode.edits.dir</name>
<value>/root/apps/hadoop-3.2.1/data/journal</value>
</property>
<property>
<!-- 开启NameNode故障时自动切换 -->
<name>dfs.ha.automatic-failover.enabled.hadoop</name>
<value>true</value>
</property>
<property>
<!-- 配置失败自动切换实现方式 -->
<name>dfs.client.failover.proxy.provider.hadoop</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!-- 配置故障切换脑裂解决方案-->
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<!-- 配置namenode 连接 journalnode 重试次数-->
<name>ipc.client.connect.max.retries</name>
<value>30</value>
</property>
</configuration>
步骤三:添加 JournalNode 进程执行权限
[root@node-01 ~]# echo "export HDFS_JOURNALNODE_USER=root" >> /etc/profile
[root@node-01 ~]# source /etc/profile
[root@node-02 ~]# echo "export HDFS_JOURNALNODE_USER=root" >> /etc/profile
[root@node-02 ~]# source /etc/profile
[root@node-03 ~]# echo "export HDFS_JOURNALNODE_USER=root" >> /etc/profile
[root@node-03 ~]# source /etc/profile
步骤四:拷贝配置到 node-02、node-03
[root@node-01 hadoop]# scp core-site.xml node-02:$PWD
[root@node-01 hadoop]# scp hdfs-site.xml node-02:$PWD
[root@node-01 hadoop]# scp core-site.xml node-03:$PWD
[root@node-01 hadoop]# scp hdfs-site.xml node-03:$PWD
步骤五:删除 node-01、node-02 和 node-03 存储数据目录
[root@node-01 ~]# rm -rf /root/apps/hadoop-3.2.1/data
[root@node-02 ~]# rm -rf /root/apps/hadoop-3.2.1/data
[root@node-03 ~]# rm -rf /root/apps/hadoop-3.2.1/data
步骤六:启动所有进程
启动所有的进程可以直接执行 start-dfs.sh 脚本,但是为了对 Hadoop 的进程有所了解,这里选择一个个进程按顺序来启动(注:必须严格按照顺序启动进程)
启动 ZooKeeper 进程
[root@node-01 ~]# zkCluster.sh start
[root@node-01 ~]# jps
1567 QuorumPeerMain
启动 Journalnode 进程
[root@node-01 ~]# hdfs --daemon start journalnode
[root@node-01 hadoop]# jps
2039 JournalNode #journalnode 进程已启动
2059 Jps
[root@node-02 ~]# hdfs --daemon start journalnode
[root@node-03 ~]# hdfs --daemon start journalnode
启动 NameNode(nn1) 进程
[root@node-01 ~]# hdfs namenode -format
[root@node-01 ~]# hdfs --daemon start namenode
启动 NameNode(nn2) 进程
[root@node-02 ~]# hdfs namenode -bootstrapStandby
[root@node-02 ~]# hdfs --daemon start namenode注:在 HA 中不需要启动 SecondaryNameNode 进程,因为 Standby NameNode 会执行 checkpointing 机制
启动 DataNode 进程
[root@node-01 hadoop]# hdfs --daemon start datanode
[root@node-02 hadoop]# hdfs --daemon start datanode
[root@node-03 hadoop]# hdfs --daemon start datanode
启动 DFSZKFailoverController(ZKFC)进程
[root@node-01 hadoop]# hdfs zkfc -formatZK
[root@node-01 hadoop]# hdfs --daemon start zkfc
[root@node-02 hadoop]# hdfs --daemon start zkfc
步骤七:查看所有进程
[root@node-01 hadoop]# jps
2368 QuorumPeerMain
3715 DataNode
3987 DFSZKFailoverController
4435 NameNode
3430 JournalNode
[root@node-02 hadoop]# jps
2069 QuorumPeerMain
3033 DataNode
2379 JournalNode
5278 NameNode
[root@node-03 logs]# jps
2036 QuorumPeerMain
2170 JournalNode
2298 DataNode
步骤八:查看 HDFS HA 集群状态报告信息
[root@node-02 ~]# hdfs dfsadmin -report
步骤九:Web UI 中 查看 NameNode(nn1)和 NameNode(nn2)状态
nn1地址: 192.168.229.21:9870
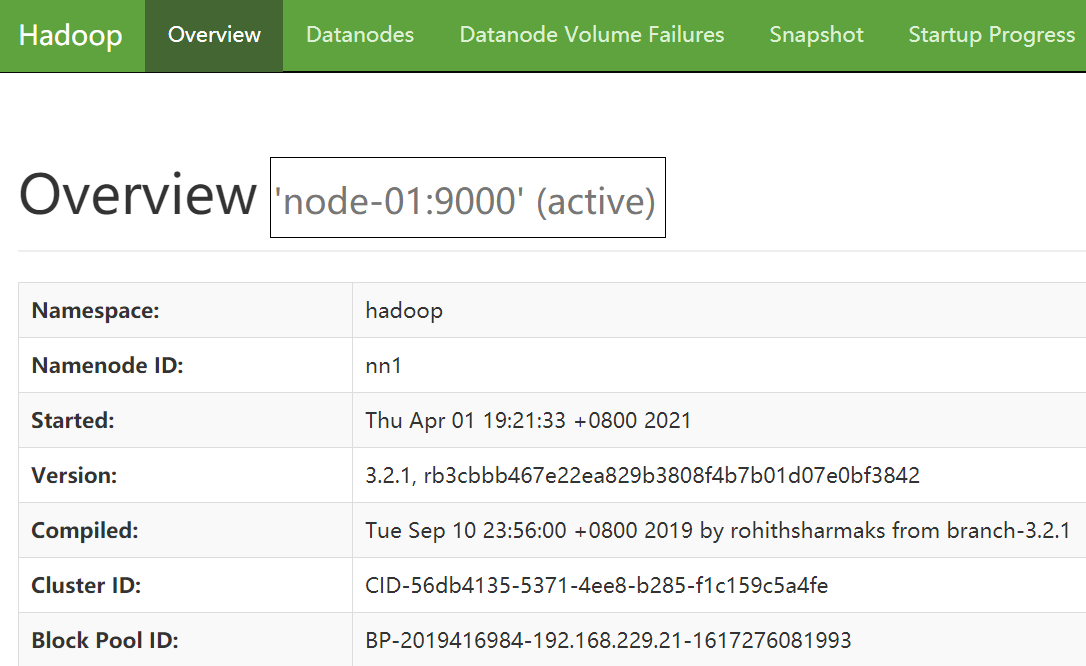
nn2 地址:192.168.229.22:9870
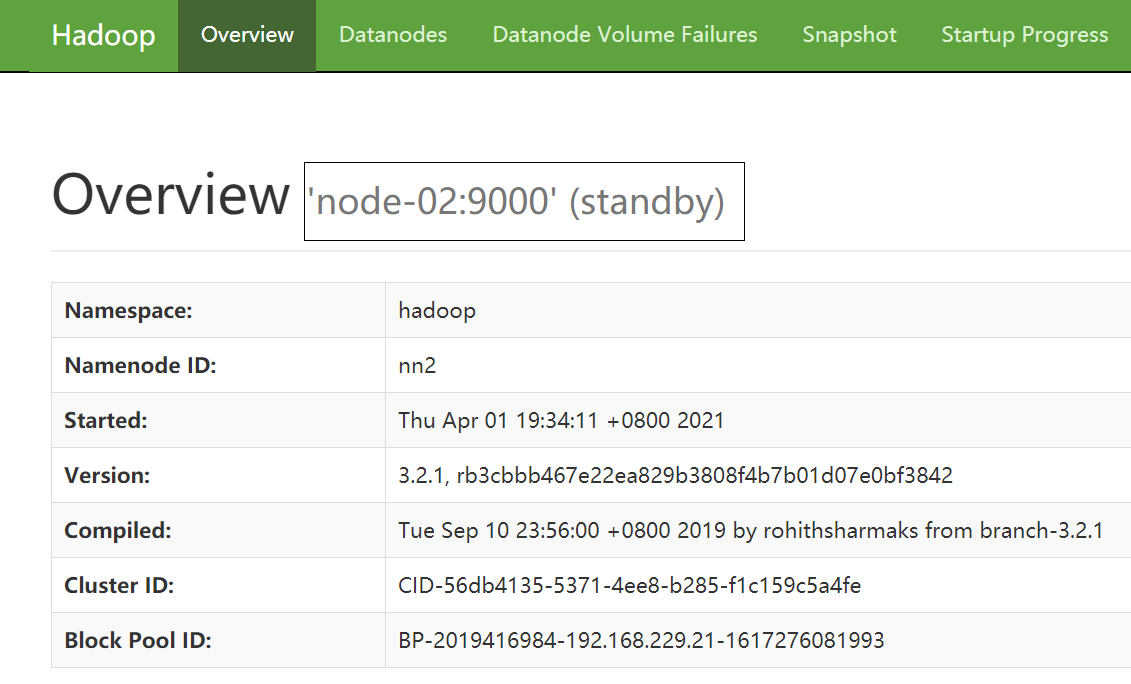
步骤十:故障转移测试
#安装故障转移脑裂问题解决工具
[root@node-01 hadoop]# yum install psmisc
[root@node-02 hadoop]# yum install psmisc
[root@node-03 hadoop]# yum install psmisc
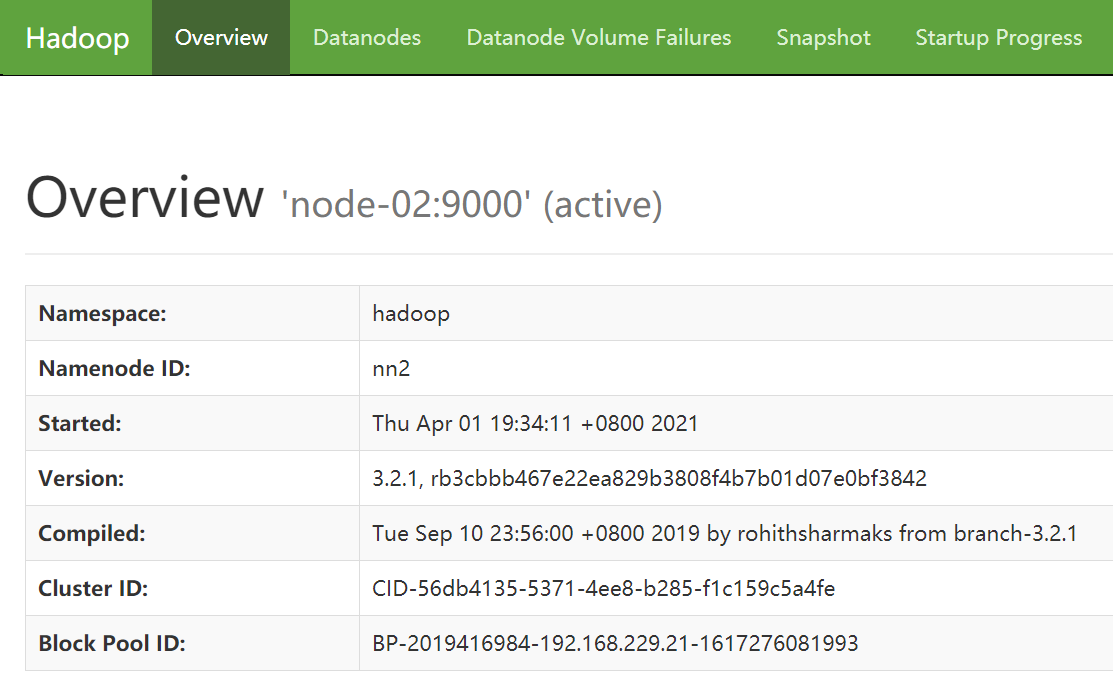
#关闭 node-01 的 NameNode(active)进程
[root@node-01 hadoop-3.2.1]# hdfs --daemon stop namenode
查看 node-02 的 NameNode,由 Standby 变为 了 Active,说明自动故障转移成功:)
HDFS 高可用(HA)环境搭建的更多相关文章
- HDFS 高可用分布式环境搭建
HDFS 高可用分布式环境搭建 作者:Grey 原文地址: 博客园:HDFS 高可用分布式环境搭建 CSDN:HDFS 高可用分布式环境搭建 首先,一定要先完成分布式环境搭建 并验证成功 然后在 no ...
- MySQL 系列(五) 多实例、高可用生产环境实战
MySQL 系列(五) 多实例.高可用生产环境实战 第一篇:MySQL 系列(一) 生产标准线上环境安装配置案例及棘手问题解决 第二篇:MySQL 系列(二) 史上最屌.你不知道的数据库操作 第三 ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- hadoop HA+Federation(高可用联邦)搭建配置(一)
hadoop HA+Federation(高可用联邦)搭建配置(一) 标签(空格分隔): 未分类 介绍 hadoop 集群一共有4种部署模式,详见<hadoop 生态圈介绍>. HA联邦模 ...
- hadoop HA+Federation(高可用联邦)搭建配置(二)
hadoop HA+Federation(高可用联邦)搭建配置(二) 标签(空格分隔): hadoop core-site.xml <?xml version="1.0" e ...
- Hadoop框架:HDFS高可用环境配置
本文源码:GitHub·点这里 || GitEE·点这里 一.HDFS高可用 1.基础描述 在单点或者少数节点故障的情况下,集群还可以正常的提供服务,HDFS高可用机制可以通过配置Active/Sta ...
- [大数据] hadoop高可用(HA)部署(未完)
一.HA部署架构 如上图所示,我们可以将其分为三个部分: 1.NN和DN组成Hadoop业务组件.浅绿色部分. 2.中间深蓝色部分,为Journal Node,其为一个集群,用于提供高可用的共享文件存 ...
- RabbitMQ高级指南:从配置、使用到高可用集群搭建
本文大纲: 1. RabbitMQ简介 2. RabbitMQ安装与配置 3. C# 如何使用RabbitMQ 4. 几种Exchange模式 5. RPC 远程过程调用 6. RabbitMQ高可用 ...
- 【转载】Redis Sentinel 高可用服务架构搭建
作者:田园里的蟋蟀 出处:http://www.cnblogs.com/xishuai/ 本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接. 阅读 ...
随机推荐
- buuctf --pwn part2
pwn难啊! 1.[OGeek2019]babyrop 先check一下文件,开启了NX 在ida中没有找到system.'/bin/sh'等相关的字符,或许需要ROP绕过(废话,题目提示了) 查看到 ...
- MySQL 储存引擎知识点
一:MySQL 存储引擎概述 1.1 什么是存储引擎: '''MySQL中的数据用各种不同的技术存储在文件(或者内存)中.这些技术中的每一种技术都使用不同的存储机制.索引技巧.锁定水平并且最终提供广泛 ...
- 使用docker快速安装软件
安装mysql mkdir /opt/mysql /opt/mysql/etc /opt/mysql/data docker run -itd --name mariadb -e MYSQL_ROOT ...
- Springboot+Vue前后端分离的博客项目
项目介绍 演示站(服务器已过期):http://blog.hanzhe.site 开源项目地址 ( 求给个Star ):https://gitee.com/zhang_hanzhe/blog 前端采用 ...
- PowerBI开发 第十八篇:行级安全(RLS)
PowerBI可以通过RLS(Row-level security)限制用户对数据的访问,过滤器在行级别限制数据的访问,用户可以在角色中定义过滤器,通过角色来限制数据的访问.在PowerBI Serv ...
- B - Rikka with Graph HDU - 5631 (并查集+思维)
As we know, Rikka is poor at math. Yuta is worrying about this situation, so he gives Rikka some mat ...
- 01- Java概述
一 Java简介 java语言发展史 发展史简单了解:如下: https://www.jianshu.com/p/a78fcb3ccf63 java语言平台 JavaSE(标准版):可以用户开发普通桌 ...
- 【运维--系统】nacos介绍和安装
目录: 简介 安装java 安装mysql 安装nacos 附录 简介 Nacos 致力于帮助您发现.配置和管理微服务.Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现.服务配置.服 ...
- Building Fire Stations 39届亚洲赛牡丹江站B题
题意: 给你一棵树,让你再里面选取两个点作为**点,然后所有点的权值是到这两个点中最近的那个的距离,最后问距离中最长的最短是多少,输出距离还有那两个点(spj特判). 思路: 现场 ...
- 神经网络与机器学习 笔记—Rosenblatt感知机
Rosenblatt感知机器 感知器在神经网络发展的历史上占据着特殊位置:它是第一个从算法上完整描述的神经网络.它的发明者Rosenblatt是一位心里学家,在20世纪60年代和70年代,感知器的启发 ...