HDFS 高可用(HA)环境搭建
步骤一:修改公共属性配置 core-site.xml 文件
[root@node-01 ~]# cd /root/apps/hadoop-3.2.1/etc/hadoop
[root@node-01 hadoop]# vim core-site.xml
<configuration>
<!-- 设置hdfs文件系统-->
<property>
<name>fs.defaultFs</name>
<value>hdfs://node-01:9000</value>
</property>
<!-- zookeeper 集群-->
<property>
<name>ha.zookeeper.quorum</name>
<value>node-01:2181,node-02:2181,node-03:2181</value>
</property>
</configuration>
步骤二:修改 HDFS 属性配置 hdfs-site.xml 文件
[root@node-01 ~]# cd /root/apps/hadoop-3.2.1/etc/hadoop
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/apps/hadoop-3.2.1/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/apps/hadoop-3.2.1/data/datanode</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node-02:9868</value>
</property>
<property>
<!-- 指定hdfs的命名服务,需要和core-site.xml中的保持一致 -->
<name>dfs.nameservices</name>
<value>hadoop</value>
</property>
<property>
<!-- hadoop下面有两个NameNode,分别是nn1,nn2 -->
<name>dfs.ha.namenodes.hadoop</name>
<value>nn1,nn2</value>
</property>
<property>
<!-- nn1的RPC通信地址 -->
<name>dfs.namenode.rpc-address.hadoop.nn1</name>
<value>node-01:9000</value>
</property>
<property>
<!-- nn1的http通信地址 -->
<name>dfs.namenode.http-address.hadoop.nn1</name>
<value>node-01:9870</value>
</property>
<property>
<!-- nn2的RPC通信地址 -->
<name>dfs.namenode.rpc-address.hadoop.nn2</name>
<value>node-02:9000</value>
</property>
<property>
<!-- nn2的http通信地址 -->
<name>dfs.namenode.http-address.hadoop.nn2</name>
<value>node-02:9870</value>
</property>
<property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node-01:8485;node-02:8485;node-03:8485/hadoop</value>
</property>
<property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<name>dfs.journalnode.edits.dir</name>
<value>/root/apps/hadoop-3.2.1/data/journal</value>
</property>
<property>
<!-- 开启NameNode故障时自动切换 -->
<name>dfs.ha.automatic-failover.enabled.hadoop</name>
<value>true</value>
</property>
<property>
<!-- 配置失败自动切换实现方式 -->
<name>dfs.client.failover.proxy.provider.hadoop</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!-- 配置故障切换脑裂解决方案-->
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<!-- 配置namenode 连接 journalnode 重试次数-->
<name>ipc.client.connect.max.retries</name>
<value>30</value>
</property>
</configuration>
步骤三:添加 JournalNode 进程执行权限
[root@node-01 ~]# echo "export HDFS_JOURNALNODE_USER=root" >> /etc/profile
[root@node-01 ~]# source /etc/profile
[root@node-02 ~]# echo "export HDFS_JOURNALNODE_USER=root" >> /etc/profile
[root@node-02 ~]# source /etc/profile
[root@node-03 ~]# echo "export HDFS_JOURNALNODE_USER=root" >> /etc/profile
[root@node-03 ~]# source /etc/profile
步骤四:拷贝配置到 node-02、node-03
[root@node-01 hadoop]# scp core-site.xml node-02:$PWD
[root@node-01 hadoop]# scp hdfs-site.xml node-02:$PWD
[root@node-01 hadoop]# scp core-site.xml node-03:$PWD
[root@node-01 hadoop]# scp hdfs-site.xml node-03:$PWD
步骤五:删除 node-01、node-02 和 node-03 存储数据目录
[root@node-01 ~]# rm -rf /root/apps/hadoop-3.2.1/data
[root@node-02 ~]# rm -rf /root/apps/hadoop-3.2.1/data
[root@node-03 ~]# rm -rf /root/apps/hadoop-3.2.1/data
步骤六:启动所有进程
启动所有的进程可以直接执行 start-dfs.sh 脚本,但是为了对 Hadoop 的进程有所了解,这里选择一个个进程按顺序来启动(注:必须严格按照顺序启动进程)
启动 ZooKeeper 进程
[root@node-01 ~]# zkCluster.sh start
[root@node-01 ~]# jps
1567 QuorumPeerMain
启动 Journalnode 进程
[root@node-01 ~]# hdfs --daemon start journalnode
[root@node-01 hadoop]# jps
2039 JournalNode #journalnode 进程已启动
2059 Jps
[root@node-02 ~]# hdfs --daemon start journalnode
[root@node-03 ~]# hdfs --daemon start journalnode
启动 NameNode(nn1) 进程
[root@node-01 ~]# hdfs namenode -format
[root@node-01 ~]# hdfs --daemon start namenode
启动 NameNode(nn2) 进程
[root@node-02 ~]# hdfs namenode -bootstrapStandby
[root@node-02 ~]# hdfs --daemon start namenode注:在 HA 中不需要启动 SecondaryNameNode 进程,因为 Standby NameNode 会执行 checkpointing 机制
启动 DataNode 进程
[root@node-01 hadoop]# hdfs --daemon start datanode
[root@node-02 hadoop]# hdfs --daemon start datanode
[root@node-03 hadoop]# hdfs --daemon start datanode
启动 DFSZKFailoverController(ZKFC)进程
[root@node-01 hadoop]# hdfs zkfc -formatZK
[root@node-01 hadoop]# hdfs --daemon start zkfc
[root@node-02 hadoop]# hdfs --daemon start zkfc
步骤七:查看所有进程
[root@node-01 hadoop]# jps
2368 QuorumPeerMain
3715 DataNode
3987 DFSZKFailoverController
4435 NameNode
3430 JournalNode
[root@node-02 hadoop]# jps
2069 QuorumPeerMain
3033 DataNode
2379 JournalNode
5278 NameNode
[root@node-03 logs]# jps
2036 QuorumPeerMain
2170 JournalNode
2298 DataNode
步骤八:查看 HDFS HA 集群状态报告信息
[root@node-02 ~]# hdfs dfsadmin -report
步骤九:Web UI 中 查看 NameNode(nn1)和 NameNode(nn2)状态
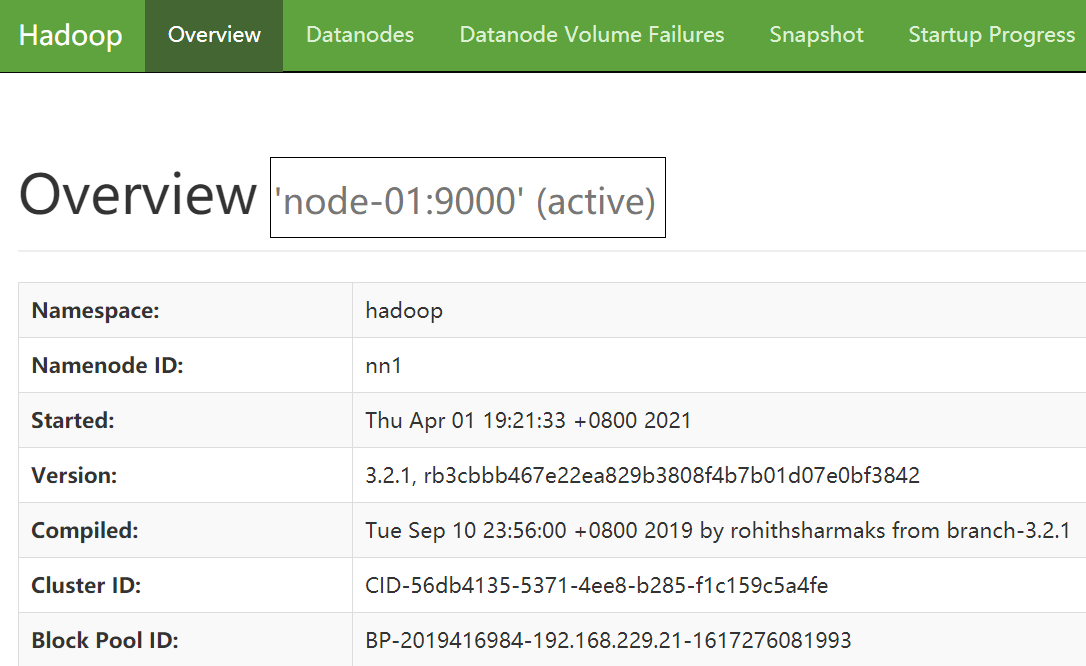
nn1地址: 192.168.229.21:9870
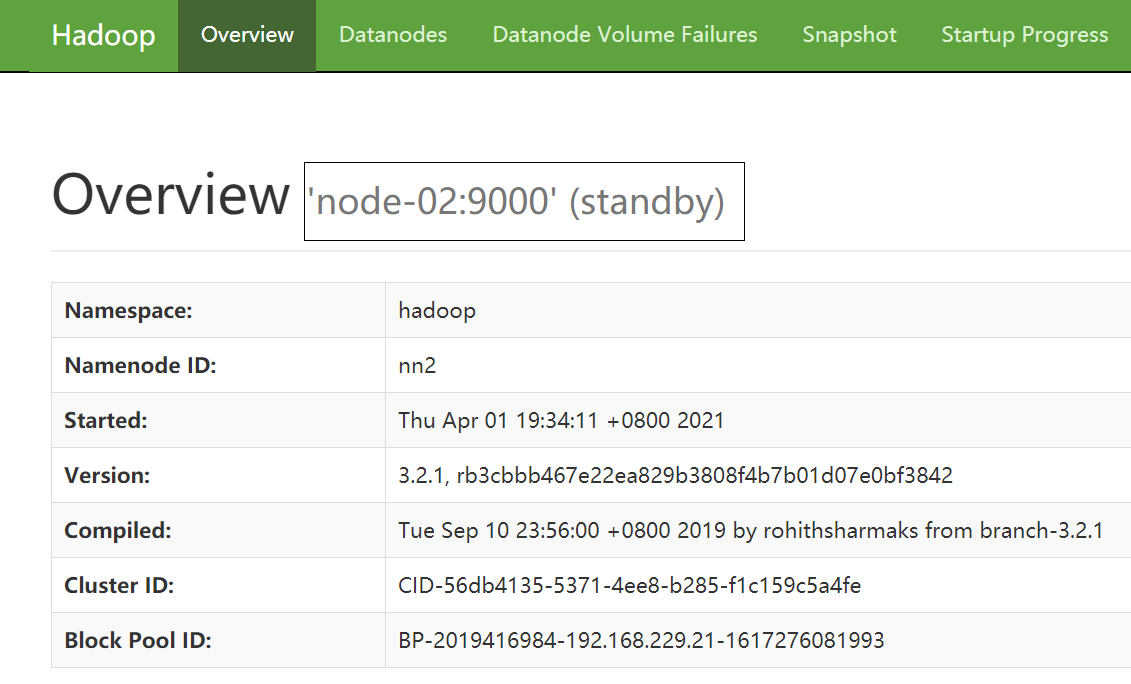
nn2 地址:192.168.229.22:9870
步骤十:故障转移测试
#安装故障转移脑裂问题解决工具
[root@node-01 hadoop]# yum install psmisc
[root@node-02 hadoop]# yum install psmisc
[root@node-03 hadoop]# yum install psmisc
#关闭 node-01 的 NameNode(active)进程
[root@node-01 hadoop-3.2.1]# hdfs --daemon stop namenode
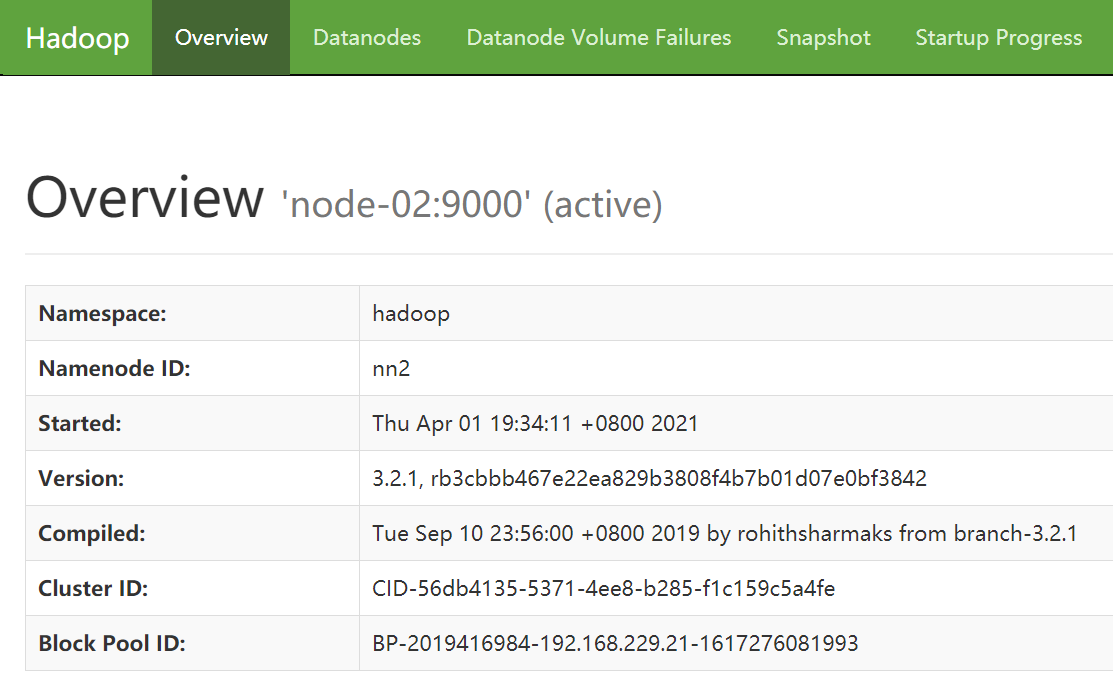
查看 node-02 的 NameNode,由 Standby 变为 了 Active,说明自动故障转移成功:)
HDFS 高可用(HA)环境搭建的更多相关文章
- HDFS 高可用分布式环境搭建
HDFS 高可用分布式环境搭建 作者:Grey 原文地址: 博客园:HDFS 高可用分布式环境搭建 CSDN:HDFS 高可用分布式环境搭建 首先,一定要先完成分布式环境搭建 并验证成功 然后在 no ...
- MySQL 系列(五) 多实例、高可用生产环境实战
MySQL 系列(五) 多实例.高可用生产环境实战 第一篇:MySQL 系列(一) 生产标准线上环境安装配置案例及棘手问题解决 第二篇:MySQL 系列(二) 史上最屌.你不知道的数据库操作 第三 ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- hadoop HA+Federation(高可用联邦)搭建配置(一)
hadoop HA+Federation(高可用联邦)搭建配置(一) 标签(空格分隔): 未分类 介绍 hadoop 集群一共有4种部署模式,详见<hadoop 生态圈介绍>. HA联邦模 ...
- hadoop HA+Federation(高可用联邦)搭建配置(二)
hadoop HA+Federation(高可用联邦)搭建配置(二) 标签(空格分隔): hadoop core-site.xml <?xml version="1.0" e ...
- Hadoop框架:HDFS高可用环境配置
本文源码:GitHub·点这里 || GitEE·点这里 一.HDFS高可用 1.基础描述 在单点或者少数节点故障的情况下,集群还可以正常的提供服务,HDFS高可用机制可以通过配置Active/Sta ...
- [大数据] hadoop高可用(HA)部署(未完)
一.HA部署架构 如上图所示,我们可以将其分为三个部分: 1.NN和DN组成Hadoop业务组件.浅绿色部分. 2.中间深蓝色部分,为Journal Node,其为一个集群,用于提供高可用的共享文件存 ...
- RabbitMQ高级指南:从配置、使用到高可用集群搭建
本文大纲: 1. RabbitMQ简介 2. RabbitMQ安装与配置 3. C# 如何使用RabbitMQ 4. 几种Exchange模式 5. RPC 远程过程调用 6. RabbitMQ高可用 ...
- 【转载】Redis Sentinel 高可用服务架构搭建
作者:田园里的蟋蟀 出处:http://www.cnblogs.com/xishuai/ 本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接. 阅读 ...
随机推荐
- Java JFR 民间指南 - 事件详解 - jdk.ObjectAllocationSample
对象分配采样:jdk.ObjectAllocationSample 引入版本:Java 16 相关 ISSUE:Introduce JFR Event Throttling and new jdk.O ...
- All in All UVA - 10340
You have devised a new encryption technique which encodes a message by inserting between its charac ...
- 基于MATLAB的手写公式识别(7)
今天晚上通过对原有T4模型的修改实现: 1.可以识别真彩图形.(这基本是一样大的,通过这个了解图像分割的原理) 2.在识别心脑管血药类的基础上实现数字的识别.(了解图像识别原理,熟练掌握图像分割技术) ...
- 7.If语句
if单选择结构 语法: if(布尔表达式){ //如果布尔表达式为true将执行的语句 } 例: import java.util.Scanner; public class IfDemo { pub ...
- 2-7 Java基础数据类型之字符型
代码中输入如下部分: /* char的取值范围0-65535 */ public class DataType06 { public static void main(String[]args){ c ...
- Nessus扫描器的使用
目录 Nessus Scans Settings 一个基本扫描的建立 自定义扫描策略 Nessus的高级扫描方法 Nessus Nessus号称是世界上最流行的漏洞扫描程序,全世界有超过75000个组 ...
- LA3644简单并查集判环
题意: 有n个化合物,每个化合物是两种元素组成,现在要装车,但是一旦车上的化合物中的某几个化合物组成这样一组关系,有n个化合物正好用了n中元素,那么就会爆炸,输入的顺序是装车的顺序,对于每 ...
- Python中根据库包名学习使用该库包
目录 Python库包模块 import 语句 from-import 语句 搜索路径 PYTHONPATH 变量 命名空间和作用域 查看模块中所有变量和函数,以及查看具体函数的用法 globals( ...
- Swift系列一 - 数据类型
如果你习惯了OC的语法,第一次接触Swift的语法可能会有点抗拒,因为Swift的语法有点怪.但如果你有前端的基础,学Swift可能会有点吃力,如果你有C++的基础可能会学得比较快点.不管你有什么样的 ...
- C++ Socket 简单封装
以下代码一部分来自于<网络多人游戏架构与编程>, 其它的都是我瞎写的. 备忘. 一个简单的Socket封装,没有做什么高级的操作(比如IO完成端口等等). 1 #pragma once 2 ...