centos7安装Scala、Spark(伪分布式)
centos7安装spark(伪分布式)
spark是由scala语言开发的,首先需要安装scala.
Scala安装
下载scala-2.11.8,(与spark版本要对应)
命令:wget https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz
解压到文件夹并配置环境变量
vim /etc/profile
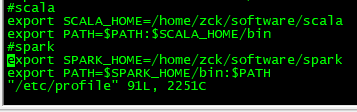
#scala
export SCALA_HOME=/home/zck/software/scala
export PATH=$PATH:$SCALA_HOME/bin
使配置文件生效

测试:scala -version

配置伪分布式spark;
解压到文件夹并配置环境变量
vim /etc/profile
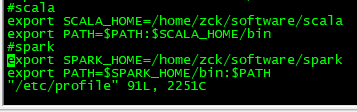
末尾添加以下内容
#spark
export SPARK_HOME=/home/zck/software/spark
export PATH=$SPARK_HOME/bin:$PATH测试
修改配置文件spark/conf/spark-env.sh
加入内容
export JAVA_HOME=/home/zck/software/jdk
export SCALA_HOME=/home/zck/software/scala
export HADOOP_HOME=/home/zck/software/hadoop
export HADOOP_CONF_DIR=/home/zck/software/hadoop/etc/hadoop
export SPARK_MASTER_IP=192.168.13.101
export SPARK_MASTER_PORT=7077
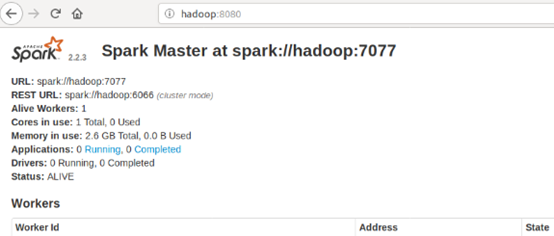
启动spark服务
进入spark文件夹,sbin/start-all.sh

然后再去浏览器看看
Spark yarn模式配置
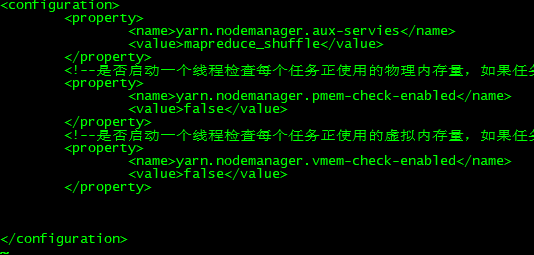
1、修改hadoop配置文件yarn-site.xml,添加如下内容:
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
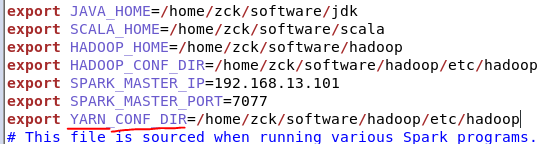
2、修改spark-env.sh,添加如下配置:
export YARN_CONF_DIR=/opt/module/hadoop-2.7.2/etc/hadoop
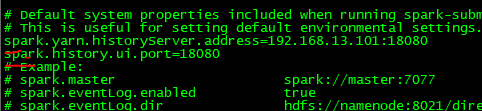
3、日志配置
修改配置文件spark-defaults.conf
添加如下内容:
spark.yarn.historyServer.address=hadoop102:18080
spark.history.ui.port=18080
4、重启spark历史服务
sbin/stop-history-server.sh
sbin/start-history-server.sh

Spark几种模式对比
|
模式 |
Spark安装机器数 |
需启动的进程 |
所属者 |
|
Local |
1 |
无 |
Spark |
|
Standalone |
3 |
Master及Worker |
Spark |
|
Yarn |
1 |
Yarn及HDFS |
Hadoop |
centos7安装Scala、Spark(伪分布式)的更多相关文章
- ZooKeeper:win7上安装单机及伪分布式安装
zookeeper是一个为分布式应用所设计的分布式的.开源的调度服务,它主要用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用,协调及其管理的难度,提高性能的分布式服务. 本章的目的:如何 ...
- Hadoop的HDFS和MapReduce的安装(三台伪分布式集群)
一.创建虚拟机 1.从网上下载一个Centos6.X的镜像(http://vault.centos.org/) 2.安装一台虚拟机配置如下:cpu1个.内存1G.磁盘分配20G(看个人配置和需求,本人 ...
- 大数据:Hadoop(JDK安装、HDFS伪分布式环境搭建、HDFS 的shell操作)
所有的内容都来源与 Hadoop 官方文档 一.Hadoop 伪分布式安装步骤 1)JDK安装 解压:tar -zxvf jdk-7u79-linux-x64.tar.gz -C ~/app 添加到系 ...
- Hadoop安装教程_伪分布式
文章更新于:2020-04-09 注1:hadoop 的安装及单机配置参见:Hadoop安装教程_单机(含Java.ssh安装配置) 注2:hadoop 的完全分布式配置参见:Hadoop安装教程_分 ...
- Mac环境下安装配置Hadoop伪分布式
伪分布式需要修改5个配置文件(hadoop2.x的配置文件$HADOOP_HOME/etc/hadoop) 第一个:hadoop-env.sh #vim hadoop-env.sh #第25行,由于新 ...
- 第5章 选举模式和ZooKeeper的集群安装 5-2 单机伪分布式安装zookeeper集群
先搭建伪分布式集群,再去搭建真分布式集群.有些的人的电脑内存.性能比较低,所以在搭建真实的一个分布式环境的话,可能会相对来说比较卡,所以两种都会做一下,首先会在单机上搭建一个集群.单机上的集群主要就是 ...
- Spark学习之路 (五)Spark伪分布式安装
一.JDK的安装 JDK使用root用户安装 1.1 上传安装包并解压 [root@hadoop1 soft]# tar -zxvf jdk-8u73-linux-x64.tar.gz -C /usr ...
- Spark学习之路 (五)Spark伪分布式安装[转]
JDK的安装 JDK使用root用户安装 上传安装包并解压 [root@hadoop1 soft]# tar -zxvf jdk-8u73-linux-x64.tar.gz -C /usr/local ...
- spark伪分布式安装
一,在官网下载对应的版本http://spark.apache.org/downloads.html 二在linux中解压下来的spark包 三:配置环境变量 (1)在/etc/profi ...
随机推荐
- GET /static/plugins/bootstrap/css/bootstrap.css HTTP/1.1" 404 1718
引用的Bootstrap一直不出来,页面中的静态资源无法加载, 报这个错的原因,是因为配置setting时候没有配置好. 后面在setting里面添加下面这段就好了 STATICFILES_DIRS ...
- kudu_CM安装准备工作
Cloudera Manager简介: hadoop: https://yq.aliyun.com/articles/60759 ----------------------------------- ...
- lite-monitor 一款基于shell命令的监控系统
介绍 lite-monitor 一款基于shell命令的监控系统,可以根据项目中输出的日志定时输出或者统计输出,并发送钉钉机器人报警消息. lite-monitor能做什么: 定时监控某个服务进程是否 ...
- Navicat Premium 12 安装 与 激活
官方简体中文下载网址:https://www.navicat.com.cn/download/navicat-premium 安装的过程....(都是中文)所以略过. 开始破解....( ...... ...
- Verilog写入变量值到文件语句
integer signed fid_out1,fid_out2; initial begin fid_out1 = $fopen("dataout_i.txt","w& ...
- org.apache.commons.io.FilenameUtils 常用的方法
/** * getExtension * 获取文件的后缀名 */ public static void testGetExtension() { String extension = Filename ...
- js上传整个文件夹
文件夹上传:从前端到后端 文件上传是 Web 开发肯定会碰到的问题,而文件夹上传则更加难缠.网上关于文件夹上传的资料多集中在前端,缺少对于后端的关注,然后讲某个后端框架文件上传的文章又不会涉及文件夹. ...
- luogu P1494 [国家集训队]小Z的袜子 ( 普 通 )
题目: 链接:https://www.luogu.org/problemnew/show/P1494 题意:一些袜子排成一排,每个袜子有固定的颜色. ...
- 快速掌握Python的捷径-Python基础前传(1)
文: jacky(朱元禄) 开文序 最近看新闻,发现高考都考Python了,随着人工智能的火热,学数据科学的人越来越多了!但对于数据行业本身来说,现象级的火热,这并不是什么好事. 方丈高楼平地起,无论 ...
- H5页游戏内存溢出问题
记录自己解决的第一个H5页的性能问题, 关于内存溢出 拼字游戏 问题表现 初始化后, 第一次拼字并不卡. 随着拼的次数越来越多, 越来越卡 浏览器任务管理器中可以看出, 内存持续升高 确定内存问题, ...