利用python3 爬取 网易云 上 周杰伦所有专辑,歌曲,评论,并完成可视化分析已经歌曲情绪化分析
这篇文章适合于python爱好者,里面可能很多语句是冗长的,甚至可能有一些尚未发现的BUG,这个伴随着我们继续学习来慢慢消解吧。接下来 我把里面会用到的东西在这里做一个简单总结吧:本文用到了两门解释性编程语言python3 + bash(shell),为什么用shell,我会在后面具体分析。用到的模块requests,re,os,jieba,glob,json,lxml,pyecharts,heapq,collections.看到这么多模块,大家一定很头痛,其实最开始我也没想到会用到这么多。不过随着程序的进行,这些模块自然的就出现在程序里,初学者对每一个模块没必要去特别了解。但是用法需要掌握。 话不多说,接下来就进入我们的正题吧。
一.找到需要爬取的内容,分析网页,抓包查看交互内容
首先我们先进入到我们需要抓取的内容的地址。http://music.163.com/# 这是网易云音乐的首页,我们的目的是抓取周杰伦的所有歌曲,歌词,已经评论,那我们在搜索处输入周杰伦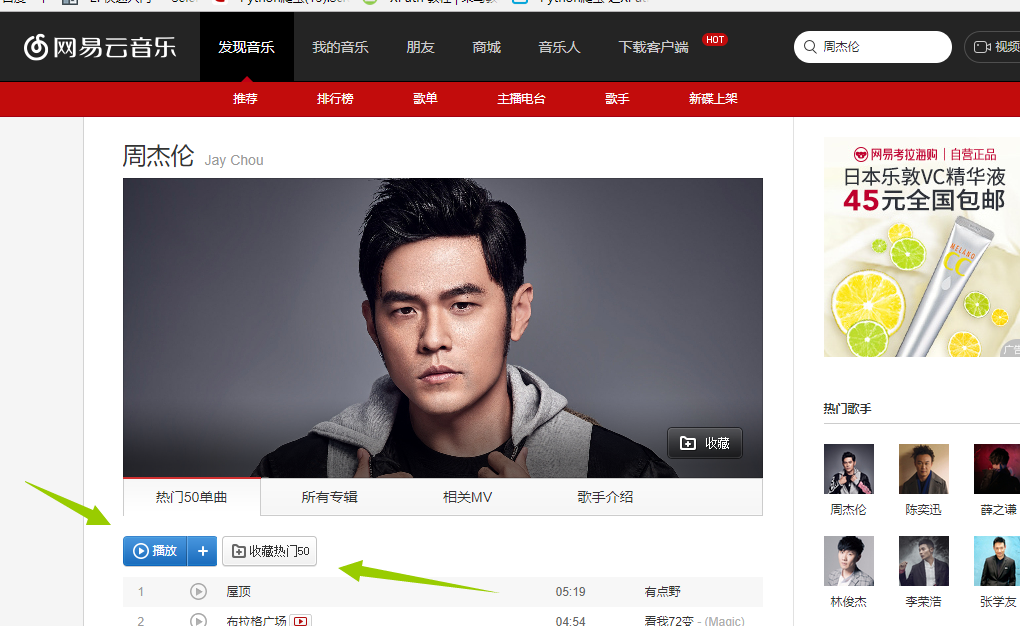 得到这张图,我们发现这里面只有最多50首歌(很多人分析网易云的歌曲就只选取TOP50),我们想要的是全部,所以这个URL不符合要求,我们继续寻找其他的URL地址。我在这里花了不少时间,最后找到了一个间接的方法,首先抓取周杰伦的全部专辑信息,然后通过专辑信息再去寻找全部歌曲(目前在网易云上我还没发现什么方法可以直接获取全部歌曲名字)。好了确定好了方针,我们第一步抓取所有专辑 进入http://music.163.com/#/artist/album?id=6452如下图所示!
得到这张图,我们发现这里面只有最多50首歌(很多人分析网易云的歌曲就只选取TOP50),我们想要的是全部,所以这个URL不符合要求,我们继续寻找其他的URL地址。我在这里花了不少时间,最后找到了一个间接的方法,首先抓取周杰伦的全部专辑信息,然后通过专辑信息再去寻找全部歌曲(目前在网易云上我还没发现什么方法可以直接获取全部歌曲名字)。好了确定好了方针,我们第一步抓取所有专辑 进入http://music.163.com/#/artist/album?id=6452如下图所示!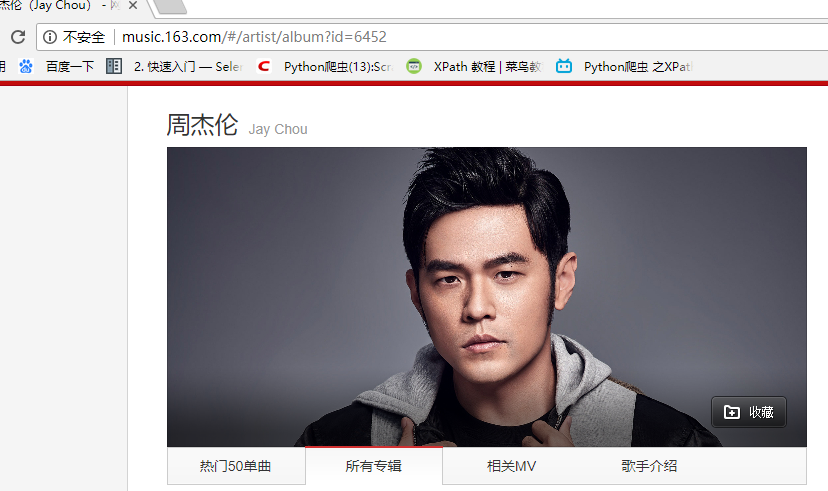 在这里面我们可以看到周杰伦所有专辑信息点击下一页 观察url发现变成了 http://music.163.com/#/artist/album?id=6452&limit=12&offset=12 这样!!!所以有点html基础的人都知道这里的limit=12是每页显示专辑的数量。OK,接下来我们就来获取专辑吧!我们在页面输入http://music.163.com/#/artist/album?id=6452&limit=100&offset=12(改成100 避免多次抓取,一次抓去完),在谷歌的抓包工具(F12)里面查看交互信息发现如下:
在这里面我们可以看到周杰伦所有专辑信息点击下一页 观察url发现变成了 http://music.163.com/#/artist/album?id=6452&limit=12&offset=12 这样!!!所以有点html基础的人都知道这里的limit=12是每页显示专辑的数量。OK,接下来我们就来获取专辑吧!我们在页面输入http://music.163.com/#/artist/album?id=6452&limit=100&offset=12(改成100 避免多次抓取,一次抓去完),在谷歌的抓包工具(F12)里面查看交互信息发现如下:
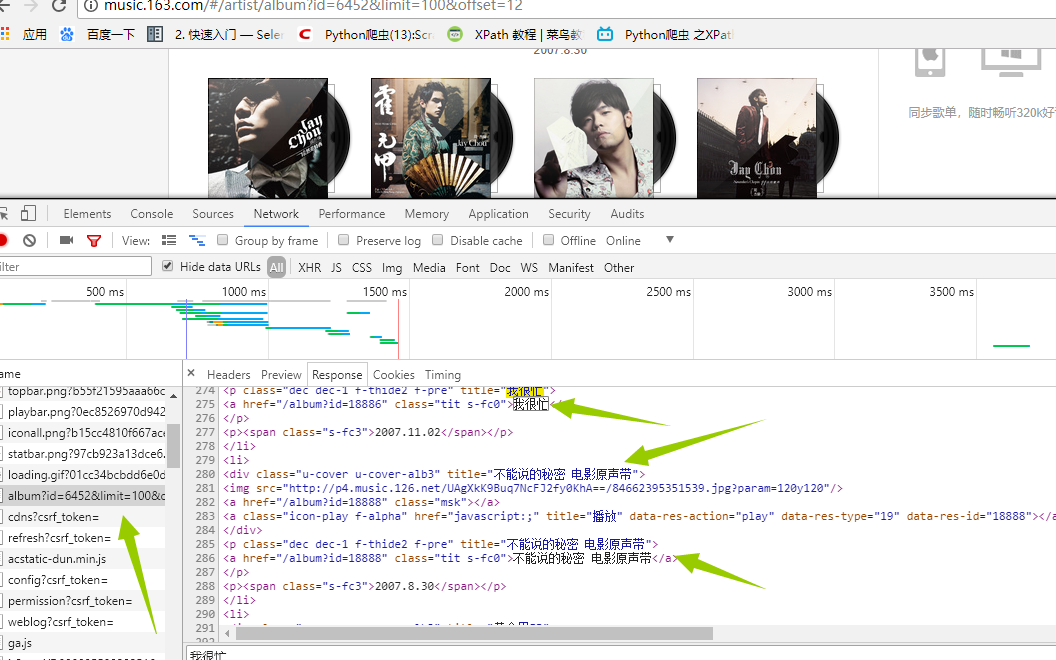 是的你没看错,这就是我们想要的信息,那事情就变得简单的,我们没必要用复杂的工具比如(selenium)去加载整个页面,(事实上,如果还没想到抓取歌曲的方法,我估计就得用它了),我们再看header里面有什么
是的你没看错,这就是我们想要的信息,那事情就变得简单的,我们没必要用复杂的工具比如(selenium)去加载整个页面,(事实上,如果还没想到抓取歌曲的方法,我估计就得用它了),我们再看header里面有什么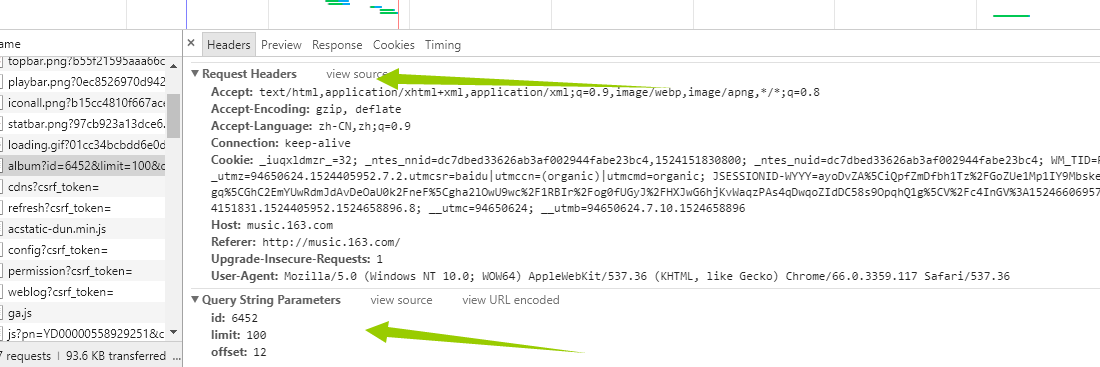 这里面的string我们不用管了,因为它已经在我们的url里面了,我们只需要看request headers 这个就是我们给服务器发送的东西,发送之后,服务器返回给我们的就是network里面的信息。好,接下来我们伪造浏览器发送请求。具体代码如下:
这里面的string我们不用管了,因为它已经在我们的url里面了,我们只需要看request headers 这个就是我们给服务器发送的东西,发送之后,服务器返回给我们的就是network里面的信息。好,接下来我们伪造浏览器发送请求。具体代码如下:
def GetAlbum(self):
urls="http://music.163.com/artist/album?id=6452&limit=100&offset=0"
headers={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'keep-alive',
'Cookie':'_iuqxldmzr_=32; _ntes_nnid=dc7dbed33626ab3af002944fabe23bc4,1524151830800; _ntes_nuid=dc7dbed33626ab3af002944fabe23bc4; __utmc=94650624; __utmz=94650624.1524151831.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utma=94650624.1505452853.1524151831.1524151831.1524176140.2; WM_TID=RpKJQQ90pzUSYfuSWgFDY6QEK1Gb4Ulg; JSESSIONID-WYYY=ZBmSOShrk4UKH5K%5CVasEPuc0b%2Fq6m5eAE91jWCmD6UpdB2y4vbeazO%2FpQK%5CgiBW0MUDDWfB1EuNaV5c4wIJZ08hYQKDhpsHnDeMAgoz98dt%2B%2BFfhdiiNJw9Y9vRR5S4GU%2FziFp%2BliFX1QTJj%2BbaIGD3YxVzgumklAwJ0uBe%2FcGT6VeQW%3A1524179765762; __utmb=94650624.24.10.1524176140',
'Host':'music.163.com',
'Referer':'https://music.163.com/',
'Upgrade-Insecure-Requests':'',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
html = requests.get(urls,headers=headers)
html1=etree.HTML(html.text)
html_data=html1.xpath('//div[@class="u-cover u-cover-alb3"]')[0]
pattern = re.compile(r'<div class="u-cover u-cover-alb3" title=(.*?)>')
items = re.findall(pattern, html.text)
cal=0
# 首先删除这个文件,要不然每次都是追加
if(os.path.exists("专辑信息.txt")):
os.remove("专辑信息.txt")
#删除文件避免每次都要重复写入
if (os.path.exists("专辑歌曲信息.txt")):
os.remove("专辑歌曲信息.txt")
for i in items:
cal+=1
#这里需要注意i是有双引号的,所以需要注意转换下
p=i.replace('"','')
#这里在匹配里面使用了字符串,注意下
pattern1=re.compile(r'<a href="/album\?id=(.*?)" class="tit s-fc0">%s</a>'%(p))
id1= re.findall(pattern1,html.text)
# print("专辑的名字是:%s!!专辑的ID是%s:"%(i,items1))
with open("专辑信息.txt",'a') as f:
f.write("专辑的名字是:%s!!专辑的ID是%s \n:"%(i,id1))
f.close()
self.GetLyric1(i,id1)
# print("总数是%d"%(cal))
print("获取专辑以及专辑ID成功!!!!!")
这里面用到了xpath来找到对应标签里面数据,然后把数据放在文件里面。代码不重要,思想懂了就行(代码单独执行可行)
执行结果如下
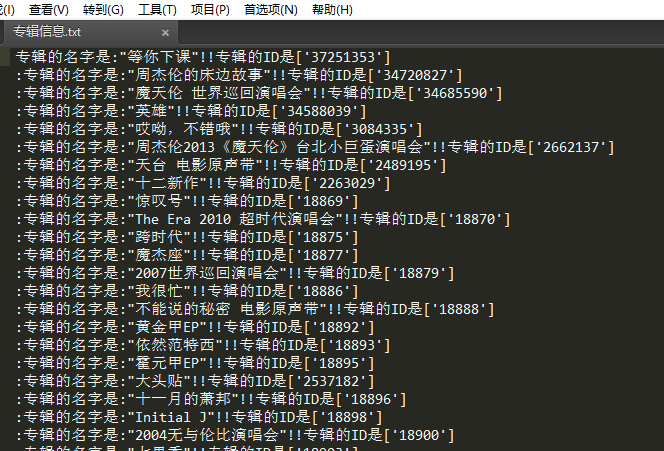
二.抓取歌曲信息。
通过上面我们已经抓取到了专辑的信息,接下来我们就通过专辑,来获取歌曲信息
 看这幅图,我想你已经懂了,页面组成http://music.163.com/#/album?id=!!! !!!这里填写专辑ID,我们在network里面找到了所有歌曲的信息接下来我们看header
看这幅图,我想你已经懂了,页面组成http://music.163.com/#/album?id=!!! !!!这里填写专辑ID,我们在network里面找到了所有歌曲的信息接下来我们看header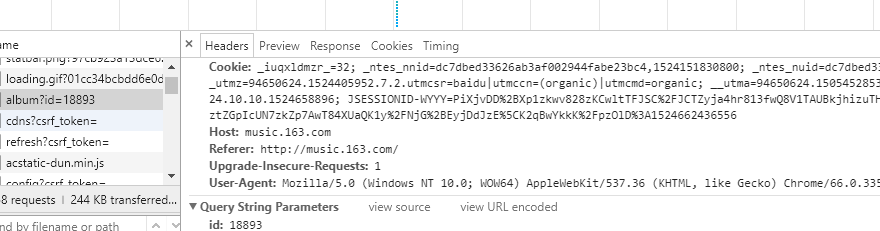 同样的道理我们通过伪造方式发送信息,获取歌曲信息!!直接上代码
同样的道理我们通过伪造方式发送信息,获取歌曲信息!!直接上代码
def GetLyric1(self,album,id1):
urls1 = "http://music.163.com/#/album?id="
urls2 = str(id1)
urls3= urls1+urls2
#将不要需要的符号去掉
urls=urls3.replace("[","").replace("]","").replace("'","").replace("#/","")
headers={
'Cookie': '_iuqxldmzr_=32; _ntes_nnid=dc7dbed33626ab3af002944fabe23bc4,1524151830800; _ntes_nuid=dc7dbed33626ab3af002944fabe23bc4; __utmz=94650624.1524151831.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utma=94650624.1505452853.1524151831.1524176140.1524296365.3; __utmc=94650624; WM_TID=RpKJQQ90pzUSYfuSWgFDY6QEK1Gb4Ulg; JSESSIONID-WYYY=7t6F3r9Uzy8uEXHPnVnWTXRP%5CSXg9U3%5CN8V5AROB6BIe%2B4ie5ch%2FPY8fc0WV%2BIA2ya%5CyY5HUBc6Pzh0D5cgpb6fUbRKMzMA%2BmIzzBcxPcEJE5voa%2FHA8H7TWUzvaIt%2FZnA%5CjVghKzoQXNM0bcm%2FBHkGwaOHAadGDnthIqngoYQsNKQQj%3A1524299905306; __utmb=94650624.21.10.1524296365',
'Host': 'music.163.com',
'Referer': 'http://music.163.com/',
'Upgrade-Insecure-Requests': '',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.117 Safari/537.36'
}
html = requests.get(urls, headers=headers)
html1 = etree.HTML(html.text)
# soup = BeautifulSoup(html1, 'html.parser', from_encoding='utf-8')
# tags = soup.find_all('li', class_="have-img")
html_data = html1.xpath('//ul[@class="f-hide"]//a')
for i in html_data:
#注意这个用法
html_data1=i.xpath('string(.)')
#获取歌曲的id
html_data2=str(html_data1)
pattern1=re.compile(r'<li><a href="/song\?id=(\d+?)">%s</a></li>'%(html_data2))
items = re.findall(pattern1,html.text)
# print("歌曲的名称为: %s"%(html_data2))
# print("歌曲的id为: %s"%(items))
with open("专辑歌曲信息.txt", 'a') as f:
print(len(items))
if (len(items) > 0):
f.write("歌曲的名字是: %s!!歌曲的ID是%s \n" % (html_data2, items))
f.close()
print("获取歌曲 %s 以及歌曲的ID %s写入文件成功"%(html_data2, items))
#http://music.163.com/#/song?id=185617
# if(len())
def GetLyric2(self):
#首先删除原来的文件,避免重复写入
for i in glob.glob("*热评*"):
os.remove(i)
for i in glob.glob("*歌曲名*"):
os.remove(i)
#直接读取所有内容
file_object=open("专辑歌曲信息.txt",)
list_of_line=file_object.readlines()
aaa=1
namelist = ""
for i in list_of_line:
# 歌曲的名字是: 同一种调调!!歌曲的ID是['186020']
pattern1 = re.compile(r'歌曲的名字是: (.*?)!!歌曲的ID是')
pattern2 = re.compile(r'歌曲的ID是\[(.*?)\]')
items1 = str(re.findall(pattern1, i)).replace("[","").replace("]","").replace("'","")
items2 = str(re.findall(pattern2, i)).replace("[","").replace("]","").replace('"',"").replace("'","") headers = {
'Request URL': 'http://music.163.com/weapi/song/lyric?csrf_token=',
'Request Method': 'POST',
'Status Code': '200 OK',
'Remote Address': '59.111.160.195:80',
'Referrer Policy': 'no-referrer-when-downgrade'
}
# http://music.163.com/api/song/lyric?id=186017&lv=1&kv=1&tv=-1
urls="http://music.163.com/api/song/lyric?"+"id="+str(items2)+'&lv=1&kv=1&tv=-1'
# urls = "http://music.163.com/api/song/lyric?id=186018&lv=1&kv=1&tv=-1"
#print(urls)
html = requests.get(urls, headers=headers)
json_obj = html.text
j = json.loads(json_obj)
try:
lrc = j['lrc']['lyric']
pat = re.compile(r'\[.*\]')
lrc = re.sub(pat,"",lrc)
lrc = lrc.strip()
print(lrc)
lrc = str(lrc)
with open("歌曲名-"+items1+".txt", 'w',encoding='utf-8') as f:
f.write(lrc)
aaa+=1
namelist=namelist + items1 + ".txt"+","
#调用获取评论方法,并且把热评写入文件
self.GetCmmons(items1,items2)
except:
print("歌曲有错误 %s !!"%(items1))
#读取所有文件,并且把所有的信息输入到一个文件里面去
# html1 = etree.HTML(html.text)
print("歌曲一共爬取了%s首 "%(aaa))
print(namelist)
上面需要注意:xpath来获取需要的信息,利用正则来获取ID(其实有很多方法)
结果如下 ,
,
同样的方法!!我们打开一首歌曲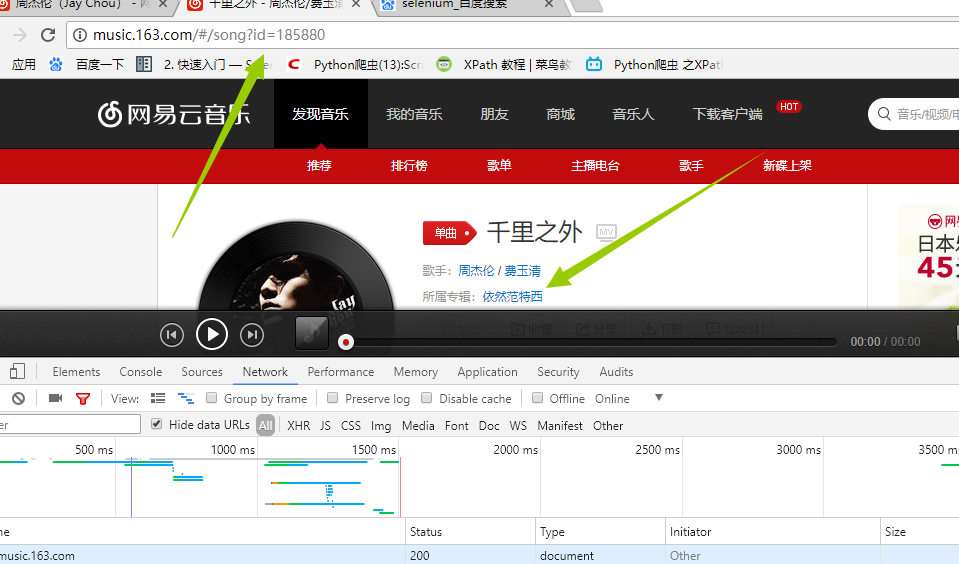 一样的道理,我们分析network来获取我们需要的信息歌词,评论!!直接上代码
一样的道理,我们分析network来获取我们需要的信息歌词,评论!!直接上代码
def GetCmmons(self,name,id):
self.name=name
self.id=id
#删除原来的文件 避免重复爬取
# urls="http://music.163.com/weapi/v1/resource/comments/R_SO_4_415792918?csrf_token="
urls="http://music.163.com/api/v1/resource/comments/R_SO_4_"+str(id)
headers={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': '_iuqxldmzr_=32; _ntes_nnid=dc7dbed33626ab3af002944fabe23bc4,1524151830800; _ntes_nuid=dc7dbed33626ab3af002944fabe23bc4; __utmz=94650624.1524151831.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); WM_TID=RpKJQQ90pzUSYfuSWgFDY6QEK1Gb4Ulg; JSESSIONID-WYYY=BgqSWBti98RpkHddEBZcxnxMIt4IdbCqXGc0SSxKwvRYlqbXDAApbgN%2FQWQ8vScdXfqw7adi2eFbe30tMZ13mIv9XOAv8bhrQYC6KRajksuYWVvTbv%2BOu5oCypc4ylh2Dk5R4TqHgRjjZgqFbaOF73cJlSck3lxcFot9jDmE9KWnF%2BCk%3A1524380724119; __utma=94650624.1505452853.1524151831.1524323163.1524378924.5; __utmc=94650624; __utmb=94650624.8.10.1524378924',
'Host': 'music.163.com',
'Upgrade-Insecure-Requests': '',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.117 Safari/537.36'
}
html = requests.get(urls,headers=headers)
html.encoding= 'utf8'
# html_data = html1.xpath('//div[@class="u-cover u-cover-alb3"]')[0]
# pattern = re.compile(r'<div class="u-cover u-cover-alb3" title=(.*?)>')
#items = re.findall(pattern, html.text)
#print(html.text)
#使用json格式化输出
json_obj = html.text
j = json.loads(json_obj)
i=j['hotComments']
for uu in i:
username=uu["user"]['nickname']
likedCount1 = str(uu['likedCount'])
comments=uu['content']
with open(name + "的热评hotComment" +".txt" , 'a+',encoding='utf8') as f:
f.write("用户名是 "+username+"\n")
f.write("用户的评论是 "+comments+"\n")
f.write("被点赞的次数是 " + str(likedCount1) +"\n")
f.write("----------华丽的的分割线-------------"+"\n")
f.close()
上面需要注意的是:利用json获取需要的数据(至少比正则快点)
结果如下:
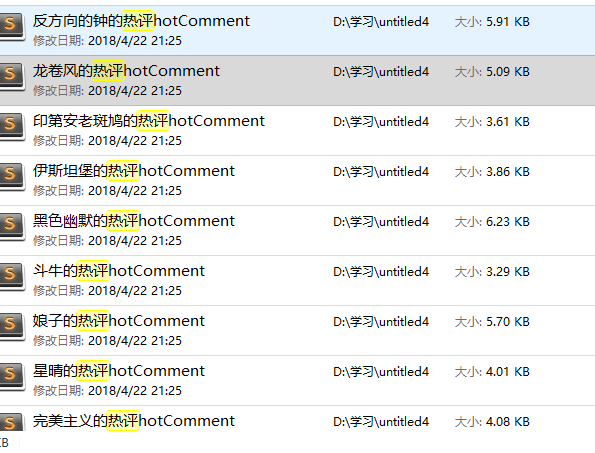

到这里!!我们已经完成了所有用数据的爬取,数据大体如下
三 数据分析,可视化
如果数据不利用,就如同一张白纸一样,毫无意义。接下来我们就对数据进行全面的分析
第一步,我们先进行歌词的分析,先把数据合并到一个文件里
def MergedFile(self):
aaa=0
for i in glob.glob("*歌曲名*"):
file_object = open(i,'r',encoding='UTF-8')
list_of_line = file_object.readlines()
for p in list_of_line:
if "作词" in p or "作曲" in p or "混音助理" in p or "混音师" in p or "录音师" in p or "执行制作" in p or "编曲" in p or "制作人" in p or "录音工程" in p or "录音室" in p or "混音录音室" in p or "混音工程" in p or "Programmer" in p or p == "\n" or "和声" in p or "吉他" in p or "录音助理" in p or "陈任佑鼓" in p or "周杰伦" in p:
aaa+=1
print(p)
else:
with open ("allLyric"+".txt","a",encoding='UTF-8') as f :
f.write(p)
f.write("\n")
print(aaa)
#合并歌曲
file1 = open('allLyric.txt', 'r', encoding='utf-8') # 要去掉空行的文件
file2 = open('allLyric1.txt', 'w', encoding='utf-8') # 生成没有空行的文件
try:
for line in file1.readlines():
if line == '\n':
line = line.strip("\n")
file2.write(line)
finally:
file1.close()
file2.close()
print("合并歌词文件完成")
上面需要注意的是:我们合并数据的时候,可以选择性的删除一些无用数据(也就是上面那一大串for,麻瓜式的删除)
结果如下
OK 歌词清洗完成之后,我们对周杰伦歌曲进行情绪化分析,在进行情绪化分析的时候,有很多工具可以选择,我这边选择的是SnowNLP这个三方工具,具体代码如下:
def EmotionAnalysis(self):
from snownlp import SnowNLP
from pyecharts import Bar
xzhou=[]
yzhou=[]
for i in glob.glob("*歌曲名*"):
count=0
allsen=0
with open(i,'r', encoding='utf-8') as fileHandel:
fileList = fileHandel.readlines()
for p in fileList:
if "作词" in p or "作曲" in p or "鼓" in p or "混音师" in p or "录音师" in p or "执行制作" in p or "编曲" in p or "制作人" in p or "录音工程" in p or "录音室" in p or "混音录音室" in p or "混音工程" in p or "Programmer" in p or p == "\n":
pass
else:
s = SnowNLP(p)
# print(s.sentences[0])
s1 = SnowNLP(s.sentences[0])
#print(type(s1))
count+=1
allsen+=s1.sentiments
i=str(i)
xzhou1 = i.split("-", 1)[1].split(".",1)[0]
xzhou.append(xzhou1)
avg=int(allsen)/count
yzhou.append(avg)
#print("%s这首歌的情绪为%s"%(i,avg))
fileHandel.close()
bar = Bar("柱状图数据堆叠示例")
bar.add("周杰伦歌曲情绪可视化", xzhou, yzhou, is_stack=True,xaxis_interval=0)
bar.render(r"D:\学习\untitled4\allpicture\周杰伦歌曲情绪全部.html")
#显示最好的前五首歌
import heapq
yzhou1 = heapq.nlargest(10, yzhou)
temp = map(yzhou.index, heapq.nlargest(10, yzhou))
temp = list(temp)
xzhou1 = []
for i in temp:
xzhou1.append(xzhou[i])
# 情绪前十首歌个图
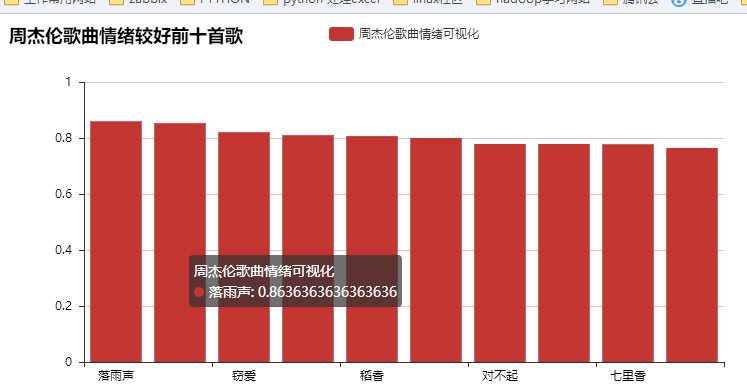
bar = Bar("周杰伦歌曲情绪较好前十首歌")
bar.add("周杰伦歌曲情绪可视化", xzhou1, yzhou1, is_stack=True)
bar.render(r"D:\学习\untitled4\allpicture\周杰伦歌曲最积极情绪top10.html")
#显示最差的十首歌
yzhou1 = heapq.nsmallest(10, yzhou)
temp = map(yzhou.index, heapq.nsmallest(10, yzhou))
temp = list(temp)
xzhou1 = []
for i in temp:
xzhou1.append(xzhou[i])
# print(xzhou1)
#print(yzhou1)
# 情绪前十首歌个图
bar = Bar("周杰伦歌曲情绪较差前十首歌")
bar.add("周杰伦歌曲情绪可视化",xzhou1, yzhou1,xaxis_interval=0,xzhou1_label_textsize=6)
bar.render(r"D:\学习\untitled4\allpicture\周杰伦歌曲最消极情绪top10.html")
print(xzhou1)
下面完成数据词频各种分析,这些基于数据source的统计用很多方法,我这边做为小白只能用比较傻瓜一点的,具体代码如下:
#定义结巴分词的方法以及处理过程
def splitSentence(self,inputFile, outputFile):
fin = open(inputFile, 'r', encoding='utf-8')
fout = open(outputFile, 'w', encoding='utf-8')
for line in fin:
line = line.strip()
line = jieba.analyse.extract_tags(line)
outstr = " ".join(line)
fout.write(outstr + '\n')
fin.close()
fout.close()
#下面的程序完成分析前十的数据出现的次数
f = open("分词过滤后.txt", 'r', encoding='utf-8')
a = f.read().split()
b = sorted([(x, a.count(x)) for x in set(a)], key=lambda x: x[1], reverse=True)
print(sorted([(x, a.count(x)) for x in set(a)], key=lambda x: x[1], reverse=True)) #输出频率最多的前十个字,里面调用splitSentence完成频率出现最多的前十个词的分析
def LyricAnalysis(self):
import jieba
file = 'allLyric1.txt'
#这个技巧需要注意
alllyric = str([line.strip() for line in open('allLyric1.txt',encoding="utf-8").readlines()])
#获取全部歌词,在一行里面
alllyric1=alllyric.replace("'","").replace(" ","").replace("?","").replace(",","").replace('"','').replace("?","").replace(".","").replace("!","").replace(":","")
# print(alllyric1)
#在这里用结巴分词来分词过滤并且输出到一个文件里面,这个ting.txt
#import jieba.analyse 这里必须引入
jieba.analyse.set_stop_words("ting.txt")
self.splitSentence('allLyric1.txt', '分词过滤后.txt')
#下面是词频统计
import collections
# 读取文本文件,把所有的汉字拆成一个list
f = open("分词过滤后.txt", 'r', encoding='utf8') # 打开文件,并读取要处理的大段文字
txt1 = f.read()
txt1 = txt1.replace('\n', '') # 删掉换行符
txt1 = txt1.replace(' ', '') # 删掉换行符
txt1 = txt1.replace('.', '') # 删掉逗号
txt1 = txt1.replace('.', '') # 删掉句号
txt1 = txt1.replace('o', '') # 删掉句号
mylist = list(txt1)
mycount = collections.Counter(mylist)
for key, val in mycount.most_common(10): # 有序(返回前10个)
print(key, val)
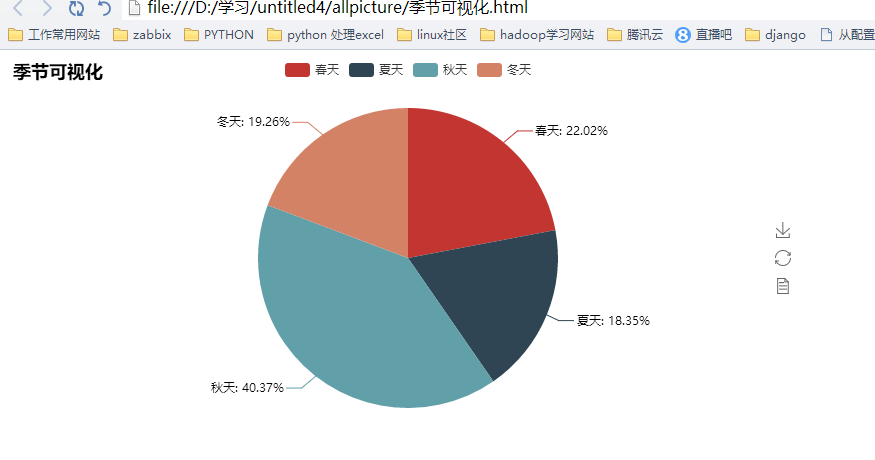
接下来我们需要进行天气,词云化数据,比如这里的天气我选择了用shell完成统计。-----cat XXXX | grep 秋天 | wc -l 这样一句话就OK 了,没必要再使用python3 物尽其用,方得正果:这些可视化的代码都很类似,就不全部列出来了。放一个示例吧:
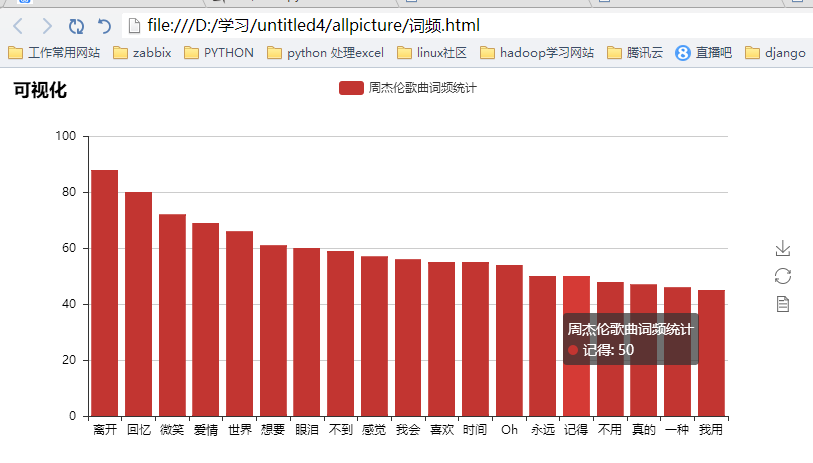
from pyecharts import WordCloud name = [
"离开", "回忆", "微笑", "爱情", "世界", "想要", "眼泪", "不到", "感觉", "我会", "喜欢", "时间", "Oh", "永远", "oh", "记得", "不用", "真的", "一种",
"我用", "等待", "慢慢", "故事", "看着", "一点", "笑容", "音乐", "温柔", "画面", "不想", "可爱", "天空", "声音", "身边", "远方", "只能", "忘记", "思念",
"沉默", "女人", "幸福", "也许", "快乐", "感动", "难过", "跟着", "月光", "一场", "阳光", "表情", "打开", "Music", "安静", "一路", "明白", "放弃", "温暖",
"心碎", "眼睛", "弦乐", "味道", "从前", "我要", "习惯", "回到", "一遍", "简单", "伤心", "灵魂", "自由", "一口", "生命", "甜蜜", "拥有", "风景", "距离",
"生活", "美"
]
value = [
88, 80, 72, 69, 66, 61, 60, 59, 57, 56, 55, 55, 54, 50, 50, 48, 47, 46, 45, 42, 41, 40, 38, 38, 37, 37, 37, 36, 36,
36, 36, 35, 34, 34, 34, 32, 32, 32, 31, 31, 30, 30, 29, 29, 29, 28, 28, 28, 28, 28, 28, 26, 26, 26, 25, 25, 25, 25,
25, 24, 24, 24, 24, 24, 24, 24, 24, 23, 23, 23, 23, 23, 22, 22, 22, 22, 22, 22]
wordcloud = WordCloud(width=1300, height=620)
wordcloud.add("", name, value,shape='diamond', word_size_range=[20, 100])
wordcloud.render(r"D:\学习\untitled4\allpicture\歌词词云.html")
好了!!其实分析语法没那么重要,实验的方法也很多!!
我们来看下可视化的结果吧
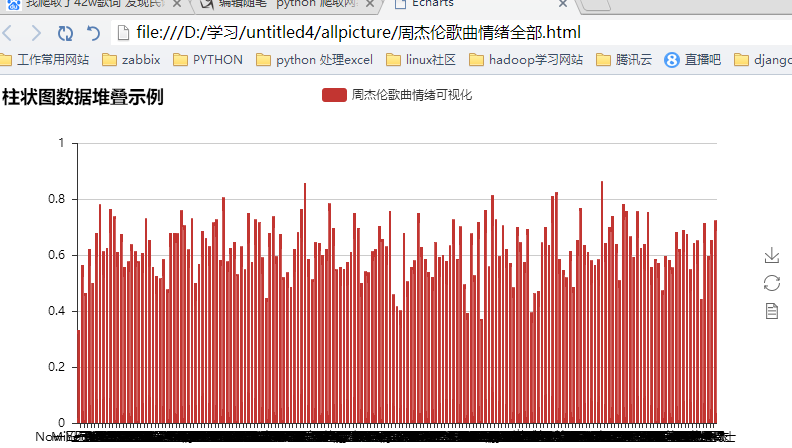
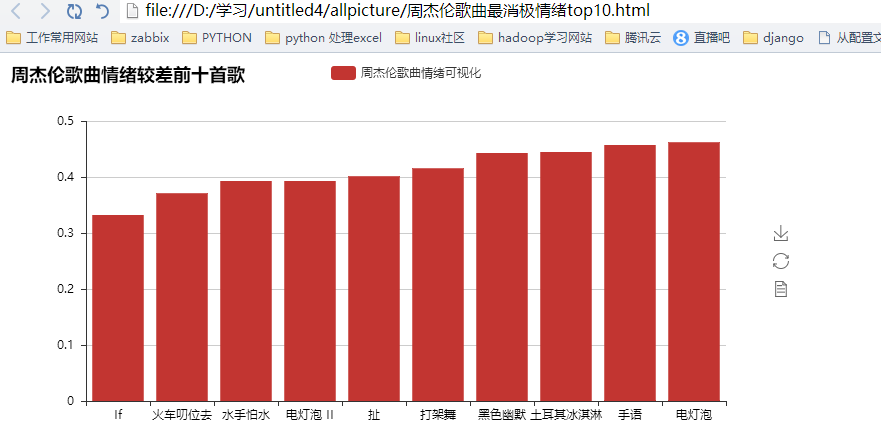

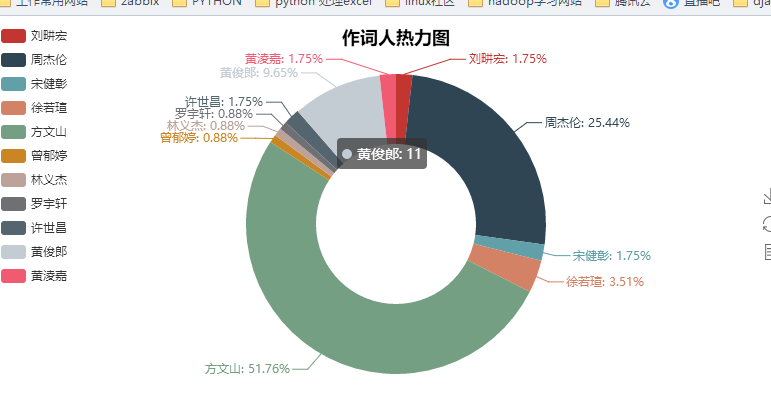
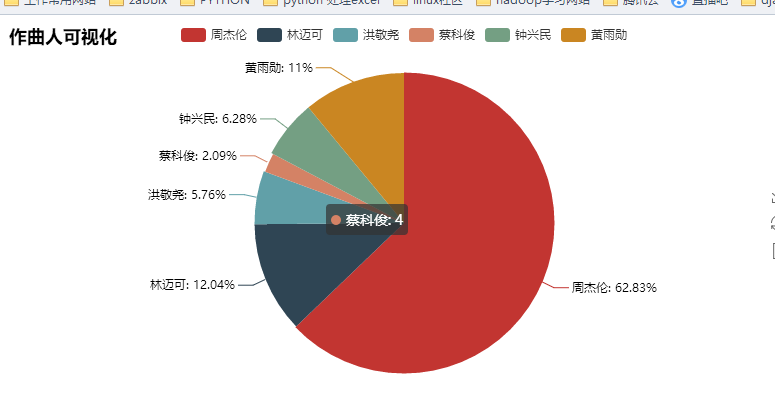
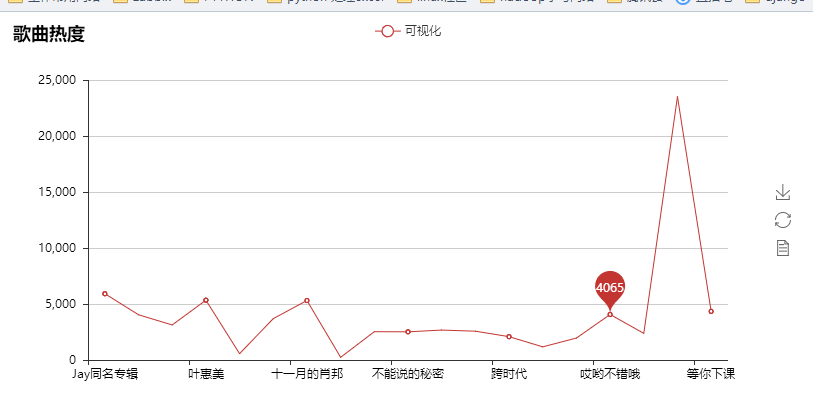
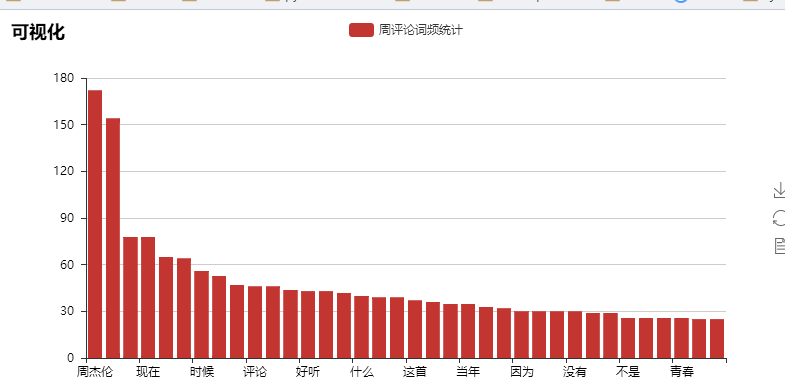

其实爬取了很多内容,但是利用的不是很多,以后再来详解吧
在进行数据可视化的过程中我真的发现pyecharts是一个非常nice的工具!!!!collection
利用python3 爬取 网易云 上 周杰伦所有专辑,歌曲,评论,并完成可视化分析已经歌曲情绪化分析的更多相关文章
- 如何用Python网络爬虫爬取网易云音乐歌曲
今天小编带大家一起来利用Python爬取网易云音乐,分分钟将网站上的音乐down到本地. 跟着小编运行过代码的筒子们将网易云歌词抓取下来已经不再话下了,在抓取歌词的时候在函数中传入了歌手ID和歌曲名两 ...
- python爬取网易云周杰伦所有专辑,歌曲,评论,并完成可视化分析
---恢复内容开始--- 去年在网络上有一篇文章特别有名:我分析42万字的歌词,为搞清楚民谣歌手们在唱些什么.这篇文章的作者是我大学的室友,随后网络上出现了各种以为爬取了XXX,发现了XXX为名的文章 ...
- python爬虫+词云图,爬取网易云音乐评论
又到了清明时节,用python爬取了网易云音乐<清明雨上>的评论,统计词频和绘制词云图,记录过程中遇到一些问题 爬取网易云音乐的评论 一开始是按照常规思路,分析网页ajax的传参情况.看到 ...
- 爬虫实战(二) 用Python爬取网易云歌单
最近,博主喜欢上了听歌,但是又苦于找不到好音乐,于是就打算到网易云的歌单中逛逛 本着 "用技术改变生活" 的想法,于是便想着写一个爬虫爬取网易云的歌单,并按播放量自动进行排序 这篇 ...
- Python爬取网易云歌单
目录 1. 关键点 2. 效果图 3. 源代码 1. 关键点 使用单线程爬取,未登录,爬取网易云歌单主要有三个关键点: url为https://music.163.com/discover/playl ...
- 爬取网易云音乐评论!python 爬虫入门实战(六)selenium 入门!
说到爬虫,第一时间可能就会想到网易云音乐的评论.网易云音乐评论里藏了许多宝藏,那么让我们一起学习如何用 python 挖宝藏吧! 既然是宝藏,肯定是用要用钥匙加密的.打开 Chrome 分析 Head ...
- Python 爬取网易云歌手的50首热门作品
使用 requests 爬取网易云音乐 Python 代码: import json import os import time from bs4 import BeautifulSoup impor ...
- 用Python爬取网易云音乐热评
用Python爬取网易云音乐热评 本文旨在记录Python爬虫实例:网易云热评下载 由于是从零开始,本文内容借鉴于各种网络资源,如有侵权请告知作者. 要看懂本文,需要具备一点点网络相关知识.不过没有关 ...
- Python爬取网易云热歌榜所有音乐及其热评
获取特定歌曲热评: 首先,我们打开网易云网页版,击排行榜,然后点击左侧云音乐热歌榜,如图: 关于如何抓取指定的歌曲的热评,参考这篇文章,很详细,对小白很友好: 手把手教你用Python爬取网易云40万 ...
随机推荐
- antd二级联动异步加载
/** * Created by Admin on 2016/9/19. * 批量导入 */ import React, {Component, PropTypes} from "react ...
- 配置Xmanager远程登录
1.修改/etc/gdm/custom.conf文件找到下面的语句:[security]AllowRemoteRoot=true[xdmcp]Enable=true修改custom.conf后,必须重 ...
- 利用matlab自带函数graycoprops 实现基于共生矩阵的遥感图像纹理特征分析
close all;clear all;clc;I = imread('yaogan2.jpg');HSV = rgb2hsv(I);Hgray = rgb2gray(HSV);% 计算64位灰度共生 ...
- 查看创世区块 Genesis Block和channel.tx文件
将 Block 详细内容导入到 json 文件查看 configtxgen -inspectBlock channel-artifacts/genesis.block > genesis.blo ...
- 在vue的element图片的上传及回调
首先声明,本人用的是element组件写的图片的上传及回调,若非element本方法暂不支持. 下面开始正式讲图片的上传及回调.(本篇拒绝一切花里胡哨,都是干活,言辞粗糙,望请见谅) 1,elemen ...
- Linux安装jemalloc笔记
前言 最近研究一个工具库需要用 jemalloc 做内存分配器,但在 ubuntu 下安装过程中遇到很多问题,故记下安装过程的笔记,避免以后遇到在这上面浪费时间. 安装过程 环境:VMware Ubu ...
- 牛客小白月赛16 H 小阳的贝壳 (差分+线段树)
链接:https://ac.nowcoder.com/acm/contest/949/H来源:牛客网 题目描述 小阳手中一共有 n 个贝壳,每个贝壳都有颜色,且初始第 i 个贝壳的颜色为 colico ...
- 24.Azkaban调度脚本的编写
启动azkaban 在启动了server和excutor之后,在浏览器打开azkaban,会发现不能打开,日志报这个错误 at sun.security.ssl.InputRecord.handleU ...
- Java基础语法知识你真的都会吗?
第一阶段 JAVA基础知识 第二章 Java基础语法知识 在我们开始讲解程序之前,命名规范是我们不得不提的一个话题,虽说命名本应该是自由的,但是仍然有一定的"潜规则",通过你对命名 ...
- 用JavaScript写一个简单的倒计时,可以应用在发送短信验证码的“59秒后重新发送验证短信”
倒计时——从10倒数到0,点击按钮会还原倒计时 <body> <!-- 将textvalue值设为10,从10倒数 --> <input type="text& ...