分词搜索 sphinx3.1.1+php+mysql
sphinx3.1.1的安装与使用
- 下载sphinx3.1.1
- wget http://sphinxsearch.com/files/sphinx-3.1.1-612d99f-linux-amd64.tar.gz
- 解压
- tar zxf sphinx-3.1.1-612d99f-linux-amd64.tar.gz
- 改名 sphinx 并移动到 /usr/local/
- mv sphinx-3.1.1 sphinx
- mv sphinx /usr/local/
- 到sphinx目录下创建 data,log文件夹
- cd /usr/local/sphinx
- mkdir data && mkdir log
- 在/usr/local/sphinx/etc 编写 sphinx.conf 配置文件
- vim /usr/local/sphinx/etc/sphinx.conf
# # Minimal Sphinx configuration sample (clean, simple, functional) # source src1 { type = mysql sql_host = localhost sql_user = root sql_pass = root sql_db = test sql_port = # optional, default is sql_query_pre = SET NAMES utf8 sql_query = \ SELECT id, group_id, UNIX_TIMESTAMP(date_added) AS date_added, title, content \ FROM documents sql_attr_uint = group_id sql_attr_timestamp = date_added } index test1 { source = src1 path = /usr/local/sphinx/data/test1 min_word_len = ngram_len = ngram_chars = U+..U+2FA1F } indexer { mem_limit = 128M } searchd { listen = listen = :mysql41 log = /usr/local/sphinx/log/searchd.log query_log = /usr/local/sphinx/log/query.log read_timeout = max_children = pid_file = /usr/local/sphinx/log/searchd.pid seamless_rotate = preopen_indexes = unlink_old = binlog_path = /usr/local/sphinx/data/ }- 在test数据库中 运行/usr/local/sphinx/etc目录下的example.sql文件
- 进入mysql
- use test;
- source /usr/local/sphinx/etc/example.sql
- 添加索引
- /usr/local/sphinx/bin/indexer -c /usr/local/sphinx/etc/sphinx.conf test1
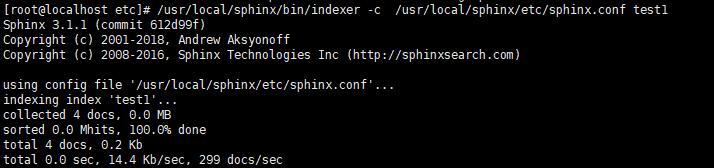
- /usr/local/sphinx/bin/indexer -c /usr/local/sphinx/etc/sphinx.conf test1 --rotate // 重新生成索引命令
- 运行sphinx
- /usr/local/sphinx/bin/searchd -c /usr/local/sphinx/etc/sphinx.conf
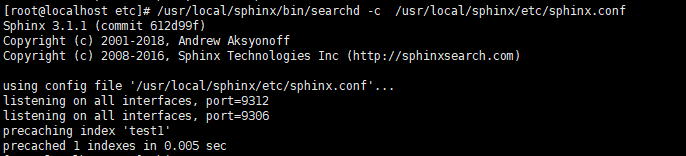
/usr/local/sphinx/bin/searchd -c /usr/local/sphinx/etc/sphinx.conf --stop //停止sphinx命令
- php操作sphinx
- 复制/usr/local/sphinx/api/ 目录下的 sphinxapi.php
$sphinx = new SphinxClient(); $q = $_GET['key'] ?? 'test'; //搜索关键字// 3.1已经弃用了setMatchMode!直接写查询语法就可以// 如果要匹配字符串中任意一个词或字使用如下写法// '"string1" | "string2" | "string3"' // '@(title,content) string' @括号中的是要搜索的字段 可以写多个或单个 // '^$string$' 表示全部匹配 类似mysql中的 fieldName = 'string'// 更多用法可以参考正则表达式或者官方文档 // 中文分词扩展建议使用scws,官网安装和使用教程说明很详细,(不过sphinx自带的一元分词已经够用了,一般不需要scws//http://www.xunsearch.com/scws/ $sql = ""; $host = "127.0.0.1"; $port = 9312; $index = "test1"; $sphinx->SetServer($host, $port); $sphinx->SetConnectTimeout(10); $sphinx->SetArrayResult(true); $res = $sphinx->Query($q, $index); print_r($res);
运行结果如下:
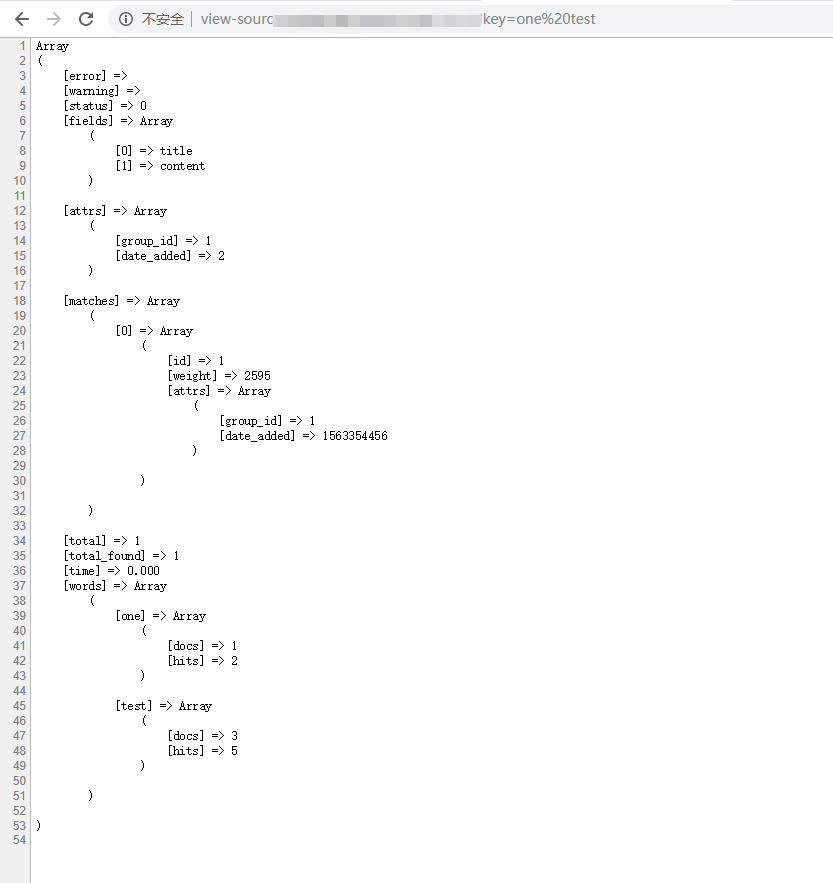
结束,记得数据库数据改变后需重新生成索引
分词搜索 sphinx3.1.1+php+mysql的更多相关文章
- linux环境下安装sphinx中文支持分词搜索(coreseek+mmseg)
linux环境下安装sphinx中文支持分词搜索(coreseek+mmseg) 2013-11-10 16:51:14 分类: 系统运维 为什么要写这篇文章? 答:通过常规的三大步(./confi ...
- Sphinx + Coreseek 实现中文分词搜索
Sphinx + Coreseek 实现中文分词搜索 Sphinx Coreseek 实现中文分词搜索 全文检索 1 全文检索 vs 数据库 2 中文检索 vs 汉化检索 3 自建全文搜索与使用Goo ...
- ECSHOP模糊分词搜索和商品列表关键字飘红功能
ECSHOP联想下拉框 1.修改page_header.lbi模版文件,将搜索文本框修改为: <input name="keywords" type="text&q ...
- 【netcore基础】.Net core通过 Lucene.Net 和 jieba.NET 处理分词搜索功能
业务要求是对商品标题可以进行模糊搜索 例如用户输入了[我想查询下雅思托福考试],这里我们需要先将这句话分词成[查询][雅思][托福][考试],然后搜索包含相关词汇的商品. 思路如下 首先我们需要把数据 ...
- 实操重写IK分词器源码,基于mysql热更新词库
实操重写IK分词器源码,基于mysql热更新词库参考网址:https://blog.csdn.net/wuzhiwei549/article/details/80451302 问题一:按照这篇文章的介 ...
- 32.修改IK分词器源码来基于mysql热更新词库
主要知识点, 修改IK分词器源码来基于mysql热更新词库 一.IK增加新词的原因 在第32小节中学习到了直接在es的词库中增加词语,来扩充自已的词库,但是这样做有以下缺点: (1)每次添加完 ...
- ElasticSearch 中文分词搜索环境搭建
ElasticSearch 是强大的搜索工具,并且是ELK套件的重要组成部分 好记性不如乱笔头,这次是在windows环境下搭建es中文分词搜索测试环境,步骤如下 1.安装jdk1.8,配置好环境变量 ...
- 分词搜索 sphinx+php+mysql
sphinx3.1.1的安装与使用 下载sphinx3.1.1 wget http://sphinxsearch.com/files/sphinx-3.1.1-612d99f-linux-amd64. ...
- Solr分词搜索结果不准确
Solr的schema.xml默认配置分词后条件取 OR 例如:大众1.6T 系统会自动分词为 [大众] [1.6T](ps:不同分词器分词效果不同) 会搜索出包含 [大众 OR 1.6T] ...
随机推荐
- Little Prince
You know — one loves the sunset, when one is so sad... 你知道的—当一个人情绪低落的时候,他会格外喜欢看日落...... If someone l ...
- 初次接触python,怎么样系统的自学呢?
关注专栏 写文章登录 给伸手党的福利:Python 新手入门引导 Crossin 2 个月前 这是一篇 Python 入门指南,针对那些没有任何编程经验,从零开始学习 Python 的同学.不管你 ...
- ie中兼容性问题
由于项目要要兼容到ie8原本没有问题的代码一但用ie8打开js的报错找不到对象就都来了,其实总结起来就是ie越老的版本就越多方法名识别不到,那就少什么方法添加什么,比如说我的项目就要引入<scr ...
- linux不能ping通主机,主机能ping通linux
1).打开控制面板,点击“系统和安全”选项.然后打开“Windows防火墙”.2).点击进入“高级设置”,选择“入站规则”.3).在入门规则中找到“文件和打印机共享(回显请求-ICMPv4-In)”选 ...
- 移动端——meta标签
meta标签主要辅助HTML结构层的.meta标签不管在互联网前端还是在移动端都起了很重要的作用. <meta http-equiv="Content-type" conte ...
- 【Webscraper】不懂编程也能爬虫
一.配置环境 在浏览器中安装web scraper插件. 所有安装包下载链接: https://pan.baidu.com/s/1CfAWf0wMO6WqicoUgdYgkg 提取码: nn2e 安装 ...
- PCL已有点类型介绍和增加自定义的点类型
博客转载自:http://www.pclcn.org/study/shownews.php?lang=cn&id=265 本小节不仅解释如何增加你自己的PointT点类型,也介绍了PCL中的模 ...
- PCL中有哪些可用的PointT类型(3)
博客转载自:http://www.pclcn.org/study/shownews.php?lang=cn&id=268 PointXYZRGBNormal - float x, y, z, ...
- RabbitMQ学习之:(七)Fanout Exchange (转贴+我的评论)
From:http://lostechies.com/derekgreer/2012/05/16/rabbitmq-for-windows-fanout-exchanges/ PunCha: Ther ...
- excel怎么设置密码保护?Excel文件添加密码保护教程
excel怎么设置密码保护?Excel文件添加密码保护教程 众所周知,Excel具有强大的数据处理和数据分析能力,广泛应用于加工学统计及金融统计中.特别是金融统计需要较高的安全性,那么就一定要为Exc ...