简单爬虫 -- 以爬取NASA AOD数据(TIFF文件)为例
目录:
- 网站分析
- 爬取下载链接
- 爬取TIFF图片
1、网站分析
主页面:https://neo.sci.gsfc.nasa.gov/view.php?datasetId=MYDAL2_M_AER_OD
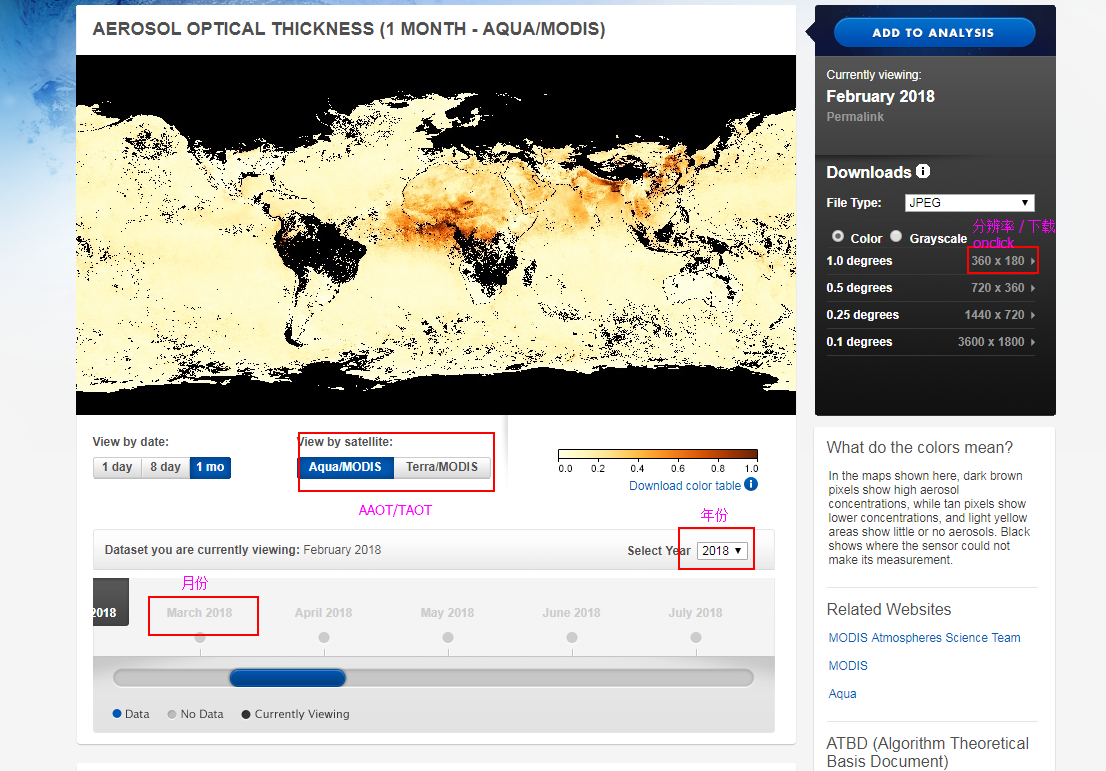
需求:下载不同年份、不同月份、AAOT和TAOT数据;
点击AAOT和TAOT和年份可知,链接:
AAOT:https://neo.sci.gsfc.nasa.gov/view.php?datasetId=MYDAL2_M_AER_OD&year=
TAOT:https://neo.sci.gsfc.nasa.gov/view.php?datasetId=MODAL2_M_AER_OD&year=
AAOT和TAOT的区分:改变MYD和MOD;
年份区分:改变“year=”后面的数字;
月份如何区分?
点击下载处,链接为:
https://neo.sci.gsfc.nasa.gov/servlet/RenderData?si=&cs=rgb&format=FLOAT.TIFF&width=360&height=180
https://neo.sci.gsfc.nasa.gov/servlet/RenderData?si=&cs=rgb&format=FLOAT.TIFF&width=360&height=180
可知在下载链接里面“si=”后面的数字是不知道的,查看源代码,检查上图中月份处,发现这个数字就在这里:这个就是月份区分

分析完毕,爬取思路:
- 根据月份检查元素获取图片下载链接中的“si”,构建所有的下载链接;
- 下载已爬取的下载链接中的TIFF图片
2、爬取下载链接
由以上的分析,代码如下,这里爬取的是2008-2011的AAOT和TAOT数据链接:
import requests
from bs4 import BeautifulSoup as bsp def url_collect():
// 两个主链接
taot_main_url = 'https://neo.sci.gsfc.nasa.gov/view.php?datasetId=MODAL2_M_AER_OD&year='
aaot_main_url = 'https://neo.sci.gsfc.nasa.gov/view.php?datasetId=MYDAL2_M_AER_OD&year=' // 需要下载的年份
years = ['', '', '', ''] // 构造确定AOT类别和年份页面链接
aot_url_list = []
for year in years:
aot_url_list.append(taot_main_url + year)
aot_url_list.append(aaot_main_url + year) for aot_url in aot_url_list:
// 请求获取网页
try:
response = requests.get(aot_url)
response.raise_for_status()
print('aot_url connect succeed !')
except:
print('aot_url connect failed !') // 分析网页,获取代表月份的“si=”后面的数字
response_text = response.text
soup = bsp(response_text, 'html.parser')
divs = soup.find_all('div',{"class":"slider-elem month"}) // 创建保存链接和命名形式的文件
url_txt = open('D:/home/research/lung_cancer/code/aot_url_all.txt', 'a')
url_name_txt = open('D:/home/research/lung_cancer/code/url_name.txt', 'a') // 构造下载链接和命名形式,并保存到文件中
for div in divs:
print(div)
aot_url_txt = 'https://neo.sci.gsfc.nasa.gov/servlet/RenderData?si=' + div.a['onclick'][13:20] + '&cs=rgb&format=FLOAT.TIFF&width=360&height=180'
name = aot_url.split('?')[1][10:] + div.a['onclick'][27:-3] + '.TIFF'
url_txt.write(aot_url_txt + '\n')
url_name_txt.write(name + '\n')
以下是爬取的结果:
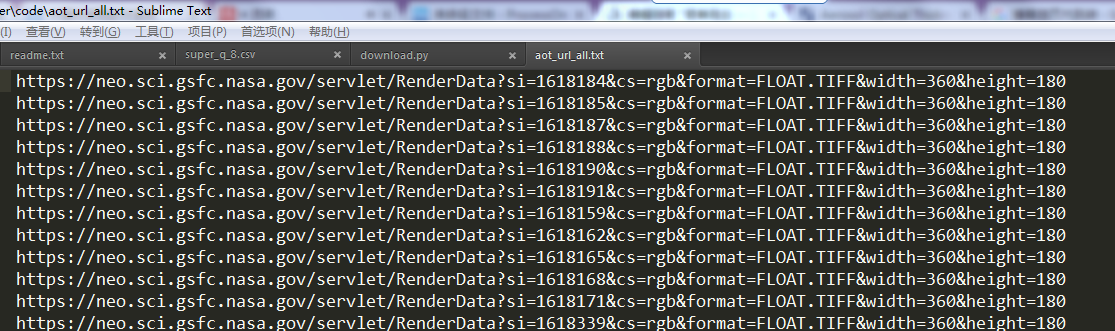
Q:为什么要把命名形式也写入文件?
A:因为下载文件时,发现命名形式并不固定,有时候包含了年、月和AOT类别,有时候就是个简单的RenderData.TIFF,这样文件下载下来了也不知道是什么数据,所以命名很重要。
3、爬取TIFF图片
根据上一步爬取下来的链接,就可开始爬取图片了:
# code : utf-8 """
下载指定链接(在文本文件中)下的tiff图像
""" import requests def download():
local_path = 'D:/home/research/lung_cancer/code/' // 读取文本文件中已经下载好的链接
url_list = []
with open(local_path + 'aot_url_all.txt', 'r') as f:
for url in f.readlines():
url_list.append(url.strip()) // 读取命名形式
name_list = []
with open(local_path + 'url_name.txt', 'r') as f:
for name in f.readlines():
name_list.append(name.strip()) // 获取以上链接中的TIFF文件
for i in range(len(url_list)):
url = url_list[i]
name = name_list[i] try:
response = requests.get(url)
response.raise_for_status()
print('main_url connect succeed !')
except:
print('main_url connect failed !') // 将文件写入本地硬盘
with open('D:/home/research/lung_cancer/data/AOD_process/' + name, 'wb') as f:
f.write(response.content)
print(name + "write succeed!")
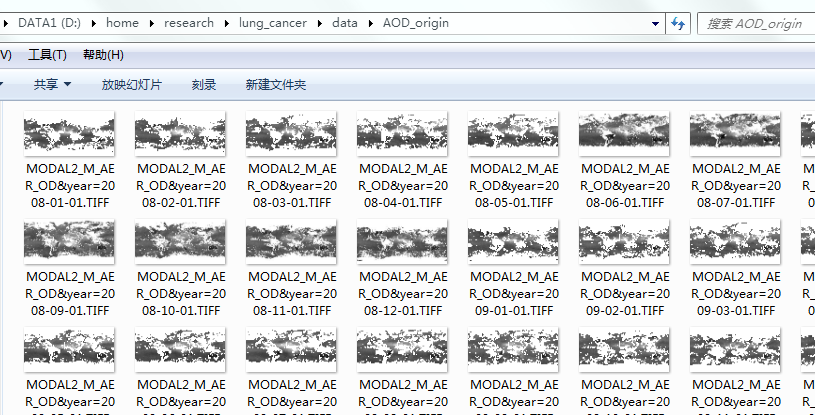
爬取结果:
简单爬虫 -- 以爬取NASA AOD数据(TIFF文件)为例的更多相关文章
- python爬虫25 | 爬取下来的数据怎么保存? CSV 了解一下
大家好 我是小帅b 是一个练习时长两年半的练习生 喜欢 唱! 跳! rap! 篮球! 敲代码! 装逼! 不好意思 我又走错片场了 接下来的几篇文章 小帅b将告诉你 如何将你爬取到的数据保存下来 有文本 ...
- node 爬虫 --- 将爬取到的数据,保存到 mysql 数据库中
步骤一:安装必要模块 (1)cheerio模块 ,一个类似jQuery的选择器模块,分析HTML利器. (2)request模块,让http请求变的更加简单 (3)mysql模块,node连接mysq ...
- Python爬虫:爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一 ...
- python简单爬虫(爬取pornhub特定关键词的items图片集)
请提前搭好梯子,如果没有梯子的话直接403. 1.所用到的包 requests: 和服务器建立连接,请求和接收数据(当然也可以用其他的包,socket之类的,不过requests是最简单好用的) Be ...
- java爬虫,爬取当当网数据
背景:女票快毕业了(没错!我是有女票的!!!),写论文,主题是儿童性教育,查看儿童性教育绘本数据死活找不到,没办法,就去当当网查询下数据,但是数据怎么弄下来呢,首先想到用Python,但是不会!!百 ...
- 【转】java爬虫,爬取当当网数据
背景:女票快毕业了(没错!我是有女票的!!!),写论文,主题是儿童性教育,查看儿童性教育绘本数据死活找不到,没办法,就去当当网查询下数据,但是数据怎么弄下来呢,首先想到用Python,但是不会!!百 ...
- 使用requests简单的页面爬取
首先安装requests库和准备User Agent 安装requests直接使用pip安装即可 pip install requests 准备User Agent,直接在百度搜索"UA查询 ...
- python爬虫项目-爬取雪球网金融数据(关注、持续更新)
(一)python金融数据爬虫项目 爬取目标:雪球网(起始url:https://xueqiu.com/hq#exchange=CN&firstName=1&secondName=1_ ...
- python网络爬虫《爬取get请求的页面数据》
一.urllib库 urllib是python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在python3中的为urllib.request和urllib. ...
随机推荐
- Android学习基础之onSaveInstanceState和onRestoreInstanceState触发的时机
先看Application Fundamentals上的一段话: Android calls onSaveInstanceState() before the activity becomes ...
- Java中的“&”和“&&”的区别
Java中的"&"和"&&"的区别 1."&"是位运算符,"&&"是逻辑 ...
- TypeError:_12.store.query is not a function
1.错误描述 TypeError:_12.store.query is not a function _SearchMixin.js(第62行 ...
- Linux显示2015年日历表
Linux显示2015年日历表 youhaidong@youhaidong-ThinkPad-Edge-E545:~$ cal 2015 2015 一月 二月 三月 日 一 二 三 四 五 六 日 一 ...
- HTML5图片居中的问题
刚开始接触html5,准备写一些网页,但是学习的过程中遇到了图片不能居中的问题,首先来看看,代码和执行效果: <!DOCTYPE html> <html> <head&g ...
- ontimer 与多线程
一般来说,在MFC中开启一个UI线程可以用以下代码: m_pCameraThread = AfxBeginThread(RUNTIME_CLASS(CCameraThread)); if (!m_pC ...
- 在ASP.NET 中检测手机浏览器(转)
引言 之前做的项目中需要在浏览器查看PDF文件.在电脑端没有问题,但是手机端网页打开失败. 后来使用了pdf.js,个人认为pdf.js的页面不够清爽,就希望网站能自动检测登录设备,电脑端保持原样,手 ...
- python根据索引删除内容并写入文本
在python中,有个好用的模块linecache,该模块允许从任何文件里得到任何的行,并且使用缓存进行优化,常见的情况是从单个文件读取多行.linecache.getline(filename,li ...
- .NET平台开源项目速览(21)Cron任务调度CronNET
如果用知乎,可以关注专栏:.NET开源项目和PowerBI社区 Quartznet大名鼎鼎应该很少有人不知道,相关的开源项目很多,不过那东东对新手来说,有点晦涩,加上哪个Cron表达式,可能一进去云里 ...
- 【BZOJ1499】瑰丽华尔兹(动态规划)
[BZOJ1499]瑰丽华尔兹(动态规划) 题面 BZOJ 题解 先写部分分 设\(f[t][i][j]\)表示当前在\(t\)时刻,位置在\(i,j\)时走的最多的步数 这样子每一步要么停要么走 时 ...