选择排序—堆排序(Heap Sort) 没看明白,不解释
堆排序是一种树形选择排序,是对直接选择排序的有效改进。
基本思想:
堆的定义如下:具有n个元素的序列(k1,k2,...,kn),当且仅当满足
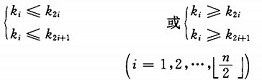
时称之为堆。由堆的定义可以看出,堆顶元素(即第一个元素)必为最小项(小顶堆)。
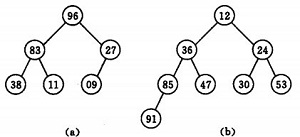
若以一维数组存储一个堆,则堆对应一棵完全二叉树,且所有非叶结点的值均不大于(或不小于)其子女的值,根结点(堆顶元素)的值是最小(或最大)的。如:
(a)大顶堆序列:(96, 83,27,38,11,09)
(b) 小顶堆序列:(12,36,24,85,47,30,53,91)
初始时把要排序的n个数的序列看作是一棵顺序存储的二叉树(一维数组存储二叉树),调整它们的存储序,使之成为一个堆,将堆顶元素输出,得到n 个元素中最小(或最大)的元素,这时堆的根节点的数最小(或者最大)。然后对前面(n-1)个元素重新调整使之成为堆,输出堆顶元素,得到n 个元素中次小(或次大)的元素。依此类推,直到只有两个节点的堆,并对它们作交换,最后得到有n个节点的有序序列。称这个过程为堆排序。
因此,实现堆排序需解决两个问题:
1. 如何将n 个待排序的数建成堆;
2. 输出堆顶元素后,怎样调整剩余n-1 个元素,使其成为一个新堆。
首先讨论第二个问题:输出堆顶元素后,对剩余n-1元素重新建成堆的调整过程。
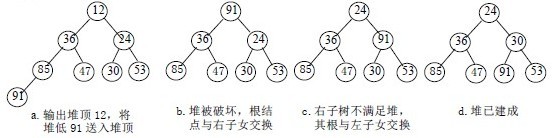
调整小顶堆的方法:
1)设有m 个元素的堆,输出堆顶元素后,剩下m-1 个元素。将堆底元素送入堆顶((最后一个元素与堆顶进行交换),堆被破坏,其原因仅是根结点不满足堆的性质。
2)将根结点与左、右子树中较小元素的进行交换。
3)若与左子树交换:如果左子树堆被破坏,即左子树的根结点不满足堆的性质,则重复方法 (2).
4)若与右子树交换,如果右子树堆被破坏,即右子树的根结点不满足堆的性质。则重复方法 (2).
5)继续对不满足堆性质的子树进行上述交换操作,直到叶子结点,堆被建成。
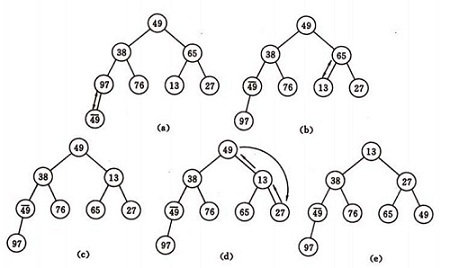
称这个自根结点到叶子结点的调整过程为筛选。如图:
再讨论对n 个元素初始建堆的过程。
建堆方法:对初始序列建堆的过程,就是一个反复进行筛选的过程。
1)n 个结点的完全二叉树,则最后一个结点是第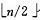 个结点的子树。
个结点的子树。
2)筛选从第个结点为根的子树开始,该子树成为堆。
3)之后向前依次对各结点为根的子树进行筛选,使之成为堆,直到根结点。
如图建堆初始过程:无序序列:(49,38,65,97,76,13,27,49)

算法的实现:
从算法描述来看,堆排序需要两个过程,一是建立堆,二是堆顶与堆的最后一个元素交换位置。所以堆排序有两个函数组成。一是建堆的渗透函数,二是反复调用渗透函数实现排序的函数。
void print(int a[], int n){
for(int j= 0; j<n; j++){
cout<<a[j] <<" ";
}
cout<<endl;
}
/**
* 已知H[s…m]除了H[s] 外均满足堆的定义
* 调整H[s],使其成为大顶堆.即将对第s个结点为根的子树筛选,
*
* @param H是待调整的堆数组
* @param s是待调整的数组元素的位置
* @param length是数组的长度
*
*/
void HeapAdjust(int H[],int s, int length)
{
int tmp = H[s];
int child = 2*s+1; //左孩子结点的位置。(i+1 为当前调整结点的右孩子结点的位置)
while (child < length) {
if(child+1 <length && H[child]<H[child+1]) { // 如果右孩子大于左孩子(找到比当前待调整结点大的孩子结点)
++child ;
}
if(H[s]<H[child]) { // 如果较大的子结点大于父结点
H[s] = H[child]; // 那么把较大的子结点往上移动,替换它的父结点
s = child; // 重新设置s ,即待调整的下一个结点的位置
child = 2*s+1;
} else { // 如果当前待调整结点大于它的左右孩子,则不需要调整,直接退出
break;
}
H[s] = tmp; // 当前待调整的结点放到比其大的孩子结点位置上
}
print(H,length);
}
/**
* 初始堆进行调整
* 将H[0..length-1]建成堆
* 调整完之后第一个元素是序列的最小的元素
*/
void BuildingHeap(int H[], int length)
{
//最后一个有孩子的节点的位置 i= (length -1) / 2
for (int i = (length -1) / 2 ; i >= 0; --i)
HeapAdjust(H,i,length);
}
/**
* 堆排序算法
*/
void HeapSort(int H[],int length)
{
//初始堆
BuildingHeap(H, length);
//从最后一个元素开始对序列进行调整
for (int i = length - 1; i > 0; --i)
{
//交换堆顶元素H[0]和堆中最后一个元素
int temp = H[i]; H[i] = H[0]; H[0] = temp;
//每次交换堆顶元素和堆中最后一个元素之后,都要对堆进行调整
HeapAdjust(H,0,i);
}
}
int main(){
int H[10] = {3,1,5,7,2,4,9,6,10,8};
cout<<"初始值:";
print(H,10);
HeapSort(H,10);
//selectSort(a, 8);
cout<<"结果:";
print(H,10);
}
分析:
设树深度为k,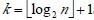 。从根到叶的筛选,元素比较次数至多2(k-1)次,交换记录至多k 次。所以,在建好堆后,排序过程中的筛选次数不超过下式:
。从根到叶的筛选,元素比较次数至多2(k-1)次,交换记录至多k 次。所以,在建好堆后,排序过程中的筛选次数不超过下式:
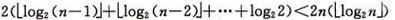
而建堆时的比较次数不超过4n 次,因此堆排序最坏情况下,时间复杂度也为:O(nlogn )。
选择排序—堆排序(Heap Sort) 没看明白,不解释的更多相关文章
- Python入门篇-数据结构堆排序Heap Sort
Python入门篇-数据结构堆排序Heap Sort 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.堆Heap 堆是一个完全二叉树 每个非叶子结点都要大于或者等于其左右孩子结点 ...
- 排序 选择排序&&堆排序
选择排序&&堆排序 1.选择排序: 介绍:选择排序(Selection sort)是一种简单直观的排序算法.它的工作原理如下.首先在未排序序列中找到最小(大)元素,存放到排序序列的起始 ...
- 数据结构 - 堆排序(heap sort) 具体解释 及 代码(C++)
堆排序(heap sort) 具体解释 及 代码(C++) 本文地址: http://blog.csdn.net/caroline_wendy 堆排序包括两个步骤: 第一步: 是建立大顶堆(从大到小排 ...
- 《算法4》2.1 - 选择排序算法(Selection Sort), Python实现
选择排序算法(Selection Sort)是排序算法的一种初级算法.虽然比较简单,但是基础,理解了有助于后面学习更高深算法,勿以勿小而不为. 排序算法的语言描述: 给定一组物体,根据他们的某种可量化 ...
- 直接选择排序&堆排序
1.什么是直接选择排序? 直接选择排序(Straight Select Sort)是一种简单的排序方法,它的基本思想是:通过n-i次关键字之间的比较,从n-i+1个记录中选出关键字最小的记录,并和第i ...
- 数据结构 - 树形选择排序 (tree selection sort) 具体解释 及 代码(C++)
树形选择排序 (tree selection sort) 具体解释 及 代码(C++) 本文地址: http://blog.csdn.net/caroline_wendy 算法逻辑: 依据节点的大小, ...
- 简单选择排序(Simple Selection Sort)
body, table{font-family: 微软雅黑; font-size: 13.5pt} table{border-collapse: collapse; border: solid gra ...
- 数据结构 - 只需选择排序(simple selection sort) 详细说明 和 代码(C++)
数据结构 - 只需选择排序(simple selection sort) 本文地址: http://blog.csdn.net/caroline_wendy/article/details/28601 ...
- js 实现排序算法 -- 选择排序(Selection Sort)
原文: 十大经典排序算法(动图演示) 选择排序(Selection Sort) 选择排序(Selection-sort)是一种简单直观的排序算法.它的工作原理:首先在未排序序列中找到最小(大)元素,存 ...
- 【排序基础】1、选择排序法 - Selection Sort
文章目录 选择排序法 - Selection Sort 为什么要学习O(n^2)的排序算法? 选择排序算法思想 操作:选择排序代码实现 选择排序法 - Selection Sort 简单记录-bobo ...
随机推荐
- linux dhcp 设置路由及主机名
自动获取ipDHCP方式获取ip:dhclient [网络接口]释放通过DHCP获取的ip地址:dhclient -r [网络接口]查看网络接口 ifconfig -a(列出所有接口含禁用的) eth ...
- Linux基础四
vim编辑器 vi编辑器的增强版,语法高亮等扩展功能 vim三种工作模式 a,i,o等键输出模式 命令模式,输入模式,末行模式 模式间的切换 a:当前行插入 i:当前行插入 o:全新一行插入 :键末 ...
- 网络基础tcp/ip协议三
数据链路层:(位于网络层与物理层之间) 数据链路层的功能: 数据链路的建立,维护. 帧包装,帧传输,帧同步. 帧的差错恢复. 流量的控制. 以太网:(工作在数据链路层) CSMA/CD(带冲突检测的载 ...
- Pokémon Go呼应设计:让全世界玩家疯狂沉迷
引言:什么样的呼应设计会让移动游戏玩家沉迷?那必须为玩家构建一个属于玩家本人或者被玩家认可的虚拟环境,或者说是被玩家认可的虚拟世界.在移动游戏时代,想要做到这一点并不容易.但Pokémon Go却做到 ...
- Java中的换行符
Java中的换行符 PrintWriter out = response.getWriter(); out.write("\r\n"); Java中的换行符"\r\n&q ...
- R语言自动化报告格式——knitr
R语言自动化报告格式--knitr 相关文献: R语言自动化报告格式--knitr 资讯 | R Notebooks 即将发布 ------------------------------------ ...
- Java中的List转换成JSON报错(三)
1.错误描述 Exception in thread "main" java.lang.NoClassDefFoundError: net/sf/ezmorph/Morpher a ...
- web开发性能优化---代码优化篇
1.合理使用缓存使用 提高性能最好最快的办法当然是通过缓存来改善,对于任何一个web开发者都应该善用缓存.Asp.net下的缓存机制十分强大,用好缓存机制可以让我们极大的改善web应用的性能. 1.页 ...
- Django学习-1-管理我的django程序
网页中文文档 http://python.usyiyi.cn/documents/django_182/topics/db/models.html Django性能测试工具 https://githu ...
- java并发:Synchronized 原理
1.同步代码块: 反编译结果: monitorenter : 每个对象有一个监视器锁(monitor).当monitor被占用时就会处于锁定状态,线程执行monitorenter指令时尝试获取moni ...