Gradient Descent
理自Andrew Ng的machine learning课程。
目录:
- 梯度下降算法
- 梯度下降算法的直观展示
- 线性回归中的梯度下降
前提:
线性回归模型 :$h(\theta_0,\theta_1)=\theta_0+\theta_1x$
损失函数:$J(\theta_0,\theta_1)=\frac{1}{2m} \sum_{i=1}^m (h_\theta(x^(i))-y^(i))^2$
1、梯度下降算法
目的:求解出模型的参数 / estimate the parameters in the hypothesis function
如下图所示,$\theta_0,\theta_1$代表模型的参数,$J(\theta_0,\theta_1)$代表模型的损失函数
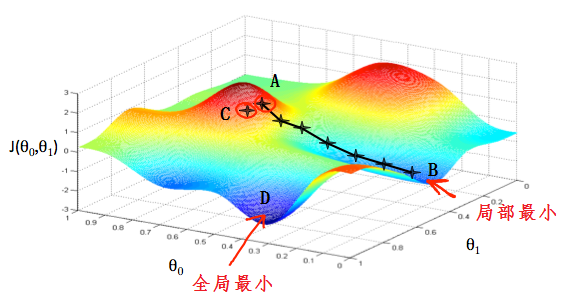
目的:从某一点出发,走到最低点。
怎么走:沿着所在点处最陡的方向下降。某一点山坡最陡的方向就是这一点的切线方向,也就是这一点的导数。每一步走多大取决于学习率$\alpha$。
在图中,每一个十字星之间的距离取决与$\alpha$的大小。小的$\alpha$会使两点之间的距离比较小,大的$\alpha$会产生大的步距。每一步走的方向取决于所在点的偏导。不同的起始点会有不同的终点,如上图从A出发最终到达B,而从C出发最终到达D。
梯度下降算法如下:
$\theta_j:=\theta_j-\alpha\frac{\partial}{\partial \theta_j}J(\theta_0,\theta_1)$ repeat util convergence
注意:$\theta_0,\theta_1$在每一步的迭代中都是同步更新的

2、梯度下降算法的直观展示
如下图:此图是一个损失函数的图像
当$\theta_1$在最小值点的右边时,图像的斜率(导数)是正的,学习率$\alpha$也是正的,根据梯度下降算法的公式,更新后的$\theta_1$是往左边方向走了,的确是朝着最小值点去了;
当$\theta_1$在最小值点的左边时,图像的斜率(导数)是负的,学习率$\alpha$是正的,根据梯度下降算法的公式,更新后的$\theta_1$是往右边方向走了,也是朝着最小值点去了;
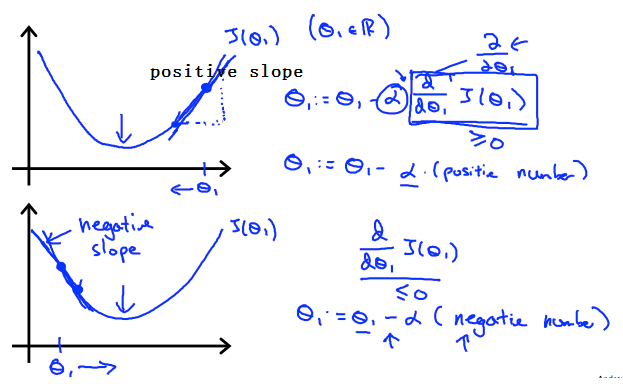
另外,我们需要调整$\alpha$使的算法可以在一定的时间内收敛。收敛失败或者收敛的非常慢,都说明使用的步长$\alpha$是错误的。

如果使用固定的$\alpha$,算法会收敛吗?
梯度下降算法隐含的一个信息就是,当点越来越接近最小值点的时候,梯度也会越来越小,到达最小值点时,梯度为0;
所以即使不去调整$\alpha$,走的步长也是会越来越短的,算法最终也还是会收敛的,所以没必要每次都调整$\alpha$的大小。

3、线性回归中的梯度下降算法
当把梯度下降算法具体的运用到线性回归上去的时候,算法就可以在偏导部分写的更加具体了:
repear until convergence {
$\qquad \theta_0:=\theta_0-\alpha \frac {1}{m} \sum_{i=1}^m (h_\theta(x_i)-y_i)$
$\qquad \theta_1:=\theta_1-\alpha \frac {1}{m} \sum_{i=1}^m ((h_\theta(x_i)-y_i)x_i)$
}
batch gradient descent
以上:在每一步更新参数时,让所有的训练样本都参与更新的做法,称为batch gradient descent;
注意到:虽然梯度下降算法可能会陷入局部最优的情况,但是在线性回归中不存在这种问题,线性回归只有一个全局最优,没有局部最优,算法最终一定可以找到全局最优点(假设$\alpha$不是特别大)。
线性回归中,J是一个凸二次函数,这样的函数是碗状的(bowl-shaped),没有局部最优,只有一个全局最优。
Gradient Descent的更多相关文章
- 梯度下降(Gradient Descent)小结
在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法.这里就对梯度下降法做一个完整的总结. 1. 梯度 在微 ...
- 机器学习基础——梯度下降法(Gradient Descent)
机器学习基础--梯度下降法(Gradient Descent) 看了coursea的机器学习课,知道了梯度下降法.一开始只是对其做了下简单的了解.随着内容的深入,发现梯度下降法在很多算法中都用的到,除 ...
- 线性回归、梯度下降(Linear Regression、Gradient Descent)
转载请注明出自BYRans博客:http://www.cnblogs.com/BYRans/ 实例 首先举个例子,假设我们有一个二手房交易记录的数据集,已知房屋面积.卧室数量和房屋的交易价格,如下表: ...
- Proximal Gradient Descent for L1 Regularization
[本文链接:http://www.cnblogs.com/breezedeus/p/3426757.html,转载请注明出处] 假设我们要求解以下的最小化问题: ...
- FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MINI-BATCH LEARNING. WHAT IS THE DIFFERENCE?
FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MIN ...
- Logistic Regression and Gradient Descent
Logistic Regression and Gradient Descent Logistic regression is an excellent tool to know for classi ...
- 机器学习笔记:Gradient Descent
机器学习笔记:Gradient Descent http://www.cnblogs.com/uchihaitachi/archive/2012/08/16/2642720.html
- (转) An overview of gradient descent optimization algorithms
An overview of gradient descent optimization algorithms Table of contents: Gradient descent variants ...
- (二)深入梯度下降(Gradient Descent)算法
一直以来都以为自己对一些算法已经理解了,直到最近才发现,梯度下降都理解的不好. 1 问题的引出 对于上篇中讲到的线性回归,先化一个为一个特征θ1,θ0为偏置项,最后列出的误差函数如下图所示: 手动求解 ...
- [Machine Learning] 梯度下降(BGD)、随机梯度下降(SGD)、Mini-batch Gradient Descent、带Mini-batch的SGD
一.回归函数及目标函数 以均方误差作为目标函数(损失函数),目的是使其值最小化,用于优化上式. 二.优化方式(Gradient Descent) 1.最速梯度下降法 也叫批量梯度下降法Batch Gr ...
随机推荐
- java日期转化
package com.kang.util; import java.text.ParseException; import java.text.SimpleDateFormat; import ja ...
- The required anti-forgery form field "__RequestVerificationToken" is not present.
@using (Html.BeginForm()) { @Html.AntiForgeryToken() }
- 网络基础Cisco路由交换四
NAT及静态转换 概述(NAT:网络地址转化) 作用: 通过将内部网络的私有ip地址翻译成全球唯一的公网ip地址, 使内部网络可以连接到互联网等外部网络上. NATA的特性 优点: 节省公有合法ip地 ...
- Kettle参数化配置
Kettle参数化配置 在做系统化的Kettle实现方案,我们基本要定义一些不变的参数,在整个生命周期中使用,或者设置一些特定的参数,在一些特定的JOB中使用.参数化配置有利用我们Kettle实现规范 ...
- php session函数
session_start() 开启session 使用session前需要使用该函数 session_id() 获取当前回话的sessionid session_save_path($path) 如 ...
- Java类型转化报错
Java类型转化报错 报错如下: java.lang.ClassCastException:java.util.HashMap cannot be cast to java.util.List.
- 运行项目Tomcat报错
1.具体报错如下: Server Tomcat v7.0 Server at localhost was unable to start within 45 seconds. If the serve ...
- Java之split方法
Java之split方法 1.间隔号"." (1)str.split(".") String str = "10.156.35.87"; S ...
- hi3531 SDK 编译 kernel, 修改 参数
开发环境用户指南上这么写的 3.1 内核源代码 成功安装Hi3531 SDK后,内核源代码已存放于SDK目录下的osdrv/目录中,用户可 直接进入目录进行相关操作. 3.2 配置内核 如果对内核和H ...
- VxWorks操作系统shell命令与调试方法总结
VxWorks下的调试手段 主要介绍在Tornado集成开发环境下的调试方法,和利用支撑定位问题的步骤.思路. 1 Tornado的调试工具 嵌入式实时操作系统VxWorks和集成开发 ...