6月21日 Django ORM那些相关操作(表关联、聚合查询和分组查询)
一、ForeignKey操作
正向查找
对象查找(跨表)
语法:
对象.关联字段.字段
示例:
book_obj = models.Book.objects.first() # 第一本书对象
print(book_obj.publisher) # 得到这本书关联的出版社对象
print(book_obj.publisher.name) # 得到出版社对象的名称
字段查找(跨表)
语法:
关联字段__字段
示例:
print(models.Book.objects.values_list("publisher__name"))
反向操作
对象查找
语法:
obj.表名_set
示例:
publisher_obj = models.Publisher.objects.first() # 找到第一个出版社对象
books = publisher_obj.book_set.all() # 找到第一个出版社出版的所有书
titles = books.values_list("title") # 找到第一个出版社出版的所有书的书名
字段查找
语法:
表名__字段
示例:
titles = models.Publisher.objects.values_list("book__title")
related_name:反向操作时,使用的字段名,用于代替原反向查询时的'表名_set'。
related_query_name:反向查询操作时,使用的连接前缀,用于替换表名。
使用:
class Classes(models.Model):
name = models.CharField(max_length=32) class Student(models.Model):
name = models.CharField(max_length=32)
theclass = models.ForeignKey(to="Classes",related_name="students",related_query_name="query_students")
当我们要查询某个班级关联的所有学生(反向查询)时,我们会这么写:
models.Classes.objects.first().students.all()
当我们要查询id为1的学生的所在班级(反向查询)时,我们会这么写:
models.Classes.objects.filter(query_students__id=1).value('name')
二、ManyToManyField
class RelatedManager
"关联管理器"是在一对多或者多对多的关联上下文中使用的管理器。
它存在于下面两种情况:
- 外键关系的反向查询
- 多对多关联关系
简单来说就是当 点后面的对象 可能存在多个的时候就可以使用以下的方法。
方法
create()
创建一个新的对象,保存对象,并将它添加到关联对象集之中,返回新创建的对象。
>>> import datetime
>>> models.Author.objects.first().book_set.create(title="番茄物语", publish_date=datetime.date.today())
add()
把指定的model对象添加到关联对象集中。
添加对象
>>> author_objs = models.Author.objects.filter(id__lt=3)
>>> models.Book.objects.first().authors.add(*author_objs)
添加id
>>> models.Book.objects.first().authors.add(*[1, 2])
set()
更新model对象的关联对象。
>>> book_obj = models.Book.objects.first()
>>> book_obj.authors.set([2, 3])
remove()
从关联对象集中移除执行的model对象
>>> book_obj = models.Book.objects.first()
>>> book_obj.authors.remove(3)
clear()
从关联对象集中移除一切对象。
>>> book_obj = models.Book.objects.first()
>>> book_obj.authors.clear()
注意:
对于ForeignKey对象,clear()和remove()方法仅在null=True时存在。
举个例子:
ForeignKey字段没设置null=True时,
class Book(models.Model):
title = models.CharField(max_length=32)
publisher = models.ForeignKey(to=Publisher)
没有clear()和remove()方法:
>>> models.Publisher.objects.first().book_set.clear()
Traceback (most recent call last):
File "<input>", line 1, in <module>
AttributeError: 'RelatedManager' object has no attribute 'clear'
当ForeignKey字段设置null=True时,
class Book(models.Model):
name = models.CharField(max_length=32)
publisher = models.ForeignKey(to=Class, null=True)
此时就有clear()和remove()方法:
>>> models.Publisher.objects.first().book_set.clear()
注意:
- 对于所有类型的关联字段,add()、create()、remove()和clear(),set()都会马上更新数据库。换句话说,在关联的任何一端,都不需要再调用save()方法。
如果我们写的多对多关系是直接创建第三张表,没有使用ManyToManyField的话,除了查询其他方法是没有的,是通过操作第三张表进行处理的。
first_book = models.Book.objects.first()
# 找到第一本书
# 查询
# ret = models.Book.objects.first().author2book_set.all().values("author__name")
# print(ret)
ret = models.Book.objects.filter(id=1).values("author2book__author__name")
print(ret)
# first_book.author.set()
models.Author2Book.objects.create(book=first_book, author_id=1)
# 清空
models.Author2Book.objects.filter(book=first_book).delete()
三、聚合查询和分组查询
聚合
aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。
键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。
用到的内置函数:
from django.db.models import Avg, Sum, Max, Min, Count
示例:
>>> from django.db.models import Avg, Sum, Max, Min, Count
>>> models.Book.objects.all().aggregate(Avg("price"))
{'price__avg': 13.233333}
如果你想要为聚合值指定一个名称,可以向聚合子句提供它。
>>> models.Book.objects.aggregate(average_price=Avg('price'))
{'average_price': 13.233333}
如果你希望生成不止一个聚合,你可以向aggregate()子句中添加另一个参数。所以,如果你也想知道所有图书价格的最大值和最小值,可以这样查询:
>>> models.Book.objects.all().aggregate(Avg("price"), Max("price"), Min("price"))
{'price__avg': 13.233333, 'price__max': Decimal('19.90'), 'price__min': Decimal('9.90')}
分组
annotate()方法 返回的是QuerySet对象
annotate 按照调用该方法之前表或属性作为分组依据
我们在这里先复习一下SQL语句的分组。
假设现在有一张公司职员表:

我们使用原生SQL语句,按照部分分组求平均工资:
select dept,AVG(salary) from employee group by dept;
ORM查询:
from django.db.models import Avg
Employee.objects.values("dept").annotate(avg=Avg("salary").values(dept, "avg")
此处annotate是按照dept分组
连表查询的分组:

SQL查询:
select dept.name,AVG(salary) from employee inner join dept on (employee.dept_id=dept.id) group by dept_id;
ORM查询:
from django.db.models import Avg
models.Dept.objects.annotate(avg=Avg("employee__salary")).values("name", "avg")
此处是按照dept表的主键作为分组条件
annotate()函数和aggregate()的区别:
他们的 关系是都能执行 sum max min 这些的聚合语句 ;
区别是: annotate()函数,输出的结果仍然是一个QuerySet对象,能够调用filter()、order_by()甚至annotate()
aggregate() 输出的是一个字典,不能再对其结果进行下一步操作了
详情如下:

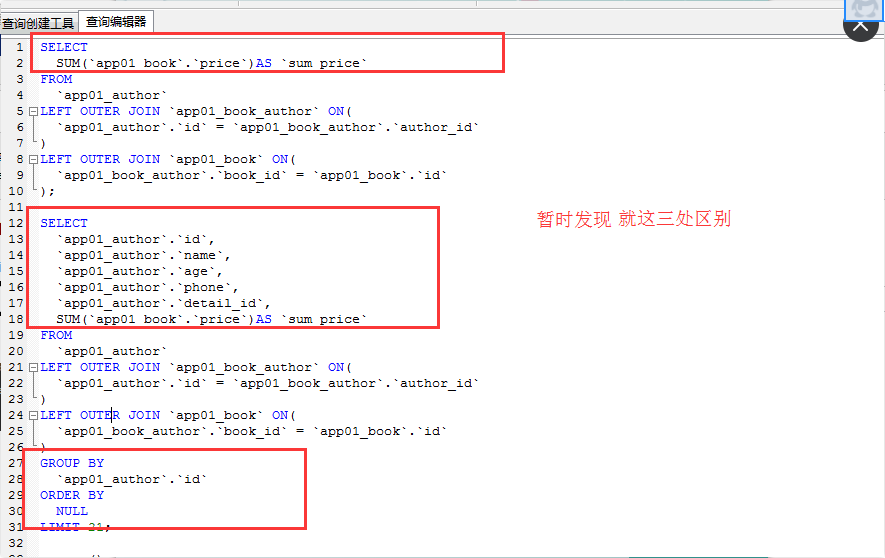
更多示例:
示例1:统计每一本书的作者个数
>>> book_list = models.Book.objects.all().annotate(author_num=Count("author"))
>>> for obj in book_list:
... print(obj.author_num)
...
2
1
1
示例2:统计出每个出版社买的最便宜的书的价格
>>> publisher_list = models.Publisher.objects.annotate(min_price=Min("book__price"))
>>> for obj in publisher_list:
... print(obj.min_price)
...
9.90
19.90
方法二:
>>> models.Book.objects.values("publisher__name").annotate(min_price=Min("price"))
<QuerySet [{'publisher__name': '沙河出版社', 'min_price': Decimal('9.90')}, {'publisher__name': '人民出版社', 'min_price': Decimal('19.90')}]>
示例3:统计不止一个作者的图书
>>> models.Book.objects.annotate(author_num=Count("author")).filter(author_num__gt=1)
<QuerySet [<Book: 番茄物语>]>
示例4:根据一本图书作者数量的多少对查询集 QuerySet进行排序
>>> models.Book.objects.annotate(author_num=Count("author")).order_by("author_num")
<QuerySet [<Book: 香蕉物语>, <Book: 橘子物语>, <Book: 番茄物语>]>
示例5:查询各个作者出的书的总价格
>>> models.Author.objects.annotate(sum_price=Sum("book__price")).values("name", "sum_price")
<QuerySet [{'name': '小精灵', 'sum_price': Decimal('9.90')}, {'name': '小仙女', 'sum_price': Decimal('29.80')}, {'name': '小魔女', 'sum_price': Decimal('9.90')}]>
sql练习:
from django.db import models # Create your models here. # 书
class Book(models.Model):
title = models.CharField(max_length=32)
publish_date = models.DateField(auto_now_add=True)
price = models.DecimalField(max_digits=5, decimal_places=2)
memo = models.TextField(null=True)
# 创建外键,关联publish
publisher = models.ForeignKey(to="Publisher")
# 创建多对多关联author
author = models.ManyToManyField(to="Author",related_name='books',related_query_name='book123') def __str__(self):
return self.title # 出版社
class Publisher(models.Model):
name = models.CharField(max_length=32)
city = models.CharField(max_length=32) def __str__(self):
return self.name # 作者
class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
phone = models.CharField(max_length=11)
detail = models.OneToOneField(to="AuthorDetail") def __str__(self):
return self.name # 作者详情
class AuthorDetail(models.Model):
addr = models.CharField(max_length=64)
email = models.EmailField()
图书models建表
import os if __name__ == '__main__':
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "days68_dj.settings")
import django django.setup() from app01 import models # 查找所有书名里包含番茄的书
books = models.Book.objects.filter(title__contains='番茄') # 查找出版日期是2017年的书
books = models.Book.objects.filter(publish_date__year='2017') # 查找出版日期是2017年的书名
books = models.Book.objects.filter(publish_date__year='2017').values('title') # 查找价格大于10元的书
books = models.Book.objects.filter(price__gt=10) # 查找价格大于10元的书名和价格
books = models.Book.objects.filter(price__gt=10).values('title', 'price') # 查找memo字段是空的书
books = models.Book.objects.filter(memo__isnull=True) # 查找在北京的出版社
books = models.Publisher.objects.filter(city='北京') # 查找名字以沙河开头的出版社
books = models.Publisher.objects.filter(name__startswith='沙河') # 查找作者名字里面带“小”字的作者
books = models.Author.objects.filter(name__contains='小') # 查找年龄大于30岁的作者
books = models.Author.objects.filter(age__gt=30) # 查找手机号是155开头的作者
books = models.Author.objects.filter(phone__startswith='155') # 查找手机号是155开头的作者的姓名和年龄
books = models.Author.objects.filter(phone__startswith='155').values('name', 'age') # 查找书名是“番茄物语”的书的出版社
books = models.Book.objects.get(title='番茄物语').publisher # 查找书名是“番茄物语”的书的出版社所在的城市
# books = models.Book.objects.get(title='番茄物语').publisher.city
books = models.Book.objects.filter(title='番茄物语').values('publisher__city') # 查找书名是“番茄物语”的书的出版社的名称
# books = models.Book.objects.get(title='番茄物语').publisher.name
books = models.Book.objects.filter(title='番茄物语').values('publisher__name') # 查找书名是“番茄物语”的书的所有作者
# books = models.Book.objects.get(title='番茄物语').author.all()
books = models.Book.objects.filter(title='番茄物语').values('author__name') # 查找书名是“番茄物语”的书的作者的年龄
books = models.Book.objects.filter(title='番茄物语').values('author__age') # 查找书名是“番茄物语”的书的作者的手机号码
books = models.Book.objects.filter(title='番茄物语').values('author__phone') # 查找书名是“番茄物语”的书的作者的地址
books = models.Book.objects.filter(title='番茄物语').values('author__detail__addr') # 查找书名是“番茄物语”的书的作者的邮箱
books = models.Book.objects.filter(title='番茄物语').values('author__detail__email') books = models.Author.objects.get(id=1).books.all()
books = models.Author.objects.filter(id=1).values('book123__title') print(books)
普通查询sql练习
from django.db import models # Create your models here. class Dept(models.Model):
name = models.CharField(max_length=32) class Employee(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
salary = models.IntegerField()
province = models.CharField(max_length=64)
dept = models.ForeignKey(to=Dept) # def db_table(self):
# return 'employee'
员工models建表
import os if __name__ == '__main__':
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "days68_dj.settings")
import django django.setup() from app02 import models from django.db.models import Avg #我们使用原生SQL语句,按照部分分组求平均工资:
# SELECT d.name,avg(salary) as avg FROM app02_employee e JOIN app02_dept d ON e.dept_id = d.id GROUP BY dept_id
#ORM查询:
res = models.Dept.objects.annotate(avg=Avg('employee__salary')).values('name', 'avg') # res = models.Employee.objects.annotate(avg=Avg('salary')).values('avg') print(res)
按照部分分组求平均工资
from django.db.models import Avg, Sum, Max, Min, Count
#统计每一本书的作者个数
res = models.Book.objects.annotate(count_author=Count('author__id')).values('title', 'count_author')
#统计出每个出版社买的最便宜的书的价格
res = models.Publisher.objects.annotate(min_price=Min('book__price')).values('name', 'book__title', 'min_price')
#统计不止一个作者的图书
res= models.Book.objects.annotate(author_num=Count('author__id')).filter(author_num__gt=1).values('title','author_num')
#根据一本图书作者数量的多少对查询集 QuerySet进行排序
res=models.Book.objects.annotate(author_num=Count('author__id')).values('title','author_num').order_by('-author_num')
#查询各个作者出的书的总价格
res=models.Author.objects.annotate(sum_price=Sum('book123__price')).values('name','sum_price')
分组练习
6月21日 Django ORM那些相关操作(表关联、聚合查询和分组查询)的更多相关文章
- Django ORM那些相关操作zi
Django ORM那些相关操作 一般操作 看专业的官网文档,做专业的程序员! 必知必会13条 <1> all(): 查询所有结果 <2> filter(**kwargs) ...
- Django ORM 那些相关操作
Django ORM 那些相关操作 一般操作 必知必会13条 <> all(): #查询所有的结果 <> filter(**kwargs) # 它包含了与所给筛选条件相匹配的对 ...
- Django ORM那些相关操作
一般操作 https://docs.djangoproject.com/en/1.11/ref/models/querysets/ 官网文档 常用的操作 <1> all() ...
- 6月20日 Django中ORM介绍和字段、字段参数、相关操作
一.Django中ORM介绍和字段及字段参数 二.Django ORM 常用字段和参数 三.Django ORM执行原生SQL.在Python脚本中调用Django环境.Django终端打印SQL语句 ...
- Django的ORM那些相关操作
一般操作 看专业的官网文档,做专业的程序员! 必知必会13条 <> all(): 查询所有结果 <> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 & ...
- Django之ORM那些相关操作
一般操作 看专业的官网文档,做专业的程序员! 必知必会13条 <1> all(): 查询所有结果 <2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 ...
- 长沙4月21日开发者大会暨.NET社区成立大会活动纪实
活动总结 2019年4月21日是一个斜风细雨.微风和煦的美好日子,由长沙.NET技术社区.腾讯云云加社区.微软Azure云技术社区.中国.NET技术社区.长沙柳枝行动.长沙互联网活动基地(唐胡子俱乐部 ...
- 关于2013年1月21日的DNS故障分析文章
首页 资讯 小组 资源 注册 登录 首页 最新文章 业界 开发 IT技术 设计 创业 IT职场 访谈 在国外 经典回顾 更多 > - 导航条 - 首页 最新文章 业界 - Googl ...
- 本周MySQL官方verified/open的bug列表(11月15日至11月21日)
本周MySQL verified的bug列表(11月15日至11月21日) 1. Bug #70923 Replication failure on multi-statement INSERT ...
随机推荐
- rabbitmq集群实现
官方文档 一.环境准备 1.1 IP地址规划 1.2 配置主机域名解析 ##每个节点修改主机名 # hostnamectl set-hostname mq1.example.local # hostn ...
- python篇第5天【变量】
第4天加班 多个变量赋值 Python允许你同时为多个变量赋值.例如: a = b = c = 1 以上实例,创建一个整型对象,值为1,三个变量被分配到相同的内存空间上. 您也可以为多个对象指定多个变 ...
- python篇第3天【编码规范】
第二天加班去了! 语法约定: 多行语句 Python语句中一般以新行作为为语句的结束符. 但是我们可以使用斜杠( \)将一行的语句分为多行显示,如下所示: total = item_one + \ i ...
- Solution -「CF 1023F」Mobile Phone Network
\(\mathcal{Description}\) Link. 有一个 \(n\) 个结点的图,并给定 \(m_1\) 条无向带权黑边,\(m_2\) 条无向无权白边.你需要为每条白边指定边权 ...
- Solution -「LOJ #6485」 LJJ 学二项式定理
\(\mathcal{Description}\) Link. 给定 \(n,s,a_0,a_1,a_2,a_3\),求: \[\sum_{i=0}^n\binom{n}is^ia_{i\bm ...
- [题解]第十一届北航程序设计竞赛预赛——I.神奇宝贝大师
题目描述 一张n*m的地图,每个格子里面有一定数量的神奇宝贝,求一个最优位置,使得所有神奇宝贝到该位置的曼哈顿距离最小. 一共有T组数据,每组数据包含两行,第一行是n和m(1<=n,m<= ...
- React 函数组件中对window添加事件监听resize导致回调不能获得Hooks最新状态的问题解决思路
React 函数组件中对window添加事件监听resize导致回调不能获得Hooks最新状态的问题解决思路 这几天在忙着把自己做的项目中的类组件转化为功能相同的函数组件,首先先贴一份该组件类组件的关 ...
- 60天shell脚本计划-4/12-渐入佳境
--作者:飞翔的小胖猪 --创建时间:2021年2月11日 --修改时间:2021年2月15日 说明 每日上传更新一个shell脚本,周期为60天.如有需求的读者可根据自己实际情况选用合适的脚本,也可 ...
- kafka 事务代码实现(生产者到server端的事务)
kafka的事务指的是2个点 ① 生产者到kafka服务端的事务保障 ②消费者从kafka拉取数据的事务 kafka提供的事务机制是 第①点, 对于第②点来说 只能自己在消费端实现幂等性. ...
- Qt:QVariant
0.说明 QVariant可以表现出Qt数据类型中最普遍的行为. 一个QVariant对象中一次只保留一个type()的单个值(有的type()可以是多值的,例如StringList),可以用conv ...