透过Redis源码探究Hash表的实现
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com/archives/667
本文使用的Redis 5.0源码
概述
我们在学习 Redis 的 Hash 表的时候难免脑子里会想起其他 Hash 表的实现,然后进行一番对比。通常我们如果要设计一个 Hash 表,那么我们需要考虑这几个问题:
- 有没有并发操作;
- Hash冲突如何解决;
- 以什么样的方式扩容。
对 Redis 来说,首先它是单线程的工作模式,所以不需要考虑并发问题,这题 pass。
对于 Hash 冲突的解决,通常来说有,开放寻址法、再哈希法、拉链法等。但是大多数的编程语言都用拉链法实现哈希表,它的实现复杂度也不高,并且平均查找的长度也比较短,各个用于存储节点的内存都是动态申请的,可以节省比较多的存储空间。
所以对于 Redis 来说也是使用了拉链法来解决 hash 冲突,如下所示,通过链表的方式把一个个节点串起来:
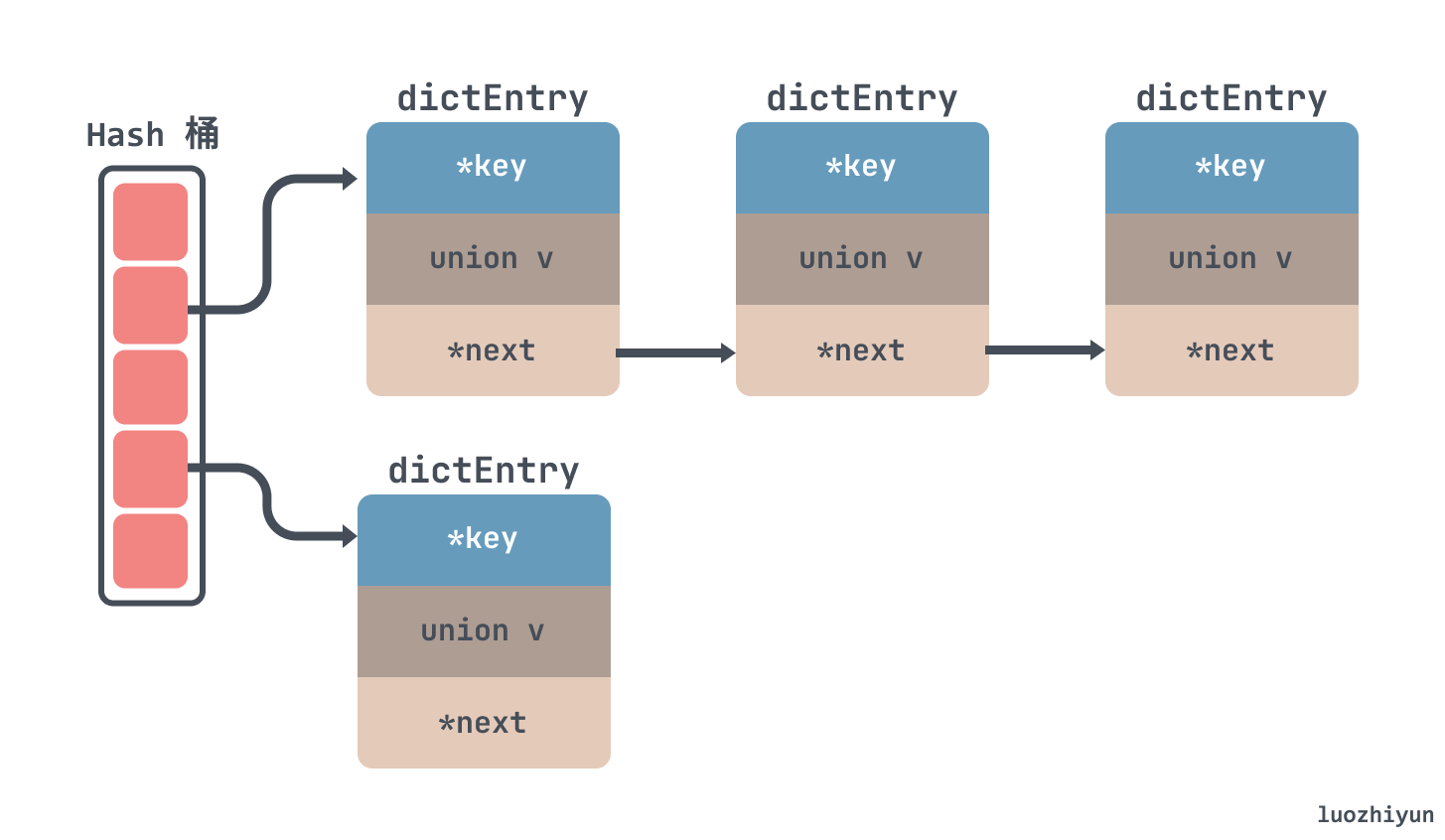
至于为什么没有向 JDK 的 HashMap 一样红黑树来解决冲突,我觉得其实有两方面,一方面是链表转红黑数其实也是需要时间成本的,会影响链表的操作效率;另一方面就是红黑树其实在节点比较少的情况下效率是不如链表的。
再来看看扩容,对于扩容来说,一般要新起一块内存,然后将旧数据迁移到新的内存块中,这个过程中因为是单线程,所以在扩容的时候,不能阻塞主线程很长时间,在 Redis 中采用的是渐进式 rehash + 定时 rehash 。
渐进式 rehash 会在执行增删查改前,先判断当前字典是否在执行rehash。如果是,则rehash一个节点。这其实是一种分治的思想,通过通过把大任务划分成一个个小任务,每个小任务只执行一小部分数据,最终完成整个大任务。
定时 rehash 如果 dict 一直没有操作,无法渐进式迁移数据,那主线程会默认每间隔 100ms 执行一次迁移操作。这里一次会以 100 个桶为基本单位迁移数据,并限制如果一次操作耗时超时 1ms 就结束本次任务,待下次再次触发迁移
Redis 在结构体中设置两个表 ht[0] 和 ht[1],如果当前 ht[0]的容量是 0 ,那么第一次会直接给4个容量;如果不是 0 ,那么容量会直接翻倍,然后将新内存放入到ht[1]中返回,并设置标记0表示在扩容中。
迁移 hash 桶的操作会在增删改查哈希表时每次迁移 1 个哈希桶从ht[0] 迁移到ht[1],在迁移拷贝完所有桶之后会将ht[0] 空间释放,然后将ht[1]赋值给ht[0] ,并把ht[1]大小重置为0 ,并将表示设置标记1表示 rehash 结束了。
对于查找来说,在 rehash 的过程中,因为没有并发问题,所以查找 dict 也会依次先查找 ht[0] 然后再查找 ht[1]
设计与实现
Redis 的 hash 实现主要在 dict.h 和 dict.c 这两个文件中。
hash 表的数据结构大致如下所示,我就不贴出结构体的代码了,字段都标注在图上了:
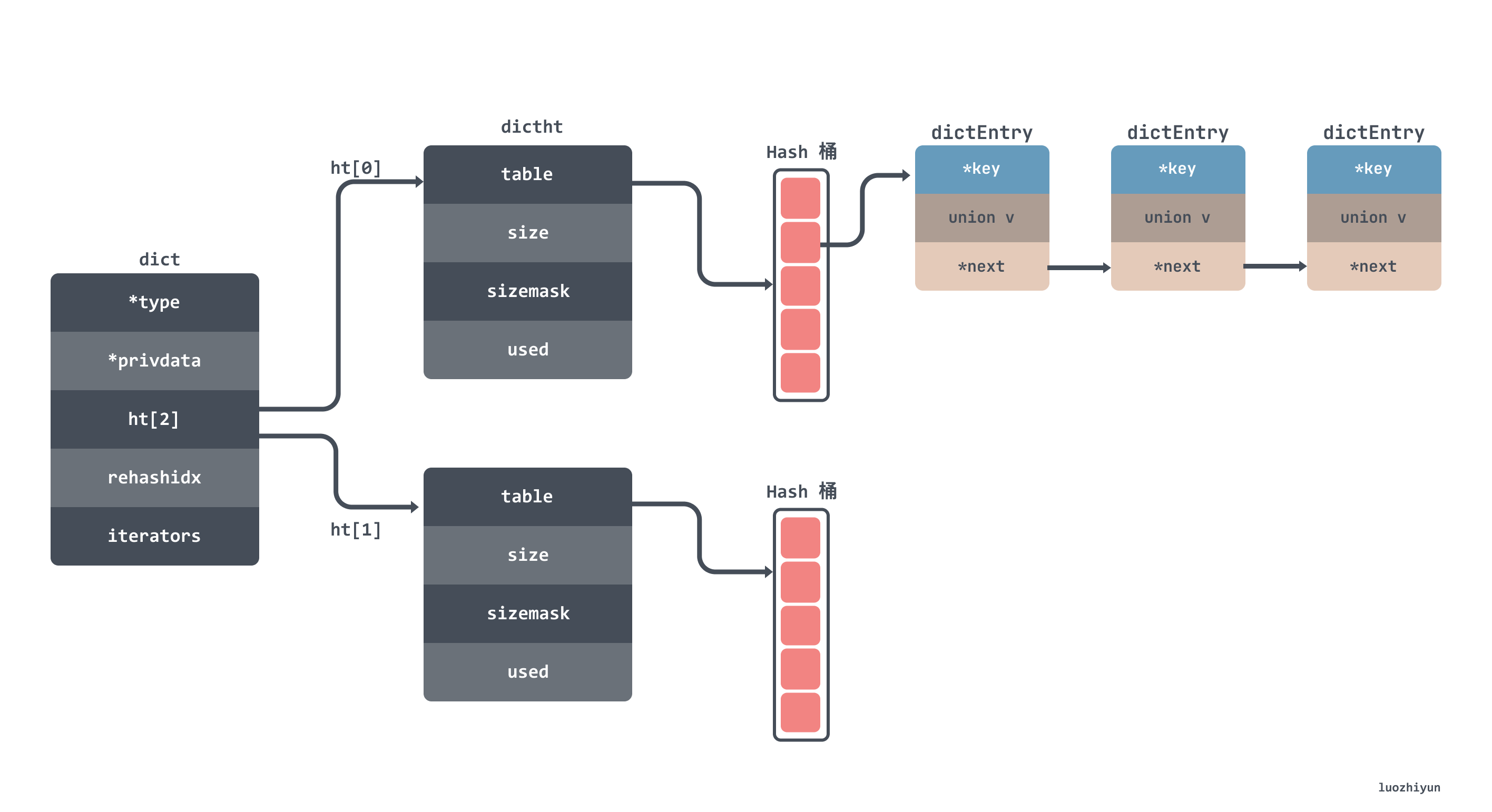
从上面的图上也可以看到 hash 表中有一个空间为2的 dictht 数组,这个数组就是用来做 rehash 时交替保存数据用的,其中 dict 里面的 rehashidx 用来表示是否在进行 rehash 。
何时触发扩缩容?
很多 hash 表都只有扩容,但是 dict 在 Redis 中是既有扩容,也有缩容。
扩容
扩容其实就是一般是在 add 元素的时候校验一下是否达到某个阈值,然后决定要不要进行扩容。所以经过搜索可以看到添加元素会调用 dictAddRaw 这个函数,我们通过函数的注释也可以知道它是 add 或查找的底层的函数。
Low level add or find:
This function adds the entry but instead of setting a value returns the dictEntry structure to the user, that will make sure to fill the value field as he wishes.
dicAddRaw 函数会调用到 _dictKeyIndex 函数,这个函数会调用 _dictExpandIfNeeded 判断是否需要扩容。
┌─────────────┐ ┌─────────┐ ┌─────────────┐ ┌─────────────────────┐
│ add or find ├────►│dicAddRaw├─────►│_dictKeyIndex├─────►│ _dictExpandIfNeeded │
└─────────────┘ └─────────┘ └─────────────┘ └─────────────────────┘
_dictExpandIfNeeded 函数判断了大致有三种情况会进行扩容:
- 如果 hash 表的size为0,那么创建一个容量为4的hash表;
- 服务器目前没有在执行 rdb 或者 aof 操作, 并且哈希表的负载因子大于等于
1; - 服务器目前正在执行 rdb 或者 aof 操作, 并且哈希表的负载因子大于等于
5;
其中哈希表的负载因子可以通过公式:
// load ratio = the number of elements / the buckets
load_ratio = ht[0].used / ht[0].size
比如说, 对于一个大小为 4 , 包含 4 个键值对的哈希表来说, 这个哈希表的负载因子为:
load_ratio = 4 / 4 = 1
又比如说, 对于一个大小为 512 , 包含 256 个键值对的哈希表来说, 这个哈希表的负载因子为:
load_ratio = 256 / 512 = 0.5
为什么要根据 rdb 或者 aof 操作联合负载因子来判断是否应该扩容呢?其实源码的注释中也有提到:
as we use copy-on-write and don't want to move too much memory around when there is a child performing saving operations.
也就是说在 copy-on-write 时提高执行扩展操作所需的负载因子, 可以尽可能地避免在子进程存在期间进行哈希表扩展操作, 这可以避免不必要的内存写入操作, 最大限度地节约内存,提高子进程的操作的性能。
逻辑我们说完了, 下面我们看看源码:
static int _dictExpandIfNeeded(dict *d)
{
// 正在扩容中
if (dictIsRehashing(d)) return DICT_OK;
// 如果 hash 表的size为0,那么创建一个容量为4的hash表
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
// hash表中元素的个数已经大于hash表桶的数量
if (d->ht[0].used >= d->ht[0].size &&
//dict_can_resize 表示是否可以扩容
(dict_can_resize ||
// hash表中元素的个数已经除以hash表桶的数量是否大于5
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2); // 容量扩大两倍
}
return DICT_OK;
}
通过上面的源码我们可以知道,如果当前表的已用空间大小为 size,那么就将表扩容到 size*2 的大小。新的 dict hash 表是通过 dictExpand 来进行创建的。
int dictExpand(dict *d, unsigned long size)
{
//正在扩容,直接返回
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
dictht n;
// _dictNextPower会返回 size 最接近的2的指数值
// 也就是size是10,那么返回 16,size是20,那么返回32
unsigned long realsize = _dictNextPower(size);
// 校验扩容之后的值是否和当前一样
if (realsize == d->ht[0].size) return DICT_ERR;
// 初始化 dictht 成员变量
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*)); // 申请空间是 size * Entry的大小
n.used = 0;
//校验hash 表是否初始化过,没有初始化不应该进行rehash
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
//将新的hash表赋值给 ht[1]
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
这一段代码还是比较清晰的,可以跟着上面的注释稍微看一下就好了。
缩容
讲完了扩容,那么来看一下缩容。熟悉 Redis 的同学都知道,在 Redis 里面对于清理过期数据一个是惰性删除,另一个是定期删除,缩容其实也是在定期删除里面做的。
Redis 的定时器会每100ms调用一次 databasesCron 函数,它会调用到 dictResize 函数进行缩容:
┌─────────────┐ ┌──────────────────┐ ┌──────────┐ ┌──────────┐
│databasesCron├──►│tryResizeHashTable├──►│dictResize├──►│dictExpand│
└─────────────┘ └──────────────────┘ └──────────┘ └──────────┘
同样的 dictResize 函数中也会判断一下是否正在执行 rehash 以及校验 dict_can_resize 是否在进行 copy on write操作。然后将 hash 表的 bucket 大小缩小为和被键值对同样大小:
int dictResize(dict *d)
{
int minimal;
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;
minimal = d->ht[0].used; // 将bucket 缩小为和被键值对同样大小
if (minimal < DICT_HT_INITIAL_SIZE)
minimal = DICT_HT_INITIAL_SIZE;
return dictExpand(d, minimal);
}
最后同样调用 dictExpand 创建新的空间赋值给 ht[1]。
数据迁移如何进行?
上面我们也提到了,无论是扩容还是缩容,创建的新的空间都会赋值给 ht[1] 以便进行数据迁移。然后在两个地方分别执行数据迁移,一个是增删改查哈希表时触发,另一个是定时触发
增删改查哈希表时触发
增删改查操作的时候都会检查 rehashidx 参数,校验是否正在迁移,如果正在迁移那么会调用 _dictRehashStep 函数,然后会调用到 dictRehash 函数。
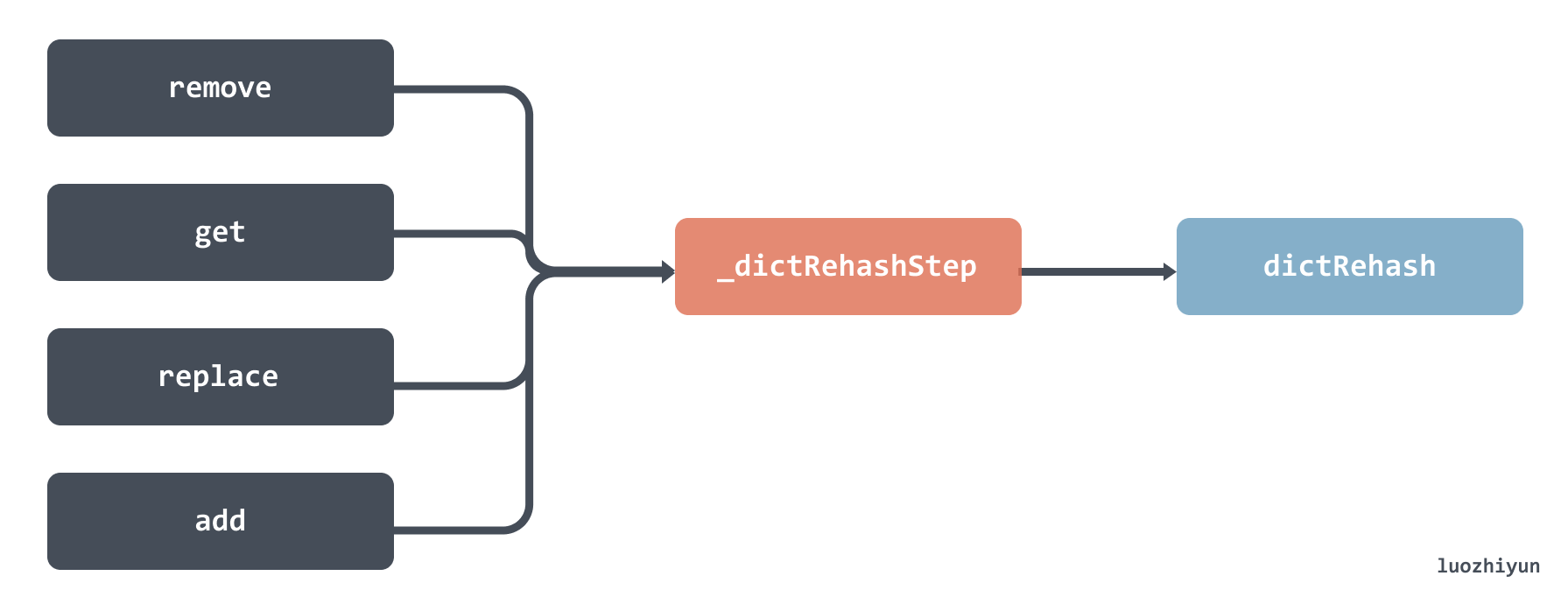
但是需要注意的是,这里调用 dictRehash 函数传入的大小是 1 ,也就意味着每次只迁移 1 个 bucket。下面我们来看看 dictRehash 函数,这是整个迁移过程中最重要的函数。这个函数主要做了以下几件事:
- 校验当前迁移的bucket数量是否已达上线,并且ht[0]是否还有元素;
- 判断当前的迁移的bucket槽位是否为空,最大访问的空槽数量不能超过 n*10,n是本次迁移bucket数量;
- 获取到非空槽位里面 entry 链表进行循环迁移;
- 首先获取ht[1]新槽位的index;
- 一个个节点放置到新bucket的头部;
- 直到全部迁移完毕;
- 迁移完了将旧的hash表ht[0]对应的bucket置空;
- 检查如果已经rehash完了,那么需要free掉内存占用,并将ht[1]赋值给ht[0];
感兴趣的可以看看下面源码,已标注好注释:
int dictRehash(dict *d, int n) {
// 最大的空bucket访问次数
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
// 校验当前迁移的bucket数量是否已达上线,并且ht[0]是否还有元素;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
assert(d->ht[0].size > (unsigned long)d->rehashidx);
// 判断当前的迁移的bucket槽位是否为空
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
// 获取到槽位里面 entry 链表
de = d->ht[0].table[d->rehashidx];
// 从老的bucket迁移数据到新的bucket中
while(de) {
uint64_t h;
nextde = de->next;
// hash之后获取新hash表的bucket槽位
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
// 一个个节点放置到新bucket的头部
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
// 迁移完了将旧的hash表对应的bucket置空
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
// 如果已经rehash完了,那么需要free掉内存占用,并将ht[1]赋值给ht[0]
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;// 返回0表示迁移已完成
}
return 1; // 返回1表示迁移未完成
}
定时触发
定时触发是由 databasesCron 函数进行定时触发,这个函数会每100ms 运行一次,最终会通过 dictRehashMilliseconds 函数调用到我们上面提到的 dictRehash 函数。
┌─────────────┐ ┌───────────────────┐ ┌──────────────────────┐ ┌──────────┐
│databasesCron├──►│incrementallyRehash├──►│dictRehashMilliseconds├──►│dictRehash│
└─────────────┘ └───────────────────┘ └──────────────────────┘ └──────────┘
dictRehashMilliseconds 函数传入的 ms 参数表示可以运行多长时间,默认传入的是1,也就是运行1ms就会退出这个函数:
int dictRehashMilliseconds(dict *d, int ms) {
long long start = timeInMilliseconds();
int rehashes = 0;
// 每次会迁移 100 个 bucket
while(dictRehash(d,100)) {
rehashes += 100;
if (timeInMilliseconds()-start > ms) break;
}
return rehashes;
}
调用 dictRehash 函数的时候每次会迁移 100 个 bucket。
总结
之所有要讲 hash 表的实现是因为 Redis 中凡是需要 O(1) 时间获取 kv 数据的场景,都使用了 dict 这个数据结构,而 Redis 用的最多的也就是这种 kv 获取的场景,所以通过这篇文章我们可以清楚的了解到 Redis 的 kv 存储是怎么存放数据的,何时扩容,以及扩容是如何迁移数据的。
看这篇文章的时候不妨对比一下自己所使用的语言中 hash 表是如何实现的。
Reference
https://tech.meituan.com/2018/07/27/redis-rehash-practice-optimization.html
http://redisbook.com/preview/dict/rehashing.html
https://juejin.cn/post/6986102133649063972#heading-1
https://tech.youzan.com/redisyuan-ma-jie-xi/
https://time.geekbang.org/column/article/400379

透过Redis源码探究Hash表的实现的更多相关文章
- 透过Redis源码探究字符串的实现
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com 本文使用的Redis 5.0源码 概述 最近在通过 Redis 学 C 语言,不得不说, ...
- Redis源码研究--跳表
-------------6月29日-------------------- 简单看了下跳表这一数据结构,理解起来很真实,效率可以和红黑树相比.我就喜欢这样的. typedef struct zski ...
- Redis 源码简洁剖析 03 - Dict Hash 基础
Redis Hash 源码 Redis Hash 数据结构 Redis rehash 原理 为什么要 rehash? Redis dict 数据结构 Redis rehash 过程 什么时候触发 re ...
- Redis源码解析之跳跃表(三)
我们再来学习如何从跳跃表中查询数据,跳跃表本质上是一个链表,但它允许我们像数组一样定位某个索引区间内的节点,并且与数组不同的是,跳跃表允许我们将头节点L0层的前驱节点(即跳跃表分值最小的节点)zsl- ...
- Redis源码研究--字典
计划每天花1小时学习Redis 源码.在博客上做个记录. --------6月18日----------- redis的字典dict主要涉及几个数据结构, dictEntry:具体的k-v链表结点 d ...
- [Redis源码阅读]dict字典的实现
dict的用途 dict是一种用于保存键值对的抽象数据结构,在redis中使用非常广泛,比如数据库.哈希结构的底层. 当执行下面这个命令: > set msg "hello" ...
- Redis源码剖析--源码结构解析
请持续关注我的个人博客:https://zcheng.ren 找工作那会儿,看了黄建宏老师的<Redis设计与实现>,对redis的部分实现有了一个简明的认识.在面试过程中,redis确实 ...
- Redis源码阅读(四)集群-请求分配
Redis源码阅读(四)集群-请求分配 集群搭建好之后,用户发送的命令请求可以被分配到不同的节点去处理.那Redis对命令请求分配的依据是什么?如果节点数量有变动,命令又是如何重新分配的,重分配的过程 ...
- Redis源码分析:serverCron - redis源码笔记
[redis源码分析]http://blog.csdn.net/column/details/redis-source.html Redis源代码重要目录 dict.c:也是很重要的两个文件,主要 ...
随机推荐
- 【Java分享客栈】超简洁SpringBoot使用AOP统一日志管理-纯干货干到便秘
前言 请问今天您便秘了吗?程序员坐久了真的会便秘哦,如果偶然点进了这篇小干货,就麻烦您喝杯水然后去趟厕所一边用左手托起对准嘘嘘,一边用右手滑动手机看完本篇吧. 实现 本篇AOP统一日志管理写法来源于国 ...
- 【Electron】使用 build-tools 在 Windows 中编译 electron
[Electron]使用 build-tools 在 Windows 中编译 electron 提前准备 预留好磁盘空间 Git 缓存目录:%UserProfile%/.git_cache ,大概有 ...
- 第一个Python程序 | 机选彩票号码+爬取最新开奖号码
(机选彩票号码+爬取最新开奖号码 | 2021-04-21) 学习记录,好记不如烂笔头 这个程序作用是<机选三种彩票类型的号码> 程序内包含功能有如下: 自动获取最新的三种彩票的开奖号码 ...
- 深入C++06:深入掌握OOP最强大的机制
深入掌握OOP最强大的机制 1. 继承的基本意义 类与类之间的关系:①组合:a part of ... 一部分的关系:②继承: a kind of ... 属于同一种的关系: 继承的本质:a. 代码的 ...
- 好客租房24-react中的事件处理(事件绑定)
3.1事件绑定 React事件绑定语法和DOM事件语法相似 语法:on+事件名称={事件处理程序} 比如οnclick={()=>{}} //导入react import React f ...
- C# 与LINQ有关的语言特性
1.隐式类型 我们知道强类型语言 C C++ C# Java 对变量的定义前必须要确定这个变量是什么类型的 例如 string str="abc"; int num ...
- CF335E Counting Skyscrapers 题解
提供一种最劣解第一且巨大难写的做法( Bob 显然真正的楼量可以达到 \(314!\),是没办法直接做的,再加上唯一方案的样例,可以猜测有简单的结论. 考虑当楼高度为 \(k(k<h)\) 时, ...
- python基础学习5
Python的基础学习5 内容概要 流程控制理论 if判断 while循环 内容详情 流程控制理论 # 流程控制:即控制事物执行的流程 # 执行流程的分类 1.顺序结构 从上往下按顺序依次执行 2.分 ...
- PyTorch DataLoader NumberWorkers Deep Learning Speed Limit Increase
这意味着训练过程将按顺序在主流程中工作. 即:run.num_workers. ,此外, ,因此,主进程不需要从磁盘读取数据:相反,这些数据已经在内存中准备好了. 这个例子中,我们看到了20%的加 ...
- Docker容器手动安装mysql(国内镜像)
Docker手动安装mysql 1.创建centos镜像的容器 [root@localhost Tools]# docker run -i -d -h zabbix --name zabbix -p ...