论文解读(ClusterSCL)《ClusterSCL: Cluster-Aware Supervised Contrastive Learning on Graphs》
论文信息
论文标题:ClusterSCL: Cluster-Aware Supervised Contrastive Learning on Graphs
论文作者:Yanling Wang, Jing Zhang, Haoyang Li, Yuxiao Dong, Hongzhi Yin, Cuiping Li
论文来源:2020, ICML
论文地址:download
论文代码:download
1 Introduction
图上的监督对比学习很难处理拥有较大的类内(intra-class)差异,类间(inter-class)相似性的数据集。
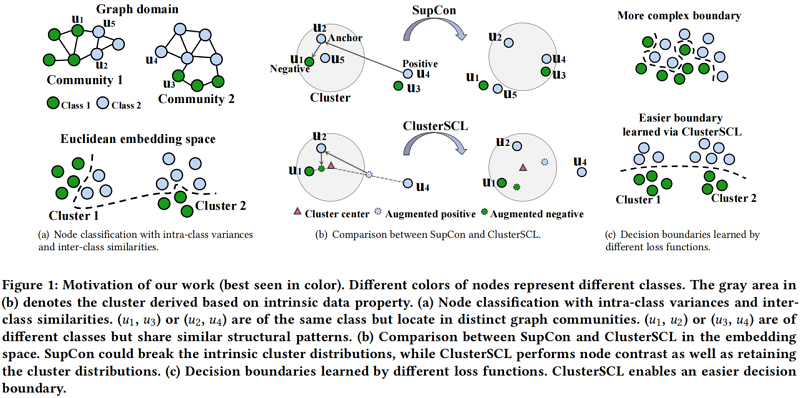
Figure 1(a) 顶部中 $(u_1,u_3)$ 、$(u_2,u_4)$ 属于同一个类,但在不同的图社区(intra-class variances),而 $(u_1,u_2)$、$(u_3,u_4)$ 来自不同的类但在同一图社区(inter-class similarities)。针对上述问题,需要找出一个复杂的决策边界,见 Figure 1(a) 底部。
当执行自监督对比(SupCon)为 $u_{2}$ 寻找锚节点,如 Figure 1(b) 所示,正样本对属于同一类但位于不同的簇,如 $\left(u_{2}, u_{4}\right)$。简单地把正对(相同标签节点)放在同一嵌入空间,可能间接把不同类的节点,如 $\left(u_{2}, u_{3}\right)$ 看成正对,因为 $u_{3}$ 和 $u_{4}$ 社区结构类似。同时,对属于不同类但位于同一簇中的负样本对,如 $\left(u_{2}, u_{1}\right)$,简单地把它们推开可能间接推开同一类的节点,如 $\left(u_{2}, u_{5}\right)$,因为 $u_{5}$ 在结构上与 $u_{1}$ 相似。
上述问题总结为:简单的执行类内差异小,类间方差大的思想,可能会造成分类错误,导致 Figure 1(c) 顶部显示的更复杂的决策边界。
本文的想法简单的如 Figure 1(b) 底部所示。
2 Method
2.1 Base CL Scheme: SupCon
对于批次内的节点 $v_{i}$ 的正样本,其下标集合 $S_{i}$。具体来说,$s_{i} \in S_{i}$ 是 $v_{i}$ 正样本的索引。SupCon 损失函数的形式化如下:
${\large \mathcal{L}_{\text {SupCon }}=-\sum\limits _{v_{i} \in B} \frac{1}{\left|S_{i}\right|} \sum\limits _{s_{i} \in S_{i}} \log \frac{\exp \left(\mathbf{h}_{i}^{\top} \mathbf{h}_{s_{i}} / \tau\right)}{\sum\limits _{v_{j} \in B \backslash\left\{v_{i}\right\}} \exp \left(\mathbf{h}_{i}^{\top} \mathbf{h}_{j} / \tau\right)}} \quad\quad\quad(3)$
其中 $\mathbf{h}$ 代表着 $\ell_{2}$-normalized 表示。
2.2 Proposed CL Scheme: ClusterSCL
假设在SupCon学习过程中存在 $M$ 个需要保留的潜在簇,我们引入潜在变量 $c_{i} \in\{1,2, \ldots, M\}$ 来指示节点 $v_{i}$ 应该聚类到那个簇。给定一个锚定节点 $v_{i}$ 和一个节点 $v_{j}$,CDA 通过以下线性插值,在特征级构造了一个 $v_{j}$ 的增强版本,用于SupCon学习:
$\tilde{\mathbf{h}}_{j}=\alpha \mathbf{h}_{j}+(1-\alpha) \mathbf{w}_{c_{i}} \quad\quad\quad(4)$
其中,$\mathbf{w}=\left\{\mathbf{w}_{m}\right\}_{m=1}^{M}$ 表示簇原型,并在不同的批之间共享。$\tilde{\mathbf{h}}_{j}$ 包含来自 $v_{j}$ 的信息,并且更靠近锚点节点 $v_{i}$ 所属的集群。这些虚拟增强缩小了 SupCon 学习的特征空间,从而远正样本对之间的拉强度和近负样本对之间的推强度,以帮助保留节点的聚类分布。
本质上,$\alpha$ 控制了拉(推)原始样本对 $\left(v_{i}, v_{j}\right)$ 的强度。我们的目标是自动调整每个样本对的 $\alpha$ 值。这样做的主要思想见 Figure 2。
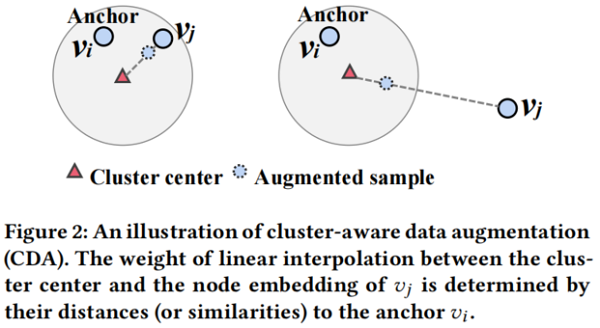
如果锚节点 $v_{i}$ 和对比样本 $v_{j}$ 在嵌入空间中已经保持彼此接近,我们倾向于直接进行对比。因此,我们使用一个更大的 $\alpha$ 来将来自 $v_{j}$ 的更多信息包含到增强的样本中。相反,如果 $v_{i}$ 和 $v_{j}$ 在嵌入空间中彼此远离,我们使用较小的 $\alpha$ 来衰减来自 $v_{j}$ 的信息,以保证锚点和增强样本之间不会太远。考虑到,$\text{Eq.3}$ 明确地模拟了每个正样本对之间的拉力,而不是每个负样本对之间的推,我们从正样本对的角度设计了调整 $\alpha$ 的原则。我们将同样的原理应用于负样本对,实验结果证明 CDA 有效。细化负样本对的原理有待于在今后的工作中进行进一步的研究。在这里,我们计算的权重 $\alpha$ 为:
${\large \alpha=\frac{\exp \left(\mathbf{h}_{i}^{\top} \mathbf{h}_{j}\right)}{\exp \left(\mathbf{h}_{i}^{\top} \mathbf{h}_{j}\right)+\exp \left(\mathbf{h}_{i}^{\top} \mathbf{w}_{c_{i}}\right)}} \quad\quad\quad(5)$
由于 $\mathbf{h}_{i}$ 和 $\mathbf{h}_{j}$ 位于半径为 $1$ 的超球面的表面上,我们有 $\left\|\mathbf{h}_{i}-\mathbf{h}_{j}\right\|^{2}=2-2 \mathbf{h}_{i}^{\top} \mathbf{h}_{j}$,所以一个大的内积等价于一个小的平方欧几里德距离。在高水平上,mixup 和CDA都采用线性插值操作来生成虚拟数据点。在这里,我们想澄清一下CDA与混淆器之间的区别:
- mixup 通过扩大训练集以提高神经网络的泛化能力,而CDA则旨在处理SupCon学习中的类内方差和类间相似性问题。
- 在技术上,mixup 在两个样本之间执行线性插值,而CDA在一个样本和一个聚类之间执行线性插值。具体来说,我们插值一个锚的簇中心和锚的正(负)样本的表示。
- 在学习方面,mixup 是独立于学习过程,而 ClusterSCl 中的 CDA 被集成到学习过程中,以利用可学习的参数。
Integrating Clustering and CDA into SupCon Learning
基于CDA推导出的数据增强,我们对以下实例识别任务进行建模:
${\large \begin{aligned}p\left(s_{i} \mid v_{i}, c_{i}\right) &=\frac{\exp \left(\mathbf{h}_{i}^{\top} \tilde{\mathbf{h}}_{s_{i}} / \tau\right)}{\sum\limits _{v_{j} \in V \backslash\left\{v_{i}\right\}} \exp \left(\mathbf{h}_{i}^{\top} \tilde{\mathbf{h}}_{j} / \tau\right)} \\&=\frac{\exp \left(\mathbf{h}_{i}^{\top}\left(\alpha \mathbf{h}_{s_{i}}+(1-\alpha) \mathbf{w}_{c_{i}}\right) / \tau\right)}{\sum\limits _{v_{j} \in V \backslash\left\{v_{i}\right\}} \exp \left(\mathbf{h}_{i}^{\top}\left(\alpha \mathbf{h}_{j}+(1-\alpha) \mathbf{w}_{c_{i}}\right) / \tau\right)}\end{aligned}} \quad\quad\quad(6)$
在执行 CDA 之前,我们需要通过以下方式知道锚定节点 $v_i$ 属于哪个集群:
${\large p\left(c_{i} \mid v_{i}\right)=\frac{\exp \left(\mathbf{h}_{i}^{\top} \mathbf{w}_{c_{i}} / \kappa\right)}{\sum\limits _{m=1}^{M} \exp \left(\mathbf{h}_{i}^{\top} \mathbf{w}_{m} / \kappa\right)}} \quad\quad\quad(7)$
其中,$\kappa$ 为用于调整预测的聚类分布的软度的温度参数,$p\left(c_{i} \mid v_{i}\right) $ 可以视为一个基于原型的软聚类模块。由于我们已经对软聚类模块 $p\left(c_{i} \mid v_{i}\right)$ 和聚类感知识别器 $p\left(s_{i} \mid v_{i}, c_{i}\right)$ 进行了建模,因此ClusterSCL 可以建模为以下实例识别任务:
$p\left(s_{i} \mid v_{i}\right)=\int p\left(c_{i} \mid v_{i}\right) p\left(s_{i} \mid v_{i}, c_{i}\right) d c_{i} \quad\quad\quad(8)$
Inference and Learning
实际上,由于对数操作内的求和,最大化整个训练数据的对数似然值是不平凡的。我们可以采用 EM 算法来解决这个问题,其中我们需要计算后验分布:
${\large p\left(c_{i} \mid v_{i}, s_{i}\right)=\frac{p\left(c_{i} \mid v_{i}\right) p\left(s_{i} \mid v_{i}, c_{i}\right)}{\sum\limits _{m=1}^{M} p\left(m \mid v_{i}\right) p\left(s_{i} \mid v_{i}, m\right)} } \quad\quad\quad(9)$
然而,由于对整个节点的求和 $\sum\limits _{v_{j} \in V \backslash\left\{v_{i}\right\}} \exp \left(\mathbf{h}_{i}^{\top} \tilde{\mathbf{h}}_{j} / \tau\right)$,计算后验分布是禁止的。我们最大化了由以下方法给出的 $\log p\left(s_{i} \mid v_{i}\right)$ 的 evidence 下界(ELBO):
${\large \begin{array}{l}\log p\left(s_{i} \mid v_{i}\right) &\geq \mathcal{L}_{\operatorname{ELBO}}\left(\boldsymbol{\theta}, \mathbf{w} ; v_{i}, s_{i}\right)\\&\begin{aligned}:=& \mathbb{E}_{q\left(c_{i} \mid v_{i}, s_{i}\right)}\left[\log p\left(s_{i} \mid v_{i}, c_{i}\right)\right] -\operatorname{KL}\left(q\left(c_{i} \mid v_{i}, s_{i}\right) \| p\left(c_{i} \mid v_{i}\right)\right)\end{aligned}\\\end{array}} \quad\quad\quad(10)$
其中 $q\left(c_{i} \mid v_{i}, s_{i}\right)$ 是一个近似后 $p\left(c_{i} \mid v_{i}, s_{i}\right)$。ELBO的推导在附录a中提供。在这里,我们将变分分布形式化为:
${\large q\left(c_{i} \mid v_{i}, s_{i}\right)=\frac{p\left(c_{i} \mid v_{i}\right) \tilde{p}\left(s_{i} \mid v_{i}, c_{i}\right)}{\sum\limits _{m=1}^{M} p\left(m \mid v_{i}\right) \tilde{p}\left(s_{i} \mid v_{i}, m\right)}} \quad\quad\quad(11)$
其中 $\tilde{p}\left(s_{i} \mid v_{i}, c_{i}\right)=\exp \left(\mathbf{h}_{i}^{\top} \tilde{\mathbf{h}}_{s_{i}} / \tau\right) / \sum_{v_{j} \in B \backslash\left\{v_{i}\right\}} \exp \left(\mathbf{h}_{i}^{\top} \tilde{\mathbf{h}}_{j} / \tau\right)$ 在一个批次 $B$ 内计算。请注意,$v_{i}$ 和 $v_{s_{i}}$ 都在该批处理中。此外,我们应用 $\tilde{p}\left(s_{i} \mid v_{i}, c_{i}\right)$ 来估计 $\text{Eq.10}$ 中的 $p\left(s_{i} \mid v_{i}, c_{i}\right)$、并在附录B中作出说明。
我们通过一种变分EM算法来优化模型参数,其中我们在 E 步推断 $q\left(c_{i} \mid v_{i}, s_{i}\right)$,然后在 M 步优化ELBO。对一批节点进行采样,我们可以最大化以下目标:
${\large \mathcal{L}_{\mathrm{ELBO}}(\boldsymbol{\theta}, \mathbf{w} ; B) \approx \frac{1}{|B|} \sum\limits _{v_{i} \in B} \frac{1}{\left|S_{i}\right|} \sum\limits _{s_{i} \in S_{i}} \mathcal{L}_{\operatorname{ELBO}}\left(\boldsymbol{\theta}, \mathbf{w} ; v_{i}, s_{i}\right) } \quad\quad\quad(12)$
我们观察到,只有对集群原型使用随机更新才能得到平凡的解决方案,即大多数实例被分配给同一个集群。为了缓解这一问题,我们在每个训练阶段后应用以下更新:
${\large \mathbf{w}_{m}=\frac{1}{\left|\bar{V}_{m}\right|} \sum\limits_{v_{i} \in \bar{V}_{m}} \mathbf{h}_{i}, m=1,2, \cdots, M } \quad\quad\quad(13)$
其中,$\bar{V}_{m}$ 表示由 METIS 导出的第 $m$ 个图社区中的节点集。在训练之前,我们根据节点间的互连将整个图 $G$ 划分为 $M$ 个图社区。我们使用社区来粗略地描述集群,并对每个社区中的节点嵌入进行平均,以在每个训练阶段后更新集群原型。请注意,ClusterSCL 采用了 $Eq. 7$,为每个节点推导出一个细化的软集群分布。METIS 输出的硬集群分布仅用于原型更新。此外,我们观察到需要对 $\kappa$ 进行细粒度搜索,这是低效的。根据经验,我们使用一个小的 $\kappa$ 来推导一个相对可靠的聚类预测,并引入一个熵项来平滑预测的聚类分布。通过这样做,我们可以避免在 $\kappa$ 上的细粒度搜索。最后,将 ClusterSCL 损失函数形式化为:
${\large \mathcal{L}(\boldsymbol{\theta}, \mathbf{w} ; B)=-\mathcal{L}_{\mathrm{ELBO}}(\boldsymbol{\theta}, \mathbf{w} ; B)+\frac{\eta}{|B|} \sum\limits _{v_{i} \in B} \sum\limits _{c_{i}=1}^{M} p\left(c_{i} \mid v_{i}\right) \log p\left(c_{i} \mid v_{i}\right)} \quad\quad\quad(14)$
其中,$\eta \in(0,1]$ 为控制平滑强度的熵项的权值。
Algorithm 1 显示了使用Clusterscl进行训练的伪代码。我们在附录C中提供了 ClusterSCL 的复杂性分析。

3 Experiments
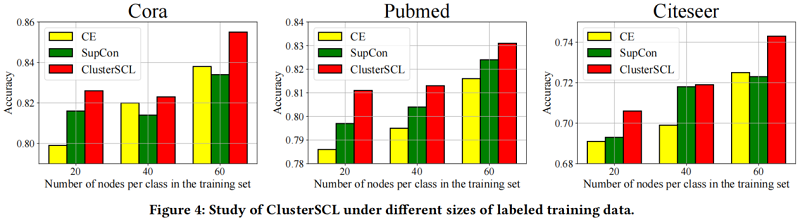
实验通过回答以下研究问题来展开:(1)ClusterSCL 如何在节点分类任务上执行?(2)CDA是否生效?(3)ClusterSCL 在不同大小的标记训练数据下表现如何?
节点分类
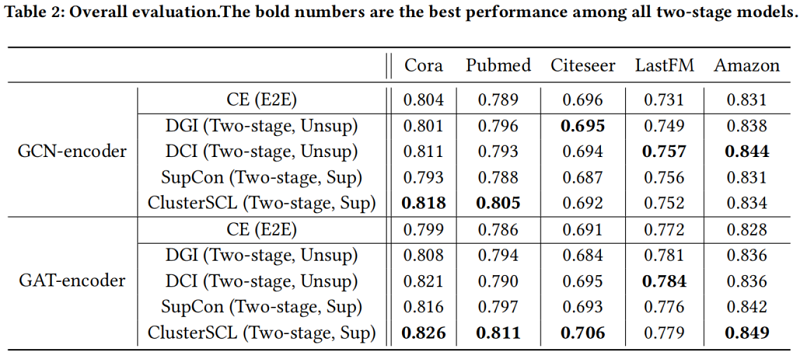
CDA 有效性验证
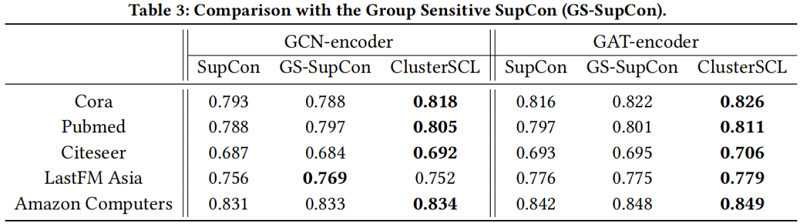
在不同大小的标记训练数据下的 ClusterSCL 的研究
4 Conclusion
这项工作初步研究了用于节点分类的图神经网络的监督学习。我们提出了一种简单而有效的对比学习方案,称为聚类感知监督对比学习(聚类scl)。ClusterSCL改进了监督对比(SupCon)学习,并强调了在SupCon学习过程中保留内在图属性的有效性,从而减少了由类内方差和类间相似性引起的负面影响。ClusterSCL比流行的交叉熵、SupCon和其他图对比损失更具有优势。我们认为,ClusterSCL的思想并不局限于图上的节点分类,并可以启发表示学习的研究。
论文解读(ClusterSCL)《ClusterSCL: Cluster-Aware Supervised Contrastive Learning on Graphs》的更多相关文章
- 论文解读(PCL)《Prototypical Contrastive Learning of Unsupervised Representations》
论文标题:Prototypical Contrastive Learning of Unsupervised Representations 论文方向:图像领域,提出原型对比学习,效果远超MoCo和S ...
- 论文解读(GCA)《Graph Contrastive Learning with Adaptive Augmentation》
论文信息 论文标题:Graph Contrastive Learning with Adaptive Augmentation论文作者:Yanqiao Zhu.Yichen Xu3.Feng Yu4. ...
- 论文解读(Debiased)《Debiased Contrastive Learning》
论文信息 论文标题:Debiased Contrastive Learning论文作者:Ching-Yao Chuang, Joshua Robinson, Lin Yen-Chen, Antonio ...
- 论文解读(AutoSSL)《Automated Self-Supervised Learning for Graphs》
论文信息 论文标题:Automated Self-Supervised Learning for Graphs论文作者:Wei Jin, Xiaorui Liu, Xiangyu Zhao, Yao ...
- 论文解读(BGRL)《Bootstrapped Representation Learning on Graphs》
论文信息 论文标题:Bootstrapped Representation Learning on Graphs论文作者:Shantanu Thakoor, Corentin Tallec, Moha ...
- 论文解读(CGC)《CGC: Contrastive Graph Clustering for Community Detection and Tracking》
论文信息 论文标题:CGC: Contrastive Graph Clustering for Community Detection and Tracking论文作者:Namyong Park, R ...
- 论文解读(MCGC)《Multi-view Contrastive Graph Clustering》
论文信息 论文标题:Multi-view Contrastive Graph Clustering论文作者:Erlin Pan.Zhao Kang论文来源:2021, NeurIPS论文地址:down ...
- 论文解读(MERIT)《Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning》
论文信息 论文标题:Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning ...
- 论文解读(GCC)《Graph Contrastive Clustering》
论文信息 论文标题:Graph Contrastive Clustering论文作者:Huasong Zhong, Jianlong Wu, Chong Chen, Jianqiang Huang, ...
随机推荐
- js--事件循环机制
前言 我们知道JavaScript 是单线程的编程语言,只能同一时间内做一件事,按顺序来处理事件,但是在遇到异步事件的时候,js线程并没有阻塞,还会继续执行,这又是为什么呢?本文来总结一下js 的事件 ...
- 自启动Servlet
自启动servlet也叫自动实例化servlet 特点 该Servlet的实例化过程不依赖于请求,而依赖于容器的启动,当Tomcat启动时就会实例化该Servlet 普通Servlet是在浏览器第一次 ...
- carsim笔记——道路设置
第一步: 进入道路轨迹设置 道路情况设置举例 第二步:设置道路3D的显示效果 对上面的解释举例说明
- (stm32f103学习总结)—输入捕获模式
一.输入捕获介绍 在定时器中断实验章节中我们介绍了通用定时器具有多种功能,输入捕获就是其中一种.STM32F1 除了基本定时器 TIM6 和 TIM7,其他定时器都具有输入捕获功能.输入捕获可以对输入 ...
- 推荐一款强大的轻量级模块化WEB前端快速开发框架--UIkit
前言 今天给大家分享一款强大的轻量级模块化WEB前端快速开发框架--UIkit 到目前(2016-06-20)为止,UIkit在github上的Forks已达到了1350个,而Stars更是达到了69 ...
- H5打造3d场景不完全攻略(一): H5 3d表现形式
前言 日前,taobao造物节H5放肆地火了一把.相信接下来将3d嵌入网站的这种营销方式会被越来越多的人留意到.工作之余体验了若干个3d H5页面,感觉这类的H5互动体验性明显要比普通的要强,把二维的 ...
- js读取cookie 根据cookie名称获取值的方法
//方法1 //存在问题:如果cookie中存在 aaaname=aa;name=bb 获取name的值就会出现错误function getCookie(c_name){ if (document.c ...
- Java实现链表反转(借助栈实现)
public class ListNode { int val; ListNode next = null; ListNode(int val) { this.val = val; } // 添加新的 ...
- Javascript中数组的判断方法
摘要: 1.数组检测的方法: 1) typeof . 2) instanceof . 3) constructor . 4) Object.prototype.toString. 5) Array.i ...
- EMS设置发送连接器和接收连接器邮件大小
任务:通过EMS命令设置发送接收连接器和接收连接器的邮件大小限制值为50MB. 以Exchange管理员身份打开EMS控制台.在PowerShell命令提示符下. 键入以下命令设置接收-连接器的最大邮 ...