新浪使用Redis
新浪微博的工程师们曾经在多个公开场合都讲到过,微博平台当前在使用并维护着可能是世界上最大的Redis集群,其中最大的一个业务,单个业务使用了超过 10T 的内存,这里说的就是微博关系服务。
风起
2009年微博刚刚上线的时候,微博关系服务使用的是最传统的 Memcache+Mysql 的方案。Mysql 按 uid hash 进行了分库分表,表结构非常简单:

业务方存在两种查询:
- 查询用户的关注列表:select touid from table where fromuid=?order by addTime desc
- 查询用户的粉丝列表:select fromuid from table where touid=?order by addTime desc
两种查询的业务需求与分库分表的架构设计存在矛盾,最终导致了冗余存储:以 fromuid 为hash key存一份,以 touid 为hash key再存一份。memcache key 为 fromuid.suffix ,使用不同的 suffix 来区分是关注列表还是粉丝列表,cache value 则为 PHP Serialize 后的 Array。后来为了优化性能,将 value 换成了自己拼装的 byte 数组。
云涌
2011年微博进行平台化改造过程中,业务提出了新的需求:在核心接口中增加了“判断两个用户的关系”的步骤,并增加了“双向关注”的概念。因此两个用户的关系存在四种状态:关注,粉丝,双向关注和无任何关系。为了高效的实现这个需求,平台引入了 Redis 来存储关系。平台使用 Redis 的 hash 来存储关系:key 依然是 uid.suffix,关注列表,粉丝列表及双向关注列表各自有一个不同的 suffix,value 是一个hash,field 是 touid,value 是 addTime。order by addTime 的功能则由 Service 内部 sort 实现。部分大V的粉丝列表可能很长,与产品人员的沟通协商后,将存储限定为“最新的5000个粉丝列表”。
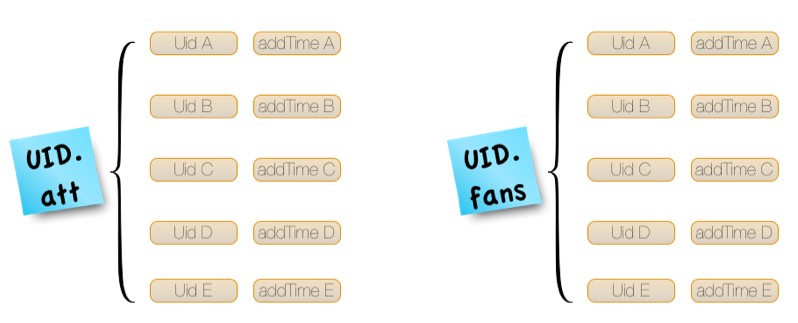
微博关系存储Redis结构
需求实现:
- 查询用户关注列表:hgetAll uid.following ,then sort
- 查询用户粉丝列表:hgetAll uid.follower,then sort
- 查询用户双向关注列表:hgetAll uid.bifollow,then sort
- 判断两个用户关系:hget uidA.following uidB && hget uidB.following uidA
后来又增加了几个更复杂的需求:“我与他的共同关注列表”、“我关注的人里谁关注了他”等等,就不展开来讲了。
平台在刚引入 Redis 的一段时间里踩了不少坑,举几个例子:
1、运维工具和流程从零开始做,运维成熟的速度赶不上业务增长的速度:在还没来得及安排性能调优的工作,fd 已经达到默认配置的上限了,最后我们只能趁凌晨业务低峰期重启 Redis 集群,以便设置新的 ulimit 参数;
2、平台最开始使用的 Redis 版本是 2.0,因为 Redis 代码足够简单,从引入到微博起,我们就开始对其进行了定制化开发,从主从复制,到写磁盘限速,再到内存管理,都进行了定制。导致的结果是,有一段时间,微博的线上存在超过5种不同的 Redis 修改版,对于运维,bugfix,升级都带来了巨大的麻烦。后来由田风军 @果爸果爸 为内部 Redis 版本提供了不停机升级功能后,才慢慢好转。
3、平台有一个业务曾经使用了非默认 db ,后来费了好大力气去做迁移
4、平台还有一个业务需要定期对数据进行 flush db ,以腾出空间存储最新数据。为了避免在 flush db 阶段影响线上业务,我们从 client 到 server 都做了大量的修改。
5、平台每年长假前都会做一些线上业务排查,和故障模拟(2013年甚至做了一个名叫 Touchstone 的容灾压测系统)。2011年十一假前,我们用 iptables 将 Redis 端口的所有包都 drop 掉,结果 client 端等了 120 秒才返回。于是我们在放假前熬夜加班给 client 添加超时检测功能,但真正上线还是等到了假期回来后。
破茧
对于微博关系服务,最大的挑战还是容量和访问量的快速增长,这给我们的 Redis 方案带来了不少的麻烦:
第一个碰到的麻烦是 Redis 的 hgetAll 在 hash size 较大的场景下慢请求比例较高。我们调整了 hash-max-zip-size,节约了1/3的内存,但对业务整体性能的提升有限。最后,我们不得不在 Redis 前面又挡了一层 memcache,用来抗 hgetAll 读的问题。
第二个麻烦是新上的需求:“我关注的人里谁关注了他”,由于用户的粉丝列表可能不全,在这种情况下就不能用关注列表与粉丝列表求交集的方式来计算结果,只能降级到需求的字面描述步骤:取我的关注人列表,然后逐个判断这些人里谁关注了他。client 端分批并行发起请求,还好 Redis 的单个关系判断非常快。
第三个麻烦,也是最大的麻烦,就是容量增长的问题了。最初的设计方案,按 uid hash 成 16 个端口,每台 64G 内存的机器上部署 2 个端口,每个业务 IDC 机房部署一套。后来,每台机器上就只部署一个端口了。再后来,128G 内存的机器还没有进入公司采购目录,64G 内存就即将 OOM 了,所以我们不得不做了一次端口扩容:16端口拆64端口,依然是每台 64G 内存机器上部署 2 个端口。再后来,又只部署一个端口。再后来,升级到 128G 内存机器。再后来,128G 机器上出现 OOM 了!现在怎么办?
化蝶
为了从根本上解决容量的问题,我们开始寻找一种本质的解决方案。最初选择引入 Redis 作为一个 storage,是因为用户关系判断功能请求的数据热点不是很集中,长尾效果明显,cache miss 可能会影响核心接口性能,而保证一个可接受的 cache 命中率,耗费的内存与 storage 差别不大。但微博经过了 3 年的演化,最初作为选择依据的那些假设前提,数据指标都已经发生了变化:随着用户基数的增大,冷用户的绝对数量也在增大;Redis 作为存储,为了数据可靠性必须开启 rdb 和 aof,而这会导致业务只能使用一半的机器内存;Redis hash 存储效率太低,特别是与内部极度优化过的 RedisCounter 对比。种种因素加在一起,最终确定下来的方向就是:将 Redis 在这里的 storage 角色降低为 cache 角色。
前面提到的微博关系服务当前的业务场景,可以归纳为两类:一类是取列表,一类是判断元素在集合中是否存在,而且是批量的。即使是 Redis 作为 storage 的时代,取列表都要依赖前面的 memcache 帮忙抗,那么作为 cache 方案,取列表就全部由 memcache 代劳了。批量判断元素在集合中是否存在,redis hash 依然是最佳的数据结构,但存在两个问题:cache miss 的时候,从 db 中获取数据后,set cache 性能太差:对于那些关注了 3000 人的微博会员们,set cache 偶尔耗时可达到 10ms 左右,这对于单线程的 Redis 来说是致命的,意味着这 10ms 内,这个端口无法提供任何其它的服务。另一个问题是 Redis hash 的内存使用效率太低,对于目标的 cache 命中率来说,需要的 cache 容量还是太大。于是,我们又祭出 “Redis定制化”的法宝:将 redis hash 替换成一个“固定长度开放hash寻址数组”,在 Redis 看来就是一个 byte 数组,set cache 只需要一次 redis set。通过精心选择的 hash 算法及数组填充率,能做到批量判断元素是否存在的性能与原生的 redis hash 相当。
通过微博关系服务 Redis storage 的 cache 化改造,我们将这里的 Redis 内存占用降低了一个数量级。它可能会失去“最大的单个业务Redis集群”的头衔,但我们比以前更有成就感,更快乐了。
新浪使用Redis的更多相关文章
- 新浪计数业务之Redis
今天听一个同事说新浪使用的是Redis,于是自己将研究的过程整理出来以备后用. 我们都知道微博这玩意儿现在很火,新浪作为国内最早使用redis,并且是国内最大的redis使用者,当然备受人们关注.新浪 ...
- Python 爬虫实例(7)—— 爬取 新浪军事新闻
我们打开新浪新闻,看到页面如下,首先去爬取一级 url,图片中蓝色圆圈部分 第二zh张图片,显示需要分页, 源代码: # coding:utf-8 import json import redis i ...
- python爬虫---实现项目(四) 用BeautifulSoup分析新浪新闻数据
这次只演示了,如何在真实项目内用到BeautifulSoup库来解析网页,而新浪的新闻是ajax加载过来的数据,在这里我们只演示解析部分数据(具体反扒机制没做分析). 代码地址:https://git ...
- 2019 新浪 java面试笔试题 (含面试题解析)
本人5年开发经验.18年年底开始跑路找工作,在互联网寒冬下成功拿到阿里巴巴.今日头条.新浪等公司offer,岗位是Java后端开发,因为发展原因最终选择去了新浪,入职一年时间了,也成为了面试官,之 ...
- 最新 新浪java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿.新浪等10家互联网公司的校招Offer,因为某些自身原因最终选择了新浪.6.7月主要是做系统复习.项目复盘.LeetCode ...
- 豪情-CSS解构系列之-新浪页面解构-01
目录: 一. 新浪的布局特点 二. 内容细节的特点 三. 其中相关的一些基础技术点 1. 常见布局方法 2. 布局要点 3. Debugger误区 4.列表 5.字体颜色 6.CSS选择符 7.CSS ...
- python网络爬虫 新浪博客篇
上次写了一个爬世纪佳缘的爬虫之后,今天再接再厉又写了一个新浪博客的爬虫.写完之后,我想了一会儿,要不要在博客园里面写个帖子记录一下,因为我觉得这份代码的含金量确实太低,有点炒冷饭的嫌疑,就是把上次的代 ...
- ip地址库 新浪,淘宝
原文连接地址:http://www.9958.pw/post/city_ip function getAddressFromIp($ip){ $urlTaobao = 'http://ip.taoba ...
- 用极简方式实现新浪新版本特性展示效果--view的图片轮播
在发布版本的时候,大多数软件会在第一次使用新版本时候弹出视图用几张图片给用户做一个新版本特性介绍,最简单如下图新浪的版本特性介绍 由于图片是全屏展示且是左右滑动,大多数情况开发者会选择使用scroll ...
随机推荐
- POJ 1740
#include <iostream> #define MAXN 100 using namespace std; int _m[MAXN]; bool mark[MAXN]; int m ...
- package.json 字段全解析 share
Name 必须字段. 小提示: 不要在name中包含js, node字样: 这个名字最终会是URL的一部分,命令行的参数,目录名,所以不能以点号或下划线开头: 这个名字可能在require()方法中被 ...
- Hibernate逍遥游记-第13章 映射实体关联关系-002用主键映射一对一(<one-to-one constrained="true">、<generator class="foreign">)
1. <?xml version="1.0"?> <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hi ...
- [图解教程]Eclipse不可不知的用法之一:自动生成Getter、Setter和构造方法
[图解教程]Eclipse不可不知的用法之一:自动生成Getter.Setter和构造方法 关键词:Getters and Setters.getter和setter方法.Constructor us ...
- 常用的Linux终端
常用的Linux终端 gnome-terminal (Gnome标配) xfce4-terminal (XFCE4标配) lxterminal (LXDE标配) konsole (KDE标配) 前面3 ...
- 在C#中怎么调用Resources文件中的图片
譬如资源中有名为myPic的图片,在代码中可以这么使用: this.BackgroundImage = Properties.Resources.myPic; 如有疑问,继续追问.
- VS2010/MFC编程入门教程之目录和总结
鸡啄米的这套VS2010/MFC编程入门教程到此就全部完成了,虽然有些内容还未涉及到,但帮助大家进行VS2010/MFC的入门学习业已足够.以此教程的知识为基础,学习VS2010/MFC较为深入的内容 ...
- HttpServletRequest接口实例化的使用
HttpServletRequ接口的使用和jsp内置对象的request对象非常类似,request对象其实 就是HttpServletRequest接口的一个实例,不过气实例化的过程是自动的,无须自 ...
- java 日期格式转换EEE MMM dd HH:mm:ss z yyyy
SimpleDateFormat parserSDF = new SimpleDateFormat("EEE MMM dd HH:mm:ss zzzz yyyy", Locale. ...
- Restful api测试插件Swagger-UI
现在多数的项目开发中,网站和移动端都需要进行数据交互和对接,这少不了使用REST编写API接口这种场景.例如我目前的工作,移动端交由了另一团队开发,不同开发小组之间就需要以规范和文档作为标准和协作基础 ...