02_Kafka单节点实践
1、实践场景
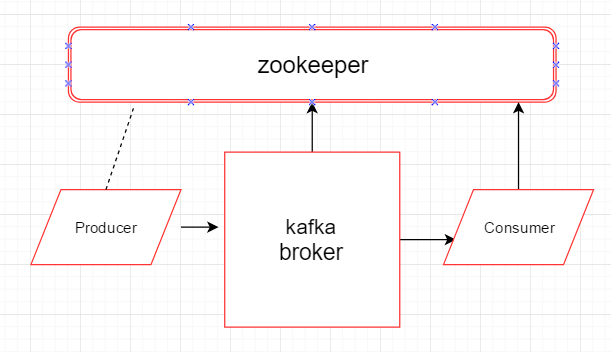
开始前的准备条件:
1) 确认各个节点的jdk版本,将jdk升级到和kafka配套的版本(解压既完成安装,修改/etc/profile下的JAVA_HOME,source /etc/profile,重启后jdk生效)
2、单节点kafka实践
1) 启动zookeeper集群
各个节点上启动zookeeper进程
# bin/zkServer.sh start
启动后,查看各个节点的zookeeper状态 (leader, follower etc)
#bin/zkServer.sh status
2) 配置kafka的zk集群
配置文件:config/zookeeper.properties
配置要点:zookeeper中snapshot数据的存放地址,和zookeeper集群中的配置保持一致
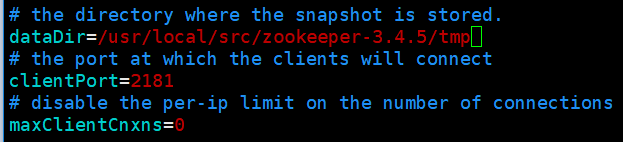
3) 配置本节点上要启动的broker
配置文件: config/server.properties
配置要点:
broker.id
log.dirs (将在该路径下自动创建partition目录)
zookeeper.connect (broker要连接的zookeeper集群地址和port)
检查broker发布给producer和consumer的主机名和端口号(9092)
配置后的参数如下:
# broker id, 每个broker的id必须是唯一的
broker.id= # kafka存放消息的目录
log.dirs=/usr/local/src/kafka_2./tmp/ # broker连接的zk集群,节点间通过逗号分隔,默认zk开放给客户端连接的端口号是2181
zookeeper.connect=master:,slave1:,slave2:

注意:
1) 默认Kafka会直接在ZooKeeper的根路径下创建znode,这样Kafka的ZooKeeper配置就会散落在根路径下面
2) 可以指定kafka在zookeeper的某个路径下去进行操作, 将server.properties中的zookeeper.connect修改为:
a. zookeeper.connect=master:2181,slave1:2181,slave2:2181/kafka
b. 同时手动在zookeeper中创建/kafka节点 (create /kafka)
4)启动单个Broker
# ./bin/kafka-server-start.sh ./config/server.properties

5)查看当前kafka集群中的Topic
# ./bin/kafka-topics.sh --list --zookeeper master:2181,slave1:2181,slave2:2181
# ./bin/kafka-topics.sh --list --zookeeper master:2181,slave1:2181,slave2:2181/kafka # 如果修改了kafka在zookeeper下的znode节点路径,则要在--zookeeper参数中跟上chroot路径
6) 创建topic
创建Topic时,会根据broker的个数,对replication-factor进行校验;
# ./bin/kafka-topics.sh --create --zookeeper master:2181,slave1:2181,slave2:2181 --replication-factor 1 --partitions 1 --topic mytopic
7) 查看topic描述信息
# ./bin/kafka-topics.sh --describe --zookeeper master:2181,slave1:2181,slave2:2181 --topic mytopic

partition:0 该partition的编号,从0开始
leader:0 该partition的leader节点的broker.id = 0
replicas:0 表示partition落地的所有broker, 包括leader在内
isr:0 当前处于in-sync的replicas节点, 包括leader在内, broker.id = 0
8) zookeeper上将记录kafka已经创建的topic

9)broker的log.dirs中将创建partition目录
目录名:topic名-partition编号 //编号从0开始
mytopic-0

10)Partition目录下的segment文件
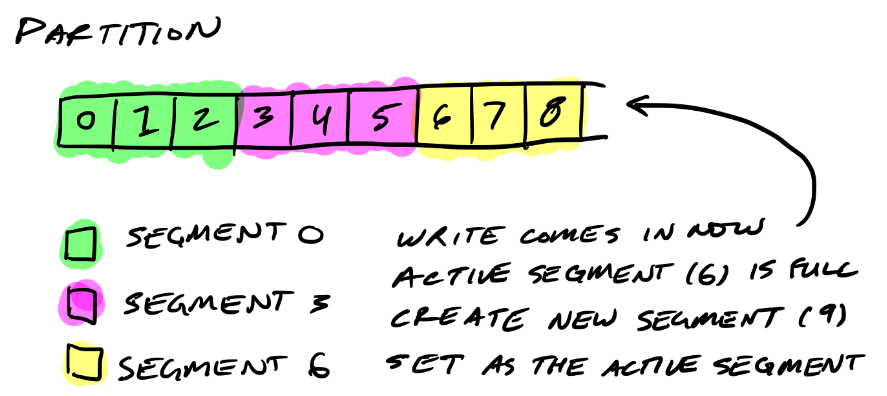
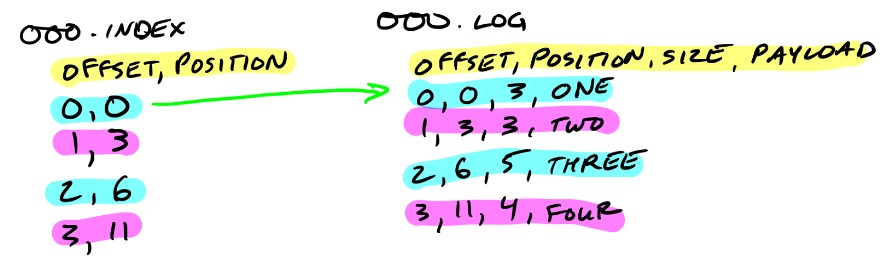
每一个segment,都会由 log文件,index文件 组成

解析:
xxxx.log -- 最初的log文件,文件名是初始偏移(base offset), 消息存储在log文件
xxxx.index -- 最初的index文件,文件名是初始偏移(base offset),index则用于对应log文件内的消息检索
offset, postion
offset, 消息计数; postion,消息头在log文件中的起始位置(position从0开始)
index文件可以映射到内存,从index文件的名字可以判断出某一个消息应该位于哪一个log文件
segment文件的默认最大size为1G,超过该size后才会创建新的segment文件,新的segment文件将称为active segment, 数据是向active segment写入
11) 调整Topic的partition个数
只能增加,不能减少
# ./bin/kafka-topics.sh --alter --zookeeper master:2181,slave1:2181,slave2:2181 --topic mytopic --partitions 2

物理的partition目录,也变为了2个

12)使用kafka提供的Producer客户端,模拟消息发送
# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic mytopic
--broker-list: 该producer要向哪些broker推送消息, ip:port形式说明
--topic: 该producer要向哪一个Topic发送消息
启动producer客户端后,每行都会作为一条message, 存储到该topic的partition文件下的log文件中

13) 查看log文件中,消息落地到了哪里
1) 由于消息中没有指定key, kafka将针对每条message,随机找一个partition进行存放
2)4条消息,存储到了两个分区mytopic-0和mytopic-1下
mytopic-0分区,log文件存储了2条消息

mytopic-1分区,log文件存储了2条消息

14)启动Consumer, 模拟消息的消费
1、Consumer消费消息时,只需要指定topic+offset
2、通过zookeeper获取topic的partition位于哪些broker上,各自的leader broker是谁,然后和leader broker连接,获取数据
./bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic mytopic --from-beginning
3、观察多个partition下,consumer端数据的顺序
topic有2个分区,consumer端得到的数据顺序和发送端的不一定相同,但每个partiton内部的消息顺序能够保证(非全局有序,partition内部有序)

02_Kafka单节点实践的更多相关文章
- 02_Flume1.6.0安装及单节点Agent实践
Flume1.6.0的安装1.上传Flume-1.6.0-tar.gz到待部署的所有机器 以我的为例: /usr/local/src/ 2.解压得到flume文件夹 # tar -x ...
- 恒天云单节点部署指南--OpenStack H版本虚拟机单节点部署解决方案
本帖是openstack单节点在虚拟机上部署的实践.想要玩玩和学习openstack的小伙伴都看过来,尤其是那些部署openstack失败的小伙伴.本帖可以让你先领略一下openstack的魅力.本I ...
- Hadoop 2.2.0单节点的伪分布集成环境搭建
Hadoop版本发展历史 第一代Hadoop被称为Hadoop 1.0 1)0.20.x 2)0.21.x 3)0.22.x 第二代Hadoop被称为Hadoop 2.0(HDFS Federatio ...
- ASP.NET Core on K8S学习初探(1)K8S单节点环境搭建
当近期的一个App上线后,发现目前的docker实例(应用服务BFF+中台服务+工具服务)已经很多了,而我司目前没有专业的运维人员,发现运维的成本逐渐开始上来,所以容器编排也就需要提上议程.因此我决定 ...
- 阿里云ECS单节点Kubernetes部署
参考资料: kubernetes官网英文版 kubernetes官网中文版 环境.工具 阿里云学生机ECS.Ubuntu.docker.kubectl1.15.4.kubelet1.15.4.kube ...
- 阿里云ECS(Ubuntu)单节点Kubernetes部署
参考资料: kubernetes官网英文版 kubernetes官网中文版 前言 这篇文章是比较久之前写的了,无聊翻了下博客发现好几篇博文排版莫名其妙的变了... 于是修改并完善了下.当初刚玩k8s的 ...
- Vertica集群单节点宕机恢复方法
Vertica集群单节点宕机恢复方法 第一种方法: 直接通过admintools -> 5 Restart Vertica on Host 第二种方法: 若第一种方法无法恢复,则清空宕机节点的c ...
- Hbase入门教程--单节点伪分布式模式的安装与使用
Hbase入门简介 HBase是一个分布式的.面向列的开源数据库,该技术来源于 FayChang 所撰写的Google论文"Bigtable:一个结构化数据的分布式存储系统".就像 ...
- 基于英特尔® 至强 E5 系列处理器的单节点 Caffe 评分和训练
原文链接 在互联网搜索引擎和医疗成像等诸多领域,深度神经网络 (DNN) 应用的重要性正在不断提升. Pradeep Dubey 在其博文中概述了英特尔® 架构机器学习愿景. 英特尔正在实现 Prad ...
随机推荐
- [LeetCode] 182. Duplicate Emails_Easy tag: SQL
Write a SQL query to find all duplicate emails in a table named Person. +----+---------+ | Id | Emai ...
- js模拟电梯操作
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- malloc 实现原理
1. Reference: 如何实现一个malloc http://blog.codinglabs.org/articles/a-malloc-tutorial.html 2.
- 剑指offer4
中序遍历(LDR)是二叉树遍历的一种,也叫做中根遍历.中序周游.在二叉树中,先左后根再右.巧记:左根右. 现在有一个问题,已知二叉树的前序遍历和中序遍历:PreOrder: GDAFE ...
- #C++初学记录(ACM试题2)
Max Sum Given a sequence a[1],a[2],a[3]......a[n], your job is to calculate the max sum of a sub-seq ...
- cxf-webservice完整示例
最近一段时间研究webservice,一般来说,开发java的Webservice经常使用axis2和cxf这两个比较流行的框架 先使用cxf,开发一个完整示例,方便对webservice有一个整体的 ...
- javascript 判断数据类型
Object.prototype.toString.call(asddfff) //报错asddfff没被定义Object.prototype.toString.call(undefined) //& ...
- UVM中Callback机制
Callback机制,其实是使用OOP来实现的一种程序开发者向程序使用者提供的模块内部的接口.可以在Test_case的高度改变其他component的一些行为. Systemverilog中已经提供 ...
- EOJ Monthly 2018.11 猜价格 (模拟)
分三种情况: 1.k=1.此时每次都说反话,反着二分即可. 2.1<k <= n.那么在前n次问答中一定会出现一次错误,通过不断输出1找出那个错误发生的位置(若回答是>那这就是错误) ...
- memcache 基础原理
memcache是一套分布式的高速缓存系统,由LiveJournal的Brad Fitzpatrick开发,但目前被许多网站使用以提升网站的访问速度,尤其对于一些大型的.需要频繁访问数据库的网站访问速 ...