第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
scrapy-redis是一个可以scrapy结合redis搭建分布式爬虫的开源模块
scrapy-redis的依赖
- Python 2.7, 3.4 or 3.5,Python支持版本
- Redis >= 2.8,Redis版本
Scrapy>= 1.1,Scrapy版本redis-py>= 2.10,redis-py版本,redis-py是一个Python操作Redis的模块,scrapy-redis底层是用redis-py来实现的
下载地址:https://pypi.python.org/pypi/scrapy-redis/0.6.8
我们以scrapy-redis/0.6.8版本为讲
一、安装scrapy-redis/0.6.8版本的依赖
首先安装好scrapy-redis/0.6.8版本的依赖关系模块和软件
二、创建scrapy项目
执行命令创建项目:scrapy startproject fbshpch
三、将下载的scrapy-redis-0.6.8模块包解压,解压后将包里的crapy-redis-0.6.8\src\scrapy_redis的scrapy_redis文件夹复制到项目中
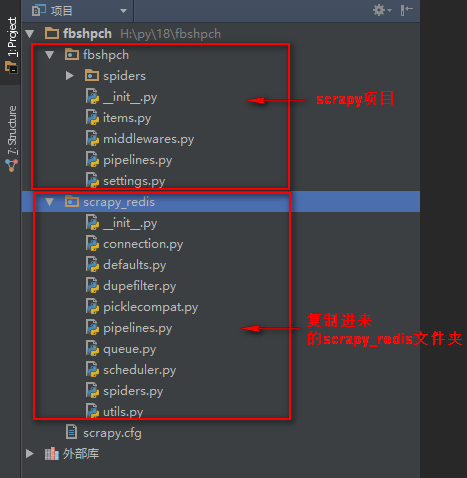
四、分布式爬虫实现代码,普通爬虫,相当于basic命令创建的普通爬虫
注意:分布式普通爬虫必须继承scrapy-redis的RedisSpider类
#!/usr/bin/env python
# -*- coding:utf8 -*- from scrapy_redis.spiders import RedisSpider # 导入scrapy_redis里的RedisSpider类
import scrapy
from scrapy.http import Request #导入url返回给下载器的方法
from urllib import parse #导入urllib库里的parse模块 class jobboleSpider(RedisSpider): # 自定义爬虫类,继承RedisSpider类
name = 'jobbole' # 设置爬虫名称
allowed_domains = ['blog.jobbole.com'] # 爬取域名
redis_key = 'jobbole:start_urls' # 向redis设置一个名称储存url def parse(self, response):
"""
获取列表页的文章url地址,交给下载器
"""
# 获取当前页文章url
lb_url = response.xpath('//a[@class="archive-title"]/@href').extract() # 获取文章列表url
for i in lb_url:
# print(parse.urljoin(response.url,i)) #urllib库里的parse模块的urljoin()方法,是自动url拼接,如果第二个参数的url地址是相对路径会自动与第一个参数拼接
yield Request(url=parse.urljoin(response.url, i),
callback=self.parse_wzhang) # 将循环到的文章url添加给下载器,下载后交给parse_wzhang回调函数 # 获取下一页列表url,交给下载器,返回给parse函数循环
x_lb_url = response.xpath('//a[@class="next page-numbers"]/@href').extract() # 获取下一页文章列表url
if x_lb_url:
yield Request(url=parse.urljoin(response.url, x_lb_url[0]),
callback=self.parse) # 获取到下一页url返回给下载器,回调给parse函数循环进行 def parse_wzhang(self, response):
title = response.xpath('//div[@class="entry-header"]/h1/text()').extract() # 获取文章标题
print(title)
五、分布式爬虫实现代码,全站自动爬虫,相当于crawl命令创建的全站自动爬虫
注意:分布式全站自动爬虫必须继承scrapy-redis的RedisCrawlSpider类
#!/usr/bin/env python
# -*- coding:utf8 -*- from scrapy_redis.spiders import RedisCrawlSpider # 导入scrapy_redis里的RedisCrawlSpider类
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import Rule class jobboleSpider(RedisCrawlSpider): # 自定义爬虫类,继承RedisSpider类
name = 'jobbole' # 设置爬虫名称
allowed_domains = ['www.luyin.org'] # 爬取域名
redis_key = 'jobbole:start_urls' # 向redis设置一个名称储存url rules = (
# 配置抓取列表页规则
# Rule(LinkExtractor(allow=('ggwa/.*')), follow=True), # 配置抓取内容页规则
Rule(LinkExtractor(allow=('.*')), callback='parse_job', follow=True),
) def parse_job(self, response): # 回调函数,注意:因为CrawlS模板的源码创建了parse回调函数,所以切记我们不能创建parse名称的函数
# 利用ItemLoader类,加载items容器类填充数据
neir = response.css('title::text').extract()
print(neir)
六、settings.py文件配置
# 分布式爬虫设置
SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 使调度在redis存储请求队列
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 确保所有的蜘蛛都共享相同的过滤器通过Redis复制
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300 # 存储在redis刮项后处理
}
七、执行分布式爬虫
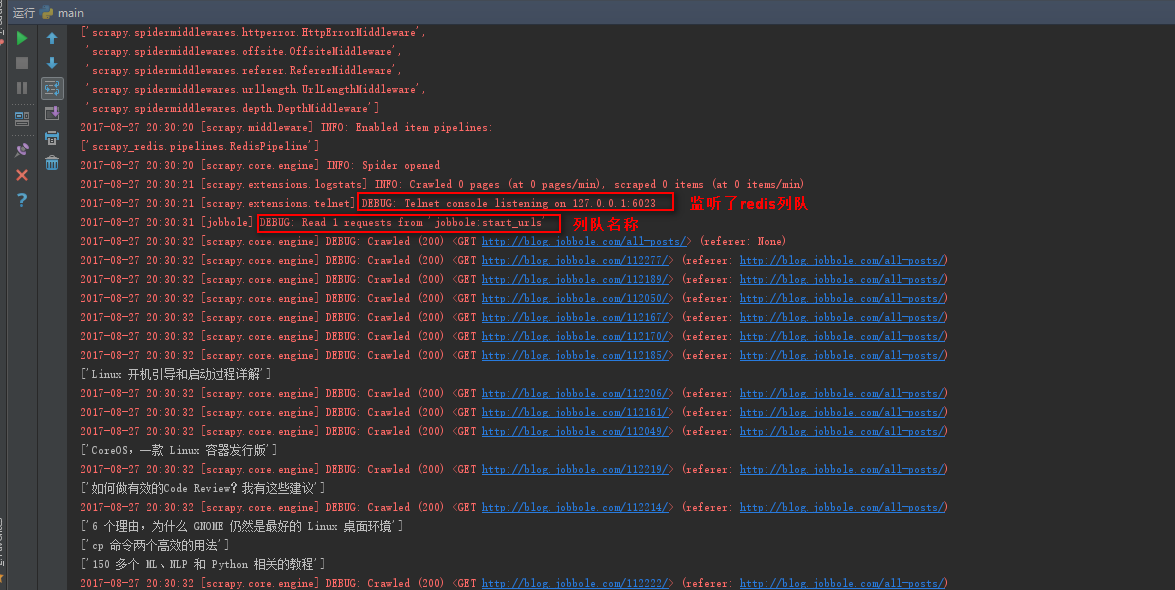
1、运行命令:scrapy crawl jobbole(jobbole表示爬虫名称)
2、启动redis,然后cd到redis的安装目录,
执行命令:redis-cli -h 127.0.0.1 -p 6379 连接一个redis客户端
在连接客户端执行命令:lpush jobbole:start_urls http://blog.jobbole.com/all-posts/ ,向redis列队创建一个起始URL
说明:lpush(列表数据) jobbole:start_urls(爬虫里定义的url列队名称) http://blog.jobbole.com/all-posts/(初始url)
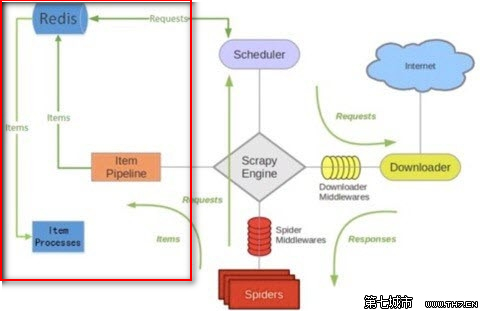
八、scrapy-redis编写分布式爬虫代码原理
其他使用方法和单机版爬虫一样
第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码的更多相关文章
- 第三百七十七节,Django+Xadmin打造上线标准的在线教育平台—apps目录建立,以及数据表生成
第三百七十七节,Django+Xadmin打造上线标准的在线教育平台—apps目录建立,以及数据表生成 apps目录建立 我们创建一个apps目录,将所有的app放到apps目录里去,这样方便管理,也 ...
- 第三百九十七节,Django+Xadmin打造上线标准的在线教育平台—其他插件使用说,主题本地化设置
第三百九十七节,Django+Xadmin打造上线标准的在线教育平台—其他插件使用说,主题本地化设置 主题设置是在xadmin\plugins\themes.py这个文件 默认xadmin是通过下面这 ...
- 第三百八十七节,Django+Xadmin打造上线标准的在线教育平台—网站上传资源的配置与显示
第三百八十七节,Django+Xadmin打造上线标准的在线教育平台—网站上传资源的配置与显示 首先了解一下static静态文件与上传资源的区别,static静态文件里面一般防止的我们网站样式的文件, ...
- 三十六 Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
scrapy-redis是一个可以scrapy结合redis搭建分布式爬虫的开源模块 scrapy-redis的依赖 Python 2.7, 3.4 or 3.5,Python支持版本 Redis & ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
- 第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中
第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中 1.爬虫文件 dispatcher.connect()信号分发器,第一个参数信 ...
- 第三百五十节,Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求
第三百五十节,Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求 selenium模块 selenium模块为 ...
- 第三百五十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—chrome谷歌浏览器无界面运行、scrapy-splash、splinter
第三百五十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—chrome谷歌浏览器无界面运行.scrapy-splash. splinter 1.chrome谷歌浏览器无界面运行 chrome ...
- 第三百二十七节,web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
第三百二十七节,web爬虫讲解2—urllib库爬虫 利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode(& ...
随机推荐
- linux系统查毒软件ClamAV
安装方法: 长久使用参考: http://www.cnblogs.com/kerrycode/archive/2015/08/24/4754820.html#undefined 临时使用参考: htt ...
- python--使用MySQL数据库
1.安装mysqlsudo apt-get install mysql-server Sudo apt-get install mysql-client 2.安装MySQL-python驱动sudo ...
- 每日英语:Are Smartphones Turning Us Into Bad Samaritans?
In late September, on a crowded commuter train in San Francisco, a man shot and killed 20-year-old s ...
- 关于RPG游戏结构撰写的相关探索下篇
如今市面上已经有好几百种免费RPG系统,我们都能够按照自己的需求对此进行扩展与修改.通过选择现有的系统(特别是较有名的),你能够从一个稳定且经过测试的基础开始创 造. 但是之后你需要基于设置和规则对此 ...
- vue2 如何操作dom
在vue中可以通过给标签加ref属性,就可以在js中利用ref去引用它,从而操作该dom元素,以下是个例子,可以当做参考 <template> <div> <div id ...
- vue中使用animate.css动画库
1.安装: npm install animate.css --save 2.引入及使用: //main.js中 import animated from 'animate.css' Vue.use( ...
- Java springboot项目的jar发布方式
做springboot的都知道,发布方式不是war发布了,是jar发布,启动jar就可以直接运行,并且环境都是集成的. 首先,先将项目打包成jar,这里假设你的eclipse已经安装了maven插件. ...
- 【Java】使用BigDecimal类进行精确小数计算
在商业计算中(尤其是计算价格)需要使用BigDecimal类来进行精确小数计算,因为用其他类型计算(如double)得到的结果不是精确的! 写个测试类. import org.junit.Test; ...
- 【WPF/C#】图层筛选/拾取——Color Picker
文章标题实在不懂怎么表述才清楚. 描述问题:多个图片(图层)重叠时,如何通过鼠标点击来拾取到相应的图层.因为图层中会有很多空白的地方(比如图片四周),要求是获取鼠标点击位置的像素颜色值,如果为空白时或 ...
- gulp实例
前端生产环境的简单部署http://ionichina.com/topic/558a1c1346cb5ff7268cee9d var gulp = require('gulp'); // 引入gulp ...