MaxCompute 表(Table)设计规范
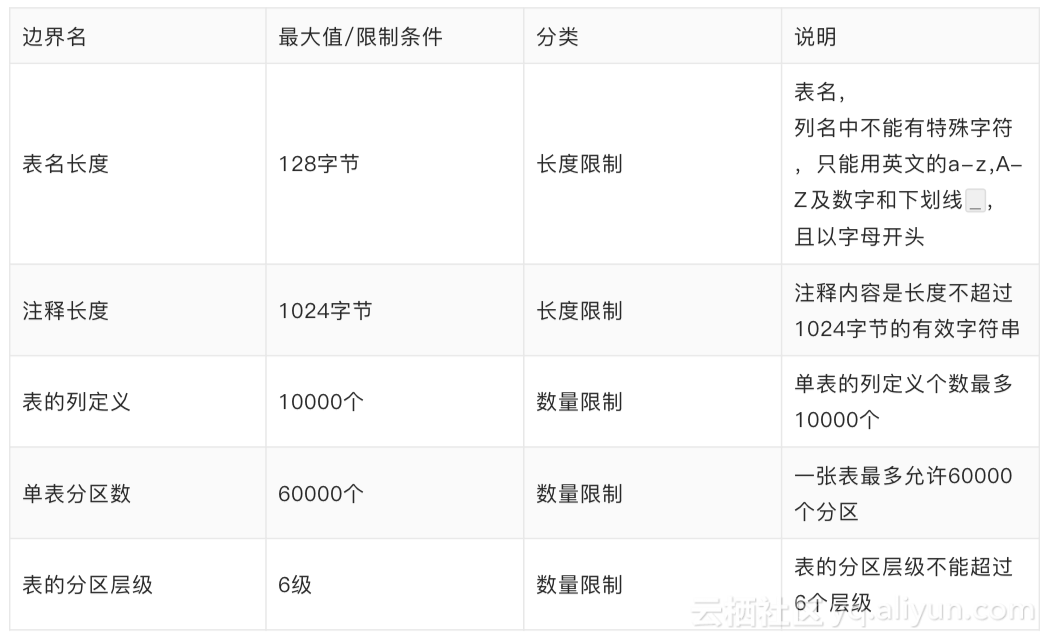
- 表的限制项
表(Table)设计规范 表设计主要目标
- 表设计的影响
- 表设计步骤
表数据存储规范
- 按数据分层规范数据生命周期
- 按数据的变更和历史规范数据的保存
- 数据导入通道与表设计
- 分区设计与逻辑存储的对应
- 表和分区设计基本规则
分区设计
- 分区字段和普通字段的选择
- 分区字段定义依据
- 分区个数定义依据
- 分区数量和数据量建议
表的限制项
表(Table)设计规范 表设计主要目标
- 降低存储成本。 合适的表设计可以在数据分层设计上降低冗余存储,减少中间表数据量大小。同时正 确的对表数据进行生命周期管理,更能够直接降低存储的数据量以降低存储成本。
- 降低计算成本。 对表设计规范化,以便在后续对表数据进行查询计算过程中,可以依据这些规范优化 数据的读取,减少计算过程中的冗余读写和计算,提升计算性能的同时降低成本。
- 降低维护复杂度。 规范化的表分层设计能够直接体现业务的特点。如通过对数据通道中数据采集方式 进行优化,同时对表进行规范化设计,可以减少分布式系统中小文件的问题,同时也减少表和分区维 护的数量等复杂度。
表设计的影响
影响的操作:表创建/入数据/表更新/表删除/表管理。 导入数据场景(区分要做实时数据采集还是离线批 量数据写入):
- 导入即查询与计算。
- 多次导入,定时查询与计算。
- 导入后生成中间表进行计算。
注意: - 合理的表设计和数据集成周期管理能够使数据在存储期间降低成本。 - MaxCompute优先作为批量数据集成库以及按业务逻辑进行计算,如按照分区进行计算。
- 导入后立即查询与计算,需要考虑每次导入数据量,减少流式小量数据导入。
- 不合理的数据导入及存储(小文件)会对整体存储性能,计算性能,运维稳定性造成影响。
表设计步骤
- 确定所属项目空间,依据业务过程规划表类型,属于哪个数据层次。
- 定义表描述,权限定义与Owner定义。
- 依据数据量、数据集成特点定义分区表或者非分区表。
- 定义字段,或分区字段
- 表创建/表转换
- 明确导入数据场景的相关因素(包括批量数据写入/流式数据写入/条式数据插入)。
- 定义表和分区数据生命周期。
注意:
- 表创建之后可以依据业务变化进行表schema的修改,如设置生命周期,RangeClustering。
- 在设计阶段需要特别注意区分数据的场景(批量数据写入/流式数据写入/周期性条式数据插入)。
- 合理使用非分区表和分区表。日志表,事实表,原始采集表等建议使用分区表,按照时间分区。
- 注意各种表和分区的限制条件。
表数据存储规范
按数据分层规范数据生命周期
- 源表ODS层: 每天从业务系统同步过来的数据,全部保留,生命周期定义永久保存。以防备下游数据 受损时可以从ODS恢复。若ODS每天同步过来的是全量表,可以通过全表拉链的方式来压缩存储。
- 数据仓库(基础)层: 至少保留一份完整的全量数据(不必像ODS那样冗余多份全量)。考虑到性能 因素,可以考虑拆表或者做分区。
- 数据集市层: 按需保留1~3年时⻓。数据集市的数据较容易生成,无需保留那么⻓时间的历史数据
按数据的变更和历史规范数据的保存
会变化数据怎么存:
- 客户属性、产品属性天天变,将这些属性的历史变化情况记录下来,以方便追溯某个时点的值。
- 在事实表里面冗余维表的字段,即把”事件发生时“的各种维度属性值与该事件绑定起来。 比较方便使 用者,不需关联多张表就可以用数据,在数据应用层使用。
- 用拉链表或者日快照的形式,记录维表的变化情况。 比较方便数据加工者,数据结构灵活,扩展方 便,容易管理,且数据一致性更好。在数据基础层使用。
数据导入通道与表设计
通道类型:
- Datahub ,规划写入的分区以及写入流量的关系,做到64M commit一次。
- 数据集成或DataX,规划写入的表分区的频率,做到64M commit一次,避免commit空目录。 DTS,规划写入的表存量分区与增量分区的关系,做commit频率设置。
- Console (Run SQL or Tunnel upload),避免高频小数据量文件的插入或者上传。
- SDK Run Sql之insert into,对表或者分区上传时需要注意插入到分区后进行小文件整理操作,避免 对一个分区或者非分区表插入多次,插入后需要merge。
注意:
- MaxCompute导入数据的通道只有Tunnel SDK或者执行SQL的Insert into,避免流式插入。
- 以上各通道本身均有自身逻辑进行流式数据写入, 批量数据写入,周期调度写入。
- 数据通道写表或分区时需要注意将一次写入的数据量控制在合理的值如64M以上。
分区设计与逻辑存储的对应
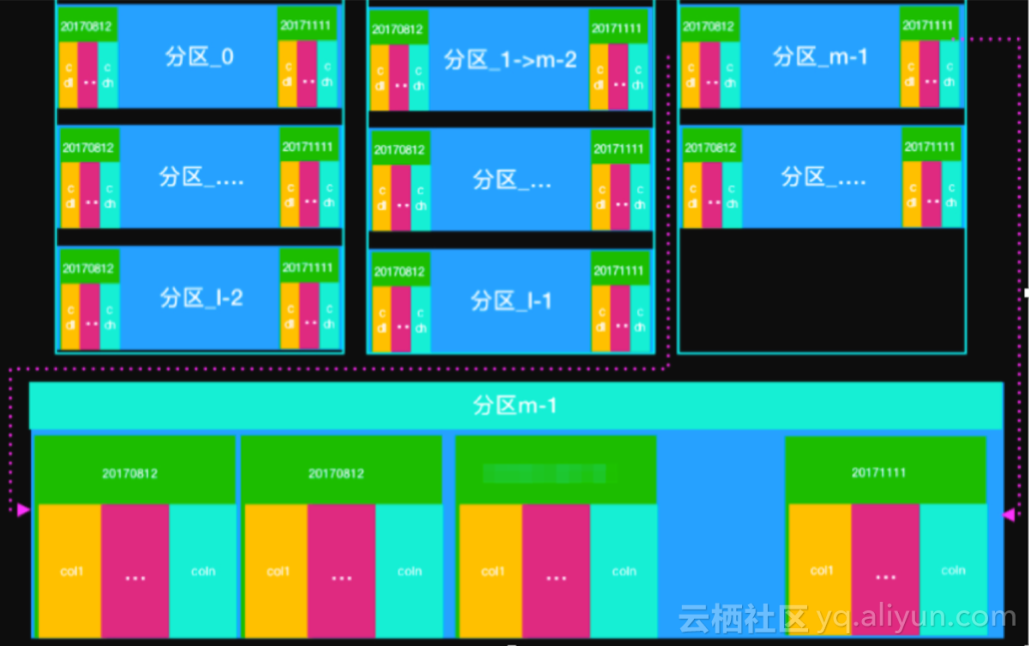
如上图,表一共m 个一级分区,每个一级分区都会按时间存储二级分区,每个二级分区都会存储所有的 列。 对分区进行设计的注意事项:
- 分区限制数量上限。
- 避免每个分区中只有少量数据。
- 按照分区条件查询和计算。
- 避免每个分区中多次数据写入。
表和分区设计基本规则
所有的表、字段名要使用统一的命名规范。
- 要能够区分该表的业务类型。
- 要能够区分该表是“事实表”或“维度表”,“日志表”,“极限存储表”(待发布功能)。
- 要能够区分该表的实体信息。
不同表中具有相同业务含义的字段要定义统一的数据类型:
- 避免不必要的类型转换。
分区设计及使用一般规则:
- 支持新增分区,不支持新增分区字段。
- 单表支持分区数量为6万。
- 对于多级分区的表,如果想添加新的分区,必须指明全部的分区值。
- 不支持修改分区列列名,只能修改分区列对应的值。修改多级分区的一个或者多个分区值,多级 分区的每一级的分区值都必须写上。
分区设计
分区字段和普通字段的选择
分区字段的作用:
- 方便数据的管理 。
- 划分数据扫描范围。
创建表的时候,可以设置普通字段和分区字段。在绝大多数情况下,可以把普通字段理解成数据文件的数 据,而分区字段可以理解成文件系统的目录。表的存储空间的占用是普通字段的空间占用。 分区列虽然不直接存储数据,但是如同文件系统里的目录,方便数据管理,同时在计算时若指定具体的分 区,计算过程中只查询对应分区,从而减少计算输入量。 分区表的分区列的个数不能超过6级,也可以理解成底层存储数据的目录层数不能超过6层。对分区表设置 合适的生命周期,可以按照分区细粒度做到对部分数据进行周期管理。
注意:
- 可以从数据管理范围和常用的数据扫描范围考虑将对应字段设置成分区字段。
- 对于不具备规律或者类型数量大于10000且不经常作为查询条件的字段设置成普通字段。
分区字段定义依据
按优先级高低排序:
- 区列的选择应充分考虑时间因素,尽量避免对于存量分区进行更新。
- 如果有多个事实表(不包括维度表)进行join,查询条件where范围的列作为分区列。 选
- 择group by 或distinct 包含的列作为分区列。
- 选择值分布均匀的列,不要选择分区倾斜的列作为分区列。
- 常用SQL包含某列的等值或in查询条件,选择该列作为分区列。
例如:
Select ... from table where id=123 and ....;分区个数定义依据
- 时间分区:可按天进行分区或者按月进行分区,如按照小时进行分区,二级分区平均数量不应大于8 个。
- 地域分区:省,市,县进行分区,考虑进行多级分区。23个省,5个自治区,4个直辖市,2个特别行 政区;50个地区(州、盟);661个市,其中:直辖市4个;地级市283个;县级市374个;1636个县(自治县、旗、自治旗、特区和林区),按照最细粒度县级进行分区后更细粒度不应再按照小时进行 分区。
- 单分区下的数据建议64M数据提交一次。如果为多级分区,保证每个最细粒度级分区下的二级分区的 数据都是按照这个规则。
- 单表分区数(包括下级分区)不能超过6万。
分区数量和数据量建议
在计算的时候可以使用分区裁剪是分区的优势。
- 建议单个分区中数据量不要太大,如可以单个分区中数据在1万条,但是建了5万个分区。
- 应尽量避免分区数据倾斜,单个表不同分区的数据量差异查过100万以上。
- 做分区设计时应合理规划分区个数,较细粒度的分区在跨分区扫描时会影响到SQL的执行性能。
- 单个分区中数据量较大的情况下,MaxCompute执行任务时会做分片处理不影响分区裁剪的优势。
- 单个分区中文件数较多时,会影响MaxComputeInstance数量,造成资源浪费和SQL性能的影响。
- 采用多级分区,先按日期分区,然后按交易类型分区。
- 拆表,一种交易类型就独立成一张表,再每张表按日期分区。
- 维度表不做分区。
MaxCompute 表(Table)设计规范的更多相关文章
- MaxCompute表设计最佳实践
MaxCompute表设计最佳实践 产生大量小文件的操作 MaxCompute表的小文件会影响存储和计算性能,因此我们先介绍下什么样的操作会产生大量小文件,从 而在做表设计的时候考虑避开此类操作. 使 ...
- PAI-STUDIO通过Tensorflow处理MaxCompute表数据
PAI-STUDIO在支持OSS数据源的基础上,增加了对MaxCompute表的数据支持.用户可以直接使用PAI-STUDIO的Tensorflow组件读写MaxCompute数据,本教程将提供完整数 ...
- winform datagridview在添加全选checkbox时提示:不能设置 selected 或 selected 既不是表 Table 的 DataColumn 也不是 DataRelation。
在项目中,需要多选功能,于是在datagridview添加了一列DataGridViewCheckBoxColumn 在给datagridview绑定完数据集之后,对全选进行操作的时候,发现总报错,报 ...
- 获取呈现在格表(table)记录的主键
用mouse点击表格(table)的行或是批定列,获取记录的主键值.在ASP.NET的MVC应用程序中,已经没有办法象ASP.NET的Data控件一样,如GridView,DataList和Repea ...
- OVS流表table之间的跳转
OVS流表table之间的跳转 前言 今天在帮学弟解决问题的时候,遇到一个table0.table1之间的微妙小插曲,引起了注意,后来查了一下资料发现原因了. 问题描述 wpq@wpq:~$ sudo ...
- Cocos2d-x 脚本语言Lua基本数据结构-表(table)
Cocos2d-x 脚本语言Lua基本数据结构-表(table) table是Lua中唯一的数据结构.其它语言所提供的数据结构,如:arrays.records.lists.queues.sets等. ...
- Hive中的数据库(Database)和表(Table)
在前面的文章中,介绍了可以把Hive当成一个"数据库",它也具备传统数据库的数据单元,数据库(Database/Schema)和表(Table). 本文介绍一下Hive中的数据库( ...
- openresty开发系列15--lua基础语法4表table和运算符
openresty开发系列15--lua基础语法4表table和运算符 lua中的表table 一)table (表)Table 类型实现了一种抽象的"关联数组".即可用作数组,也 ...
- 比较两个数据库表table结构不同之处
/*--比较两个数据库的表字段差异 hy 适用多种版本库 --*/ /*--调用示例 exec p_comparestructure 'database1','database2' --*/ ) dr ...
随机推荐
- 2019南昌邀请赛预选赛 I. Max answer (前缀和+单调栈)
题目:https://nanti.jisuanke.com/t/38228 这题题解参考网上大佬的. 程序的L[i],R[i]代表a[i]这个点的值在区间 [L[i],R[i]] 中最小的并且能拓展到 ...
- 【Luogu】【关卡2-8】广度优先搜索(2017年10月)
任务说明:广度优先搜索可以用来找有关“最短步数”的问题.恩,也可以用来“地毯式搜索”.
- leetcood学习笔记-35-二分法
题目: 第一次提交; class Solution: def searchInsert(self, nums: List[int], target: int) -> int: for i in ...
- A*寻路算法C++简单实现
搜索区域 如图所示简易地图, 其中绿色方块的是起点 (用 A 表示), 中间蓝色的是障碍物, 红色的方块 (用 B 表示) 是目的地. 为了可以用一个二维数组来表示地图, 我们将地图划分成一个个 ...
- 汇编检测OD代码
repnz指令说明:重复执行其后面的指令,CX或ECX存放最多比较次数,DI或EDI存放查找表首地址,AL或AX或EAX存放想查找的内容.当(CX或ECX)= 0 或 ZF=1 退出重复,否则,(CX ...
- 【spring】1.2、Spring Boot创建项目
Spring Boot创建项目 在1.1中,我们通过"Spring Starter Project"来创建了一个项目,实际上是使用了Pivotal团队提供的全新框架Spring B ...
- php的socket编程(socket关键几个函数)
php的socket编程(socket关键几个函数) 一.总结 一句话总结: socket_create.socket_connect.socket_bind.socket_listen.socket ...
- Django--实现分页功能,并且基于cookie实现用户定制每页的数据条数
# page_num 当前页数, total_result_num 总共有多少条测试结果 def pagination(request, page_num, total_result_num, res ...
- 二:unittest框架配合selenium之xpath定位
刚开始学习selenium自动化测试时,犯了一个不该犯的错误,偷懒,使用火狐浏览器中的扩展FIREBUG,FIREPATH来辅助定位. 虽然用的定位方法大多数是使用XPATH方法,但是是工具定位出来的 ...
- (1)sqlserver2017安装
本体 https://www.microsoft.com/zh-cn/sql-server/sql-server-downloads 图形管理工具ssm 文档 https://docs.microso ...