solr添加IK分词和自己定义词库
下载IK分词IK Analyzer 2012FF_hf1.zip
下载地址:http://yunpan.cn/cdvATy8899Lrw (提取码:c10d)
1、将IKAnalyzer2012FF_u1.jar包上传到服务器,复制到solr-4.10.4/example/solr-webapp/webapp/WEB-INF/lib目录下
2、在solr-4.10.4/example/solr-webapp/webapp/WEB-INF目录下创建目录classes,然后把IKAnalyzer.cfg.xml和stopword.dic拷贝到新创建的classes目录下即可
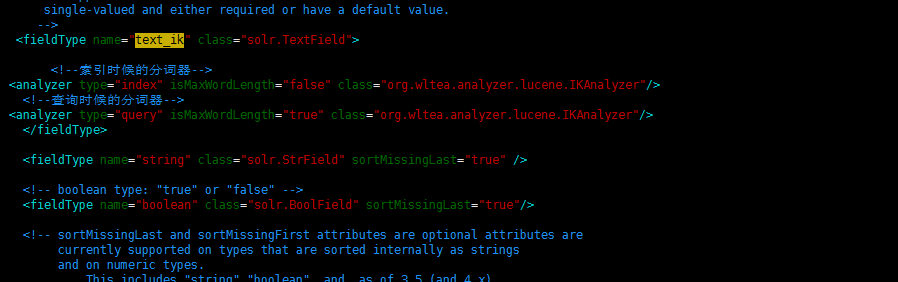
3:修改solr core的schema文件,默认是solr-4.10.4/example/solr/collection1/conf/schema.xml,添加如下配置
<fieldType name="text_ik" class="solr.TextField">
<!--索引时候的分词器-->
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<!--查询时候的分词器-->
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
4、启动solr集群

自定义词库
到sougou 下载对应的词库:http://pinyin.sogou.com/dict/
由于sougou 下载后的文件是scel 格式不能直接用,需要用工具转化下格式,推荐使用深蓝工具,下载地址
http://yunpan.cn/cmuyuQhCasFMR (提取码:6432)

然后将文件格式转化为dic结尾的。词库的文件格式必需是:无BOM的UTF-8格式,分词库可以为多个,以分号隔开即可。
将下载的词库复制到/home/hadoop/cloudsolr/solr-4.10.4/example/solr-webapp/webapp/WEB-INF/classes目录下

修改配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典
<entry key="ext_dict">ext.dic;</entry>
-->
<entry jey = "mingxing">mingxing.scel</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry> </properties>
重启solr集群
测试结果:
这样分词有一个问题:分词方式是按照maxword 的方式
集群启动的时候主节点不会报错。从节点会报错

配置文件信息如下:
IK的lib文件已经上传

改配置的都配置了,启动还是报错:
{msg=SolrCore 'collection1' is not available due to init failure: Could not load conf for core collection1: Plugin init failure for [schema.xml] fieldType "text_ik": Cannot load analyzer: org.wltea.analyzer.lucene.IKAnalyzer. Schema file is /configs/myconf/schema.xml,trace=org.apache.solr.common.SolrException: SolrCore 'collection1' is not available due to init failure: Could not load conf for core collection1: Plugin init failure for [schema.xml] fieldType "text_ik": Cannot load analyzer: org.wltea.analyzer.lucene.IKAnalyzer. Schema file is /configs/myconf/schema.xml
at org.apache.solr.core.CoreContainer.getCore(CoreContainer.java:745)
at org.apache.solr.servlet.SolrDispatchFilter.doFilter(SolrDispatchFilter.java:347)
问题原因:
配置了IK分词后,没有同步到zk,删掉zkdata 里面的数据重新启动zk即可
solr添加IK分词和自己定义词库的更多相关文章
- [Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例二.
为了更好的排版, 所以将IK分词器的安装重启了一篇博文, 大家可以接上solr的安装一同查看.[Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例一: http://ww ...
- Solr:Slor初识(概述、Windows版本的安装、添加IK分词器)
1.Solr概述 (1)Solr与数据库相比的优势 搜索速度更快.搜索结果能够按相关度排序.搜索内容格式不固定等 (2)Lucene与Solr的区别 Lucene提供了完整的查询引擎和索引引擎,目的是 ...
- python jieba分词(结巴分词)、提取词,加载词,修改词频,定义词库 -转载
转载请注明出处 “结巴”中文分词:做最好的 Python 中文分词组件,分词模块jieba,它是python比较好用的分词模块, 支持中文简体,繁体分词,还支持自定义词库. jieba的分词,提取关 ...
- [Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例一.
在这里一下讲解着三个的安装和配置, 是因为solr需要使用tomcat和IK分词器, 这里会通过图文教程的形式来详解它们的安装和使用.注: 本文属于原创文章, 如若转载,请注明出处, 谢谢.关于设置I ...
- Solr和IK分词器的整合
IK分词器相对于mmseg4J来说词典内容更加丰富,但是没有mmseg4J灵活,后者可以自定义自己的词语库.IK分词器的配置过程和mmseg4J一样简单,其过程如下: 1.引入IKAnalyzer.j ...
- Solr——配置IK分词器
首先需要的准备好jdk1.8和tomcat8以及ik分词器(ik分词器是5.x的版本,和solr4.10搭配的版本不一样,虽然是5.x的版本但是也是能使用在solr7.2版本上的) 分享链接https ...
- SCWS中文分词,向xdb词库添加新词
SCWS是个不错的中文分词解决方案,词库也是hightman个人制作,总不免有些不尽如人意的地方.有些词语可能不会及时被收入词库中. 幸好SCWS提供了词库XDB导出导入词库的工具(phptool_f ...
- [Linux] linux下安装配置 zookeeper/redis/solr/tomcat/IK分词器 详细实例.
今天 不知自己装的centos 出现了什么问题, 一直卡在 启动界面, 找了半天没找见原因(最后时刻还是发现原因, 只因自己手欠一怒之下将centos删除了, 而且选择的是在本地磁盘也删除. ..让我 ...
- Solr添加paoding分词器
1.Solr3.6.2 并可运行 paoding-analysis3.0.jar 下载 2.1 解压{$Solr-Path}/example/webapp 下的solr.war文件,解压到当前文件夹 ...
随机推荐
- 使用gulp管理sass文件
前提是npm和ruby已经安装好 1. 新建文件夹myproject,cd进入文件夹 再npm init 初始化 2.npm install gulp --save-dev 为项目添加gulp,并将g ...
- (转)MySQL安装及配置指南
转:http://wiki.ubuntu.org.cn/MySQL%E5%AE%89%E8%A3%85%E6%8C%87%E5%8D%97 安装MySQL sudo apt-get install m ...
- eclipse修改项目访问前缀
eclipse项目右击 properties---web project setting---context root修改项目访问前缀
- python re.findall 使用
python re.findall 使用 import re #\w 匹配字母数字及下划线 print(re.findall('\w','hello alan _god !@^&#^$^!*& ...
- 拾遗:systemctl --user
参考:https://wiki.gentoo.org/wiki/Systemd systemd 支持普通用户定义的 unit[s] 开机启动 systemctl --user enable/disab ...
- 前端(五)—— a、img、list标签
a标签.img标签.list标签 一.a标签 1.常用用法 <a href="https://www.baidu.com">前往百度</a> <a h ...
- jQuery片段 - 表单action的更改和提交
//点击表单“提交”按钮 $("#submitBut").bind("click", function() { var url = "..." ...
- layui中下拉框问题
<div class="layui-form-item"> <label class="layui-form-label">上级栏目:& ...
- 使用PHP如何去除字符串结尾的字符
前言 在工作中遇到一个需求:一串字符串,如"迅雷官方下载"."快播5.0下载",需要去掉他们结尾的"官方下载"和"下载" ...
- 网址URL知识
URL由三部分组成:资源类型.存放资源的主机域名.资源文件名. URL的一般语法格式为: (带方括号[]的为可选项): protocol :// hostname[:port] / path / [; ...