requests库爬取豆瓣热门国产电视剧数据并保存到本地
首先要做的就是去豆瓣网找对应的接口,这里就不赘述了,谷歌浏览器抓包即可,然后要做的就是分析返回的json数据的结构:
这是接口地址,可以大概的分析一下各个参数的规则:
- type=tv,表示的是电视剧的分类
- tag=国产剧,表示是国产剧的分类
- sort参数,这里猜测是一个排序方式
- page_limit=20,这个一定就是每页所存取的数据数量了
- page_start=0,表示的是这页从哪条数据开始,比如第二页就为page_start=20,第三页为page_start=40,以此类推
- 最终我们要用到的主要是page_start和page_limit两个参数
下面这里是返回的json数据格式,可以看出我们要的是json中subjects列表中的每条数据,在之后的程序中会把每一个电视剧的信息保存到文件里的一行

有了这些,就直接上程序了,因为感觉程序还是比较好懂,主要还是遵从面向对象的程序设计:
import json
import requests class DoubanSpider(object):
"""爬取豆瓣热门国产电视剧的数据并保存到本地""" def __init__(self):
# url_temp中的start的值是动态的,所以这里用{}替换,方便后面使用format方法
self.url_temp = 'https://movie.douban.com/j/search_subjects?type=tv&tag=%E5%9B%BD%E4%BA%A7%E5%89%A7&sort=recommend&page_limit=20&page_start={}'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
} def pass_url(self, url): # 发送请求,获取响应
print(url)
response = requests.get(url, headers=self.headers)
return response.content.decode() def get_content_list(self, json_str): # 提取数据
dict_ret = json.loads(json_str)
content_list = dict_ret['subjects']
return content_list def save_content_list(self, content_list): # 保存
with open('douban.txt', 'a', encoding='utf-8') as f:
for content in content_list:
f.write(json.dumps(content, ensure_ascii=False)) # 一部电视剧的信息一行
f.write('\n') # 写入换行符进行换行
print('保存成功!') def run(self): # 实现主要逻辑
num = 0
while True:
# 1. start_url
url = self.url_temp.format(num)
# 2. 发送请求,获取响应
json_str = self.pass_url(url)
# 3. 提取数据
content_list = self.get_content_list(json_str)
# 4. 保存
self.save_content_list(content_list)
if len(content_list) < 20:
break
# 5. 构造下一页url地址,进入循环
num += 20 # 每一页有二十条数据 if __name__ == '__main__':
douban_spider = DoubanSpider()
douban_spider.run()
上面是利用循环遍历每一页,后来我又想到用递归也可以,虽然递归效率可能不高,这里还是展示一下,只需要改几个地方而已:
import json
import requests class DoubanSpider(object):
"""爬取豆瓣热门国产电视剧的数据并保存到本地"""
def __init__(self):
# url_temp中的start的值是动态的,所以这里用{}替换,方便后面使用format方法
self.url_temp = 'https://movie.douban.com/j/search_subjects?type=tv&tag=%E5%9B%BD%E4%BA%A7%E5%89%A7&sort=recommend&page_limit=20&page_start={}'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
}
self.num = 0 def pass_url(self, url): # 发送请求,获取响应
print(url)
response = requests.get(url, headers=self.headers)
return response.content.decode() def get_content_list(self, json_str): # 提取数据
dict_ret = json.loads(json_str)
content_list = dict_ret['subjects']
return content_list def save_content_list(self, content_list): # 保存
with open('douban2.txt', 'a', encoding='utf-8') as f:
for content in content_list:
f.write(json.dumps(content, ensure_ascii=False)) # 一部电视剧的信息一行
f.write('\n') # 写入换行符进行换行
print('保存成功!') def run(self): # 实现主要逻辑
# 1. start_url
url = self.url_temp.format(self.num)
# 2. 发送请求,获取响应
json_str = self.pass_url(url)
# 3. 提取数据
content_list = self.get_content_list(json_str)
# 4. 保存
self.save_content_list(content_list)
# 5. 构造下一页url地址,进入循环
if len(content_list) == 20:
self.num += 20 # 每一页有二十条数据
self.run() if __name__ == '__main__':
douban_spider = DoubanSpider()
douban_spider.run()
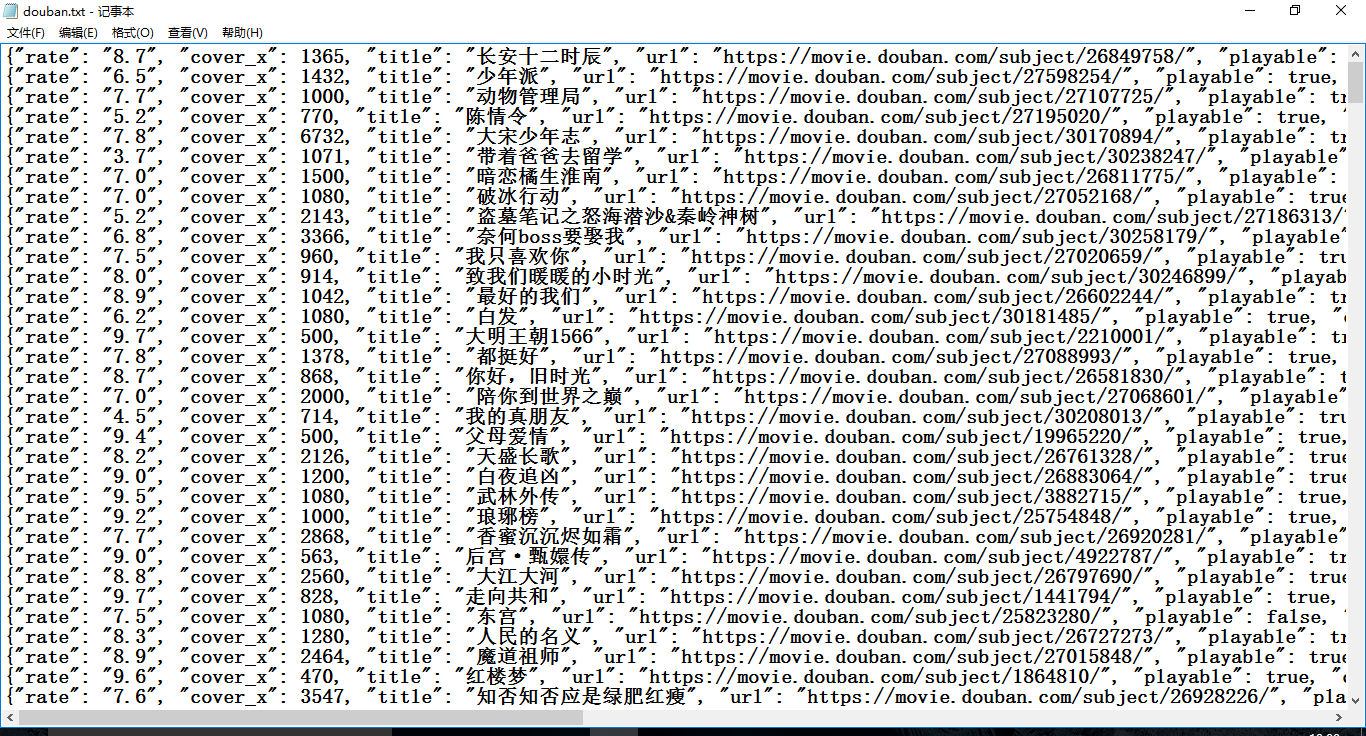
最终文件得到的结果:
requests库爬取豆瓣热门国产电视剧数据并保存到本地的更多相关文章
- python--爬取豆瓣热门国产电视剧保存为文件
# -*- coding: utf-8 -*- __author__ = 'Frank Li' import requests import json class HotSpider(object): ...
- requests+正则爬取豆瓣图书
#requests+正则爬取豆瓣图书 import requests import re def get_html(url): headers = {'User-Agent':'Mozilla/5.0 ...
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
- scrapy爬取校花网男神图片保存到本地
爬虫四部曲,本人按自己的步骤来写,可能有很多漏洞,望各位大神指点指点 1.创建项目 scrapy startproject xiaohuawang scrapy.cfg: 项目的配置文件xiaohua ...
- 用requests库爬取猫眼电影Top100
这里需要注意一下,在爬取猫眼电影Top100时,网站设置了反爬虫机制,因此需要在requests库的get方法中添加headers,伪装成浏览器进行爬取 import requests from re ...
- 【Python成长之路】Python爬虫 --requests库爬取网站乱码(\xe4\xb8\xb0\xe5\xa)的解决方法【华为云分享】
[写在前面] 在用requests库对自己的CSDN个人博客(https://blog.csdn.net/yuzipeng)进行爬取时,发现乱码报错(\xe4\xb8\xb0\xe5\xaf\x8c\ ...
- requests库爬取猫眼电影“最受期待榜”榜单 --网络爬虫
目标站点:https://maoyan.com/board/6 # coding:utf8 import requests, re, json from requests.exceptions imp ...
- requests库/爬取zhihu表情包
先学了requests库的一些基本操作,简单的爬了一下. 用到了requests.get()方法,就是以GET方式请求网页,得到一个Response对象.不加headers的话可能会400error所 ...
- python requests库爬取网页小实例:ip地址查询
ip地址查询的全代码: 智力使用ip183网站进行ip地址归属地的查询,我们在查询的过程是通过构造url进行查询的,将要查询的ip地址以参数的形式添加在ip183url后面即可. #ip地址查询的全代 ...
随机推荐
- sh_17_字符串的查找和替换
sh_17_字符串的查找和替换 hello_str = "hello world" # 1. 判断是否以指定字符串开始 print(hello_str.startswith(&qu ...
- jQuery文档操作之插入操作
append() 语法 父元素.append(子元素) 解释:追加某元素,在父元素中添加新的子元素.子元素可以为:string/element(js对象)/jQuery元素 代码如下: var oli ...
- 免费馅饼~-~ (hdu 1176
当我准备要写这个随笔的时候是需要勇气的. 掉馅饼嘛,肯定是坑. (hdu1176 话说,gameboy人品太好,放学回家路上有馅饼可捡.还就在0~10这11个位置里,当馅饼开始掉的时候,gameboy ...
- [Note][深入理解Java虚拟机] 第三章 垃圾收集器与内存分配策略笔记
书上关于GCTimeRatio的讲解有点难以理解,查看Oracle的文档后重新理解了下 -XX:GCTimeRatio 运行时间 / GC时间 当GCTimeRatio为19时,运行时间是GC时间的1 ...
- MySQL_(Java)使用preparestatement解决SQL注入的问题
MySQL_(Java)使用JDBC向数据库发起查询请求 传送门 MySQL_(Java)使用JDBC创建用户名和密码校验查询方法 传送门 MySQL数据库中的数据,数据库名garysql,表名gar ...
- Centos安装成功后配置网络
一.设置IP地址.网关DNS 说明:CentOS 7.0默认安装好之后是没有自动开启网络连接的! cd /etc/sysconfig/network-scripts/ #进入网络配置文件目录 vi i ...
- 「Luogu P5603」小O与桌游
题目链接 戳我 \(Solution\) 我们来分析题目. 实际上就是求一个拓扑序满足拓扑序的前缀最大值最多/最少 对于第一种情况,很明显一直选当前能选的最小的是最优的对吧.因为你需要大的尽可能多.用 ...
- PHP7 的部分新特性
1. 运算符(NULL 合并运算符) $a = $_GET['a'] ?? 1; 它相当于: <php$a = isset($_GET['a']) ? $_GET['a'] : 1; 我们知道三 ...
- hive 源码笔记(1):命令行执行的主流程。
1. 'hive'命令是(默认为hive跟目录)./bin下的一个shell脚本,依次加载 ./bin/hive-config.sh, ./conf/hive-env.sh, 设置与hadoop.sp ...
- Orcal设置默认插入数据的日期和时间
CREATE TABLE TEST_DATE_TIME( id integer, operdate )default "TO_CHAR"(SYSDATE,'yyyy-MM-dd') ...