Python爬取mc皮肤【爬虫项目】
PS:另外很多人在学习Python的过程中,往往因为遇问题解决不了或者没好的教程从而导致自己放弃,为此我整理啦从基础的python脚本到web开发、爬虫、django、数据挖掘等【PDF等】需要的可以进Python全栈开发交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,不懂的问题有老司机解决哦,一起相互监督共同进步
import requests
import re
import time
import json
download_sucess = True
time.sleep(1.5)
pictures = input('你想下载多少张皮肤:')
while pictures.isdigit() == False:
print("请输入数字!")
pictures = input('你想下载多少张皮肤:')
Path = input('请输入保存的路径:')
print("请稍等......")
pictures = int(pictures)
for i in range(1,pictures+1):
url = 'https://littleskin.cn/skinlib/data?filter=skin&uploader=0&sort=likes&keyword=&page=' + str(i)
response = requests.get(url).json()
ids = re.findall("'tid': (.*?),",str(response))
for id in ids:
picture_url = 'https://littleskin.cn/preview/' + id + '.png'
picture_name = picture_url.strip('https://littleskin.cn/preview/')
picture = requests.get(picture_url).content
try:
with open(Path + '//%s'%picture_name,'wb') as file:
file.write(picture)
except FileNotFoundError:
download_sucess = False
print('路径不存在!')
break
if download_sucess == False:
print("下载失败!")
elif download_sucess == True:
print('下载完成!')最终效果:
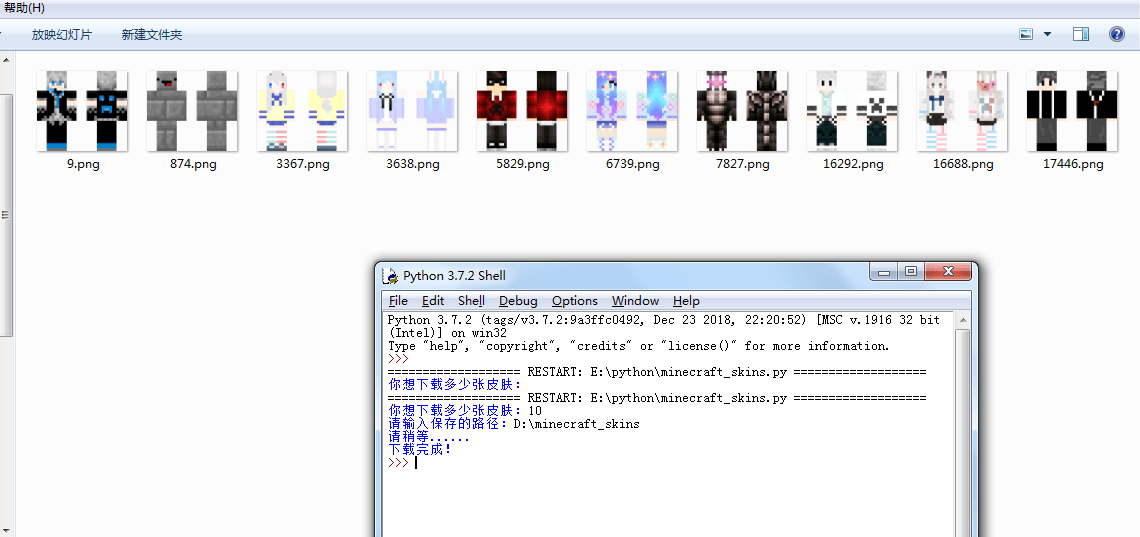
皮肤爬取的原理是通过 json 格式来查看网站的每一张图片的 id 号,再用拼接的方式组成一个图片地址,最后再用二进制的方式把图片存放在我们的文件夹里。希望各位能通过这篇文章学到东西。
总结:很多人在学习Python的过程中,往往因为遇问题解决不了或者没好的教程从而导致自己放弃,为此我整理啦从基础的python脚本到web开发、爬虫、django、数据挖掘等【PDF等】需要的可以进Python全栈开发交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,不懂的问题有老司机解决哦,一起相互监督共同进步
本文的文字及图片来源于网络加上自己的想法,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
Python爬取mc皮肤【爬虫项目】的更多相关文章
- 利用python爬取海量疾病名称百度搜索词条目数的爬虫实现
实验原因: 目前有一个医疗百科检索项目,该项目中对关键词进行检索后,返回的结果很多,可惜结果的排序很不好,影响用户体验.简单来说,搜索出来的所有符合疾病中,有可能是最不常见的疾病是排在第一个的,而最有 ...
- Python爬取LOL英雄皮肤
Python爬取LOL英雄皮肤 Python 爬虫 一 实现分析 在官网上找到英雄皮肤的真实链接,查看多个后发现前缀相同,后面对应为英雄的ID和皮肤的ID,皮肤的ID从00开始顺序递增,而英雄ID跟 ...
- 爬虫实战(二) 用Python爬取网易云歌单
最近,博主喜欢上了听歌,但是又苦于找不到好音乐,于是就打算到网易云的歌单中逛逛 本着 "用技术改变生活" 的想法,于是便想着写一个爬虫爬取网易云的歌单,并按播放量自动进行排序 这篇 ...
- Python爬取 | 王者荣耀英雄皮肤海报
这里只展示代码,具体介绍请点击下方链接. Python爬取 | 王者荣耀英雄皮肤海报 import requests import re import os import time import wi ...
- 【Python爬虫案例】用Python爬取李子柒B站视频数据
一.视频数据结果 今天是2021.12.7号,前几天用python爬取了李子柒的油管评论并做了数据分析,可移步至: https://www.cnblogs.com/mashukui/p/1622025 ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- 萌新学习Python爬取B站弹幕+R语言分词demo说明
代码地址如下:http://www.demodashi.com/demo/11578.html 一.写在前面 之前在简书首页看到了Python爬虫的介绍,于是就想着爬取B站弹幕并绘制词云,因此有了这样 ...
- Python爬取招聘信息,并且存储到MySQL数据库中
前面一篇文章主要讲述,如何通过Python爬取招聘信息,且爬取的日期为前一天的,同时将爬取的内容保存到数据库中:这篇文章主要讲述如何将python文件压缩成exe可执行文件,供后面的操作. 这系列文章 ...
- Python爬取豆瓣《复仇者联盟3》评论并生成乖萌的格鲁特
代码地址如下:http://www.demodashi.com/demo/13257.html 1. 需求说明 本项目基于Python爬虫,爬取豆瓣电影上关于复仇者联盟3的所有影评,并保存至本地文件. ...
随机推荐
- PHP Magic Method Setter and Getter
<?php /* Magic method __set() and __get() 1.The definition of a magic function is provided by the ...
- web攻击与防御
攻击方式 利用输出值转义漏洞 跨站脚本攻击(XSS) SQL注入攻击 OS命令注入攻击 HTTP首部注入攻击 邮件首部注入攻击 文件目录遍历攻击 利用设置或设计缺陷 强制游览 开放重定向 不正确的错误 ...
- 【Pyecharts可视化分享】杭州步行热门路线等~
前言 本文包括内容如下: 杭州步行热门路线 渐变效果散点图 均是Echarts官方提供等示例,本文将会通过Pyecharts来进行实现. 杭州步行热门路线 因为代码中需要调用百度地图,所以开始之前你需 ...
- PAT (Basic Level) Practice (中文)1023 组个最小数 (20 分) (排序)
给定数字 0-9 各若干个.你可以以任意顺序排列这些数字,但必须全部使用.目标是使得最后得到的数尽可能小(注意 0 不能做首位).例如:给定两个 0,两个 1,三个 5,一个 8,我们得到的最小的数就 ...
- 【LInux01】学习Linux课程体系
知识 =>技能 需要大量的练习 相当于复盘 要有成就感 在一个领域深挖,再迁移到其他领域 1.两周以后的知识留存率: 主动学习: 动手实践:40% 讲给别人听:70% 写博客:是写教程,便 ...
- 在ASP.NET 中调用 WebService 服务
一.webservice定义 详见 https://www.cnblogs.com/phoebes/p/8029464.html 二.在ASP.NET MVC 中调用 webservice 1:要调用 ...
- 学习Python常用的工具
Python编程语言 Python是一门高级计算机程序设计语言! Python是一种解释型(脚本)语言,因为其代码简明,书写效率高,功能强大.易扩展.有丰富的专业库而受大众欢迎! 最常用的专业库有: ...
- jacob导入项目
在 resource 下创建一个 lib 将网上下载的 jacob.jar 放入其中 在 pom 文件中导入相对应的 jar 包 <dependency> <groupId>c ...
- Spring框架详解介绍-基本使用方法
1.Spring框架-控制反转(IOC) 2.Spring框架-面向切面编程(AOP) 3.Spring 内置的JdbcTemplate(Spring-JDBC) Spring框架-控制反转(IOC) ...
- liunx下安装Docker
1.安装并启动docker 1.检查内核版本,必须是3.10及以上uname -r2.安装docker yum install docker命令安装(需要联网) [root@localhost ~]# ...