python XML实例
案例:使用XPath的爬虫
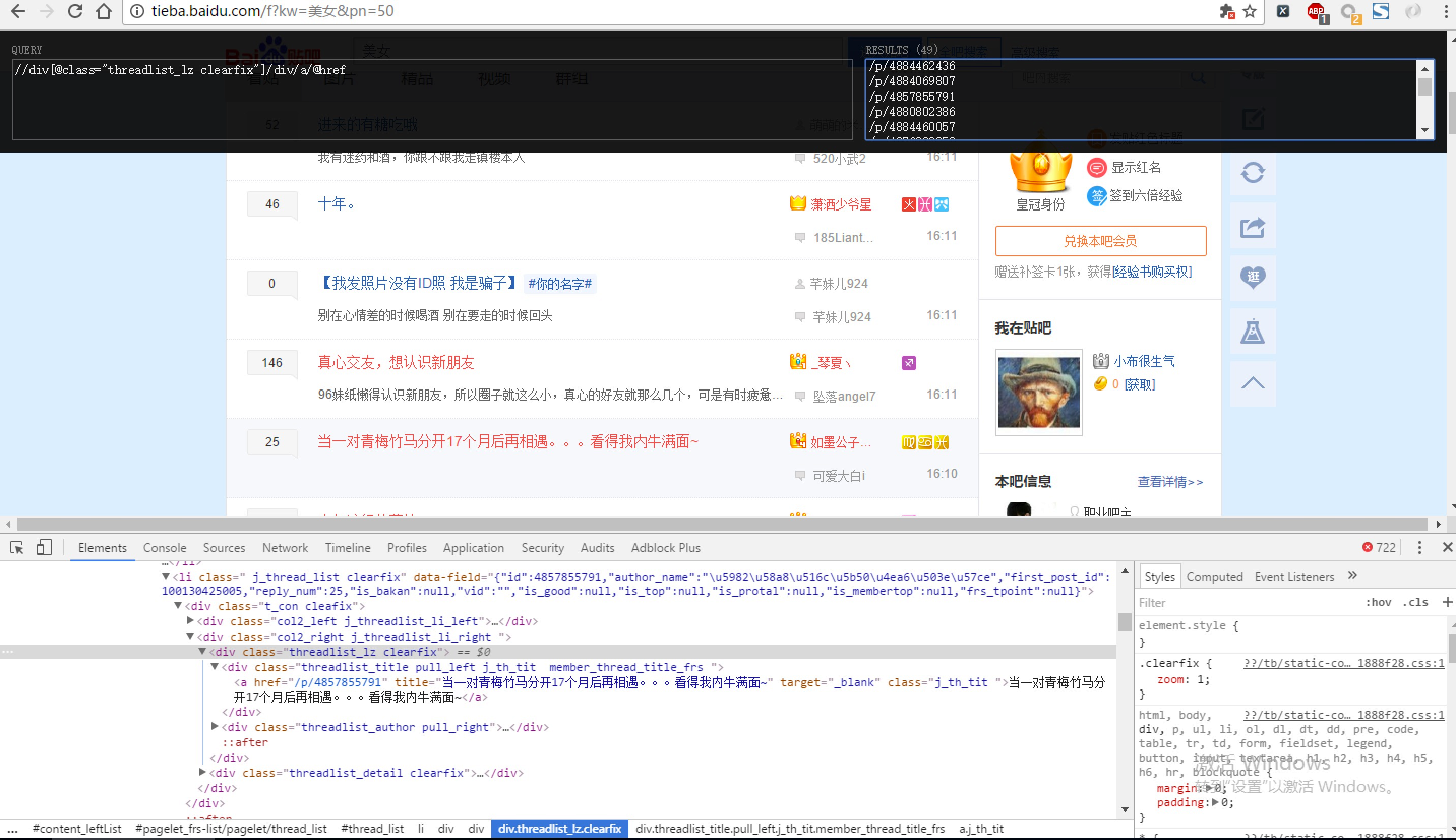
现在我们用XPath来做一个简单的爬虫,我们尝试爬取某个贴吧里的所有帖子,并且将该这个帖子里每个楼层发布的图片下载到本地。
# tieba_xpath.py #!/usr/bin/env python
# -*- coding:utf-8 -*- import os
import urllib
import urllib2
from lxml import etree class Spider:
def __init__(self):
self.tiebaName = raw_input("请需要访问的贴吧:")
self.beginPage = int(raw_input("请输入起始页:"))
self.endPage = int(raw_input("请输入终止页:")) self.url = 'http://tieba.baidu.com/f'
self.ua_header = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1 Trident/5.0;"} # 图片编号
self.userName = 1 def tiebaSpider(self):
for page in range(self.beginPage, self.endPage + 1):
pn = (page - 1) * 50 # page number
word = {'pn' : pn, 'kw': self.tiebaName} word = urllib.urlencode(word) #转换成url编码格式(字符串)
myUrl = self.url + "?" + word # 示例:http://tieba.baidu.com/f? kw=%E7%BE%8E%E5%A5%B3 & pn=50
# 调用 页面处理函数 load_Page
# 并且获取页面所有帖子链接,
links = self.loadPage(myUrl) # urllib2_test3.py # 读取页面内容
def loadPage(self, url):
req = urllib2.Request(url, headers = self.ua_header)
html = urllib2.urlopen(req).read() # 解析html 为 HTML 文档
selector=etree.HTML(html) #抓取当前页面的所有帖子的url的后半部分,也就是帖子编号
# http://tieba.baidu.com/p/4884069807里的 “p/4884069807”
links = selector.xpath('//div[@class="threadlist_lz clearfix"]/div/a/@href') # links 类型为 etreeElementString 列表
# 遍历列表,并且合并成一个帖子地址,调用 图片处理函数 loadImage
for link in links:
link = "http://tieba.baidu.com" + link
self.loadImages(link) # 获取图片
def loadImages(self, link):
req = urllib2.Request(link, headers = self.ua_header)
html = urllib2.urlopen(req).read() selector = etree.HTML(html) # 获取这个帖子里所有图片的src路径
imagesLinks = selector.xpath('//img[@class="BDE_Image"]/@src') # 依次取出图片路径,下载保存
for imagesLink in imagesLinks:
self.writeImages(imagesLink) # 保存页面内容
def writeImages(self, imagesLink):
'''
将 images 里的二进制内容存入到 userNname 文件中
''' print imagesLink
print "正在存储文件 %d ..." % self.userName
# 1. 打开文件,返回一个文件对象
file = open('./images/' + str(self.userName) + '.png', 'wb') # 2. 获取图片里的内容
images = urllib2.urlopen(imagesLink).read() # 3. 调用文件对象write() 方法,将page_html的内容写入到文件里
file.write(images) # 4. 最后关闭文件
file.close() # 计数器自增1
self.userName += 1 # 模拟 main 函数
if __name__ == "__main__": # 首先创建爬虫对象
mySpider = Spider()
# 调用爬虫对象的方法,开始工作
mySpider.tiebaSpider()
python XML实例的更多相关文章
- Python导出Excel为Lua/Json/Xml实例教程(三):终极需求
相关链接: Python导出Excel为Lua/Json/Xml实例教程(一):初识Python Python导出Excel为Lua/Json/Xml实例教程(二):xlrd初体验 Python导出E ...
- Python导出Excel为Lua/Json/Xml实例教程(二):xlrd初体验
Python导出Excel为Lua/Json/Xml实例教程(二):xlrd初体验 相关链接: Python导出Excel为Lua/Json/Xml实例教程(一):初识Python Python导出E ...
- Python导出Excel为Lua/Json/Xml实例教程(一):初识Python
Python导出Excel为Lua/Json/Xml实例教程(一):初识Python 相关链接: Python导出Excel为Lua/Json/Xml实例教程(一):初识Python Python导出 ...
- python 解析XML python模块xml.dom解析xml实例代码
分享下python中使用模块xml.dom解析xml文件的实例代码,学习下python解析xml文件的方法. 原文转自:http://www.jbxue.com/article/16587.html ...
- Python 解析XML实例(xml.sax)
已知movies.xml <collection shelf="New Arrivals"> <movie title="Enemy Behind&qu ...
- Python XML解析(转载)
Python XML解析 什么是XML? XML 指可扩展标记语言(eXtensible Markup Language). 你可以通过本站学习XML教程 XML 被设计用来传输和存储数据. XML是 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python xml 模块
Python xml 模块 TOC 什么是xml? xml和json的区别 xml现今的应用 xml的解析方式 xml.etree.ElementTree SAX(xml.parsers.expat) ...
- python大法好——Python XML解析
Python XML解析 什么是XML? XML 被设计用来传输和存储数据. XML是一套定义语义标记的规则,这些标记将文档分成许多部件并对这些部件加以标识. 它也是元标记语言,即定义了用于定义其他与 ...
随机推荐
- 【tomcat】FileNotFoundException: C:\Program Files\Java\apache-tomcat-8.5.11-geneshop3\webapps\ROOT\index.html (拒绝访问。)
新装系统后,tomcat启动起来 提示如下错误: Caused by: java.io.FileNotFoundException: C:\Program Files\Java\apache-tomc ...
- CSS3:3D转换
几个突破口:(为了更简洁理解,先忽略兼容) 1.认识3D的坐标系 rotateX()-----------元素绕X轴旋转 rotateY() -----------元素绕Y轴旋转 rotateZ() ...
- [Python爬虫] 之二十五:Selenium +phantomjs 利用 pyquery抓取今日头条网数据
一.介绍 本例子用Selenium +phantomjs爬取今日头条(http://www.toutiao.com/search/?keyword=电视)的资讯信息,输入给定关键字抓取资讯信息. 给定 ...
- vagrant 知识库
版权声明:转载时请以超链接形式标明文章原始出处和作者信息及本声明 http://wushaobo.info/?p=83 Vagrant让虚拟化技术走近寻常家.脚踏实地地说,网络上类似“两分钟入门”的文 ...
- ubuntu14.04 server 安装docker
安装docker服务 $ curl -sSL https://get.docker.com/ | sh $ ocker run hello-world 测试docker是否安装成功 ubuntu ...
- 60分钟搞定JAVA加解密
从摩尔电码到小伙伴之间老师来了的暗号,加密信息无处不在.从军事到生活,加密信息的必要性也不言而喻. 今天,我们就来看看java怎么对数据进行加解密 分类 a.古典密码 -- 受限制算法:算法的保密性给 ...
- 为Linux上FireFox安装Flash插件
废话少说,步骤如下: 1.点击网页上插件缺失处,根据提示下载tar.gz版本的插件,我下载的版本是install_flash_player_11_linux.i386.tar.gz,这个文件被下载到了 ...
- JSON 对象
JSON 对象 对象语法 { "name":"runoob", "alexa":10000, "site":null } ...
- 配置 mybatis的 log4j.properties
log4j.rootLogger=debug,stdout,logfile ### 把日志信息输出到控制台 ### log4j.appender.stdout=org.apache.log4j.Con ...
- flask-Migrate模块
功能 flask-migrate是flask的一个扩展模块,主要是扩展数据库表结构的. 官方文档:http://flask-migrate.readthedocs.io/en/latest/ 安装 p ...