python XML实例
案例:使用XPath的爬虫
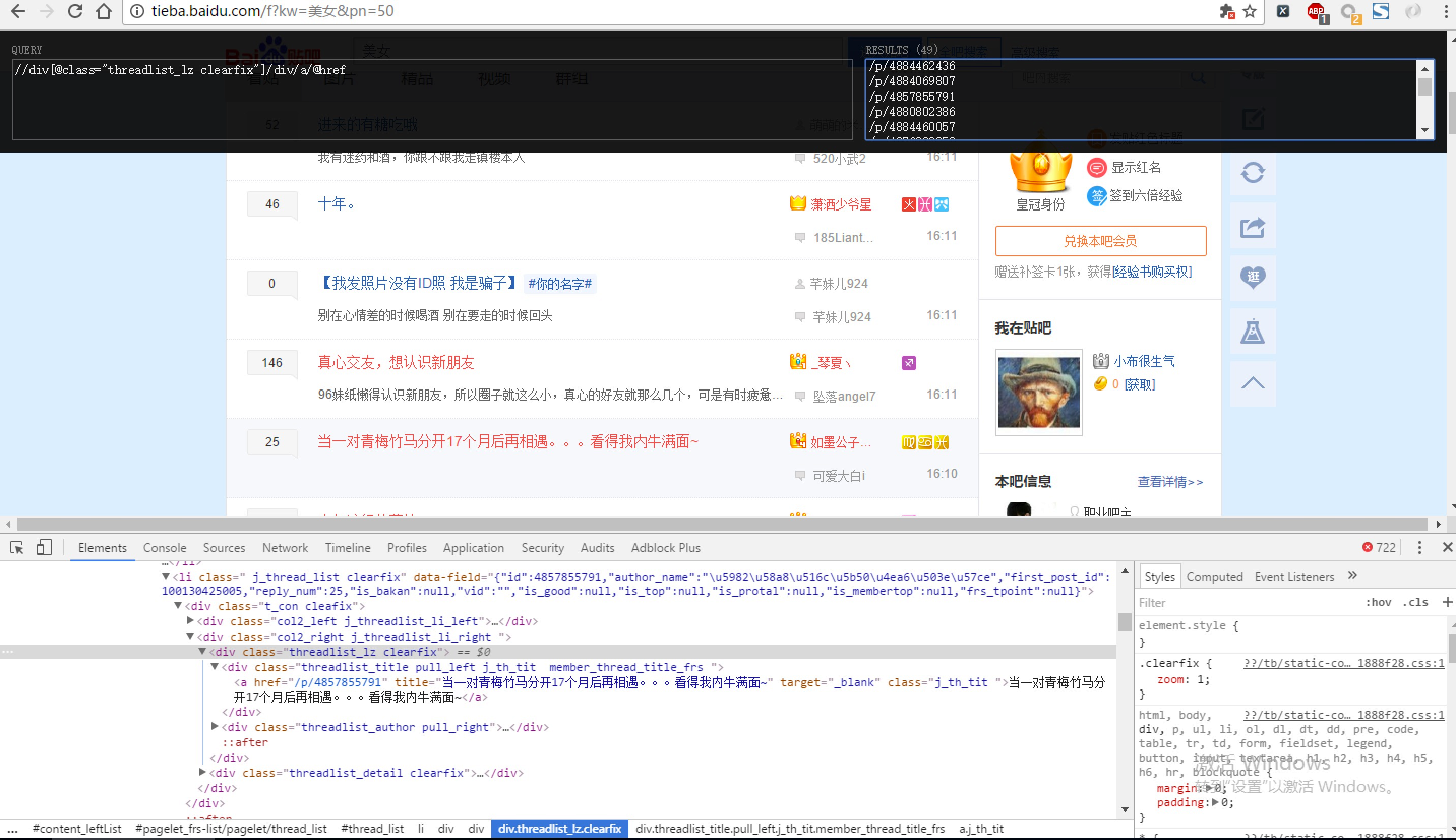
现在我们用XPath来做一个简单的爬虫,我们尝试爬取某个贴吧里的所有帖子,并且将该这个帖子里每个楼层发布的图片下载到本地。
# tieba_xpath.py #!/usr/bin/env python
# -*- coding:utf-8 -*- import os
import urllib
import urllib2
from lxml import etree class Spider:
def __init__(self):
self.tiebaName = raw_input("请需要访问的贴吧:")
self.beginPage = int(raw_input("请输入起始页:"))
self.endPage = int(raw_input("请输入终止页:")) self.url = 'http://tieba.baidu.com/f'
self.ua_header = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1 Trident/5.0;"} # 图片编号
self.userName = 1 def tiebaSpider(self):
for page in range(self.beginPage, self.endPage + 1):
pn = (page - 1) * 50 # page number
word = {'pn' : pn, 'kw': self.tiebaName} word = urllib.urlencode(word) #转换成url编码格式(字符串)
myUrl = self.url + "?" + word # 示例:http://tieba.baidu.com/f? kw=%E7%BE%8E%E5%A5%B3 & pn=50
# 调用 页面处理函数 load_Page
# 并且获取页面所有帖子链接,
links = self.loadPage(myUrl) # urllib2_test3.py # 读取页面内容
def loadPage(self, url):
req = urllib2.Request(url, headers = self.ua_header)
html = urllib2.urlopen(req).read() # 解析html 为 HTML 文档
selector=etree.HTML(html) #抓取当前页面的所有帖子的url的后半部分,也就是帖子编号
# http://tieba.baidu.com/p/4884069807里的 “p/4884069807”
links = selector.xpath('//div[@class="threadlist_lz clearfix"]/div/a/@href') # links 类型为 etreeElementString 列表
# 遍历列表,并且合并成一个帖子地址,调用 图片处理函数 loadImage
for link in links:
link = "http://tieba.baidu.com" + link
self.loadImages(link) # 获取图片
def loadImages(self, link):
req = urllib2.Request(link, headers = self.ua_header)
html = urllib2.urlopen(req).read() selector = etree.HTML(html) # 获取这个帖子里所有图片的src路径
imagesLinks = selector.xpath('//img[@class="BDE_Image"]/@src') # 依次取出图片路径,下载保存
for imagesLink in imagesLinks:
self.writeImages(imagesLink) # 保存页面内容
def writeImages(self, imagesLink):
'''
将 images 里的二进制内容存入到 userNname 文件中
''' print imagesLink
print "正在存储文件 %d ..." % self.userName
# 1. 打开文件,返回一个文件对象
file = open('./images/' + str(self.userName) + '.png', 'wb') # 2. 获取图片里的内容
images = urllib2.urlopen(imagesLink).read() # 3. 调用文件对象write() 方法,将page_html的内容写入到文件里
file.write(images) # 4. 最后关闭文件
file.close() # 计数器自增1
self.userName += 1 # 模拟 main 函数
if __name__ == "__main__": # 首先创建爬虫对象
mySpider = Spider()
# 调用爬虫对象的方法,开始工作
mySpider.tiebaSpider()
python XML实例的更多相关文章
- Python导出Excel为Lua/Json/Xml实例教程(三):终极需求
相关链接: Python导出Excel为Lua/Json/Xml实例教程(一):初识Python Python导出Excel为Lua/Json/Xml实例教程(二):xlrd初体验 Python导出E ...
- Python导出Excel为Lua/Json/Xml实例教程(二):xlrd初体验
Python导出Excel为Lua/Json/Xml实例教程(二):xlrd初体验 相关链接: Python导出Excel为Lua/Json/Xml实例教程(一):初识Python Python导出E ...
- Python导出Excel为Lua/Json/Xml实例教程(一):初识Python
Python导出Excel为Lua/Json/Xml实例教程(一):初识Python 相关链接: Python导出Excel为Lua/Json/Xml实例教程(一):初识Python Python导出 ...
- python 解析XML python模块xml.dom解析xml实例代码
分享下python中使用模块xml.dom解析xml文件的实例代码,学习下python解析xml文件的方法. 原文转自:http://www.jbxue.com/article/16587.html ...
- Python 解析XML实例(xml.sax)
已知movies.xml <collection shelf="New Arrivals"> <movie title="Enemy Behind&qu ...
- Python XML解析(转载)
Python XML解析 什么是XML? XML 指可扩展标记语言(eXtensible Markup Language). 你可以通过本站学习XML教程 XML 被设计用来传输和存储数据. XML是 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python xml 模块
Python xml 模块 TOC 什么是xml? xml和json的区别 xml现今的应用 xml的解析方式 xml.etree.ElementTree SAX(xml.parsers.expat) ...
- python大法好——Python XML解析
Python XML解析 什么是XML? XML 被设计用来传输和存储数据. XML是一套定义语义标记的规则,这些标记将文档分成许多部件并对这些部件加以标识. 它也是元标记语言,即定义了用于定义其他与 ...
随机推荐
- 【java】字符串的反转
@org.junit.Test public void test(){ String a = "I IOVE CHINA"; if(a.indexOf(" ") ...
- RegexHelper
ylbtech-Unitity-cs: RegexHelper 验证帮助类 1.A,效果图返回顶部 1.B,源代码返回顶部 1.B.1,RegexMail #region RegexMail pu ...
- [转载]Ubuntu 14.04中root 密码忘记解决方法
Ubuntu 14.04中root 密码忘记解决方法 方法一: 如果用户具有sudo权限,那么直接可以运行如下命令: #sudo su root #passwd #更改密码 或者直接运行sudo ...
- list 组合,模糊查询llist 数据(不走数据库)
@ResponseBody @POST @Path("/megerPerson/{realName}") public ResultEntity partnerL ...
- Memcachedclientutils类
0.个人标签 我的CSDN博客地址: http://blog.csdn.net/caicongyang 1.依赖的jar包 commons-pool-1.5.6.jar slf4j-api-1.6.1 ...
- Linux 后台开发常用命令
1.automake编译 autoreconf -isv ./configure make 2.远程获取代码 rsync -aPvr --exclude=*/log/* *.*.*.*::home/s ...
- Android基于UDP的局域网聊天通信
代码地址如下:http://www.demodashi.com/demo/12057.html 记得把这几点描述好咯:代码实现过程 + 项目文件结构截图 + 演示效果 1. 开发环境 1.1 开发工具 ...
- struts上传文件 血案
记录一个图片上传之后没有后缀 拓展名问题 平常我们查询数据都是 fileImage=fileImageService.getQuery(); 让entity等于它 那么fileImage.getF ...
- MongoDB查询经典方式
原文地址:http://www.cnblogs.com/stephen-liu74/archive/2012/08/03/2553803.html 1. 基本查询: 构造查询数据. &g ...
- laravel框架查看执行过的sql语句
1.在routes.php中添加如下语句 Event::listen('illuminate.query', function($sql,$param) { file_put_contents ...