爬虫实战【6】Ajax内容解析-今日头条图集
Ajax技术
AJAX = Asynchronous JavaScript and XML(异步的 JavaScript 和 XML)。
Ajax并不是新的编程语言,而是一种使用现有标准的新方法,当然也不是很新了,在97年左右,微软就发明了ajax的关键技术,但是并没有推广;随着Google eath、google suggest和gmail的广泛应用,ajax才开始流行起来。
ajax最大的优点是在不重新加载整个页面的情况下,可以与服务器交换数据并更新网页的部分内容。
ajax不需要任何浏览器插件,但是需要用户允许javascript的执行。
Ajax的应用
运用XHTML+CSS来表达资讯;
运用JavaScript操作DOM(Document Object Model)来执行动态效果;
运用XML和XSLT操作资料;
运用XMLHttpRequest或新的Fetch API与网页服务器进行异步资料交换;
注意:AJAX与Flash、Silverlight和Java Applet等RIA技术是有区分的。
目前有很多使用ajax的应用案例,比如新浪微博,google地图,今日头条等。
今天我们借助今日头条见一下ajax内容的解析,如何爬取这类网站的内容。
今日头条的搜索功能
前几天一直登不上今日头条,估计网络监管太严,很多咨询类服务商都down掉了。。。
今天终于能打开了,赶紧来讲一下ajax的内容。
【插入图片,今日头条的搜索功能】
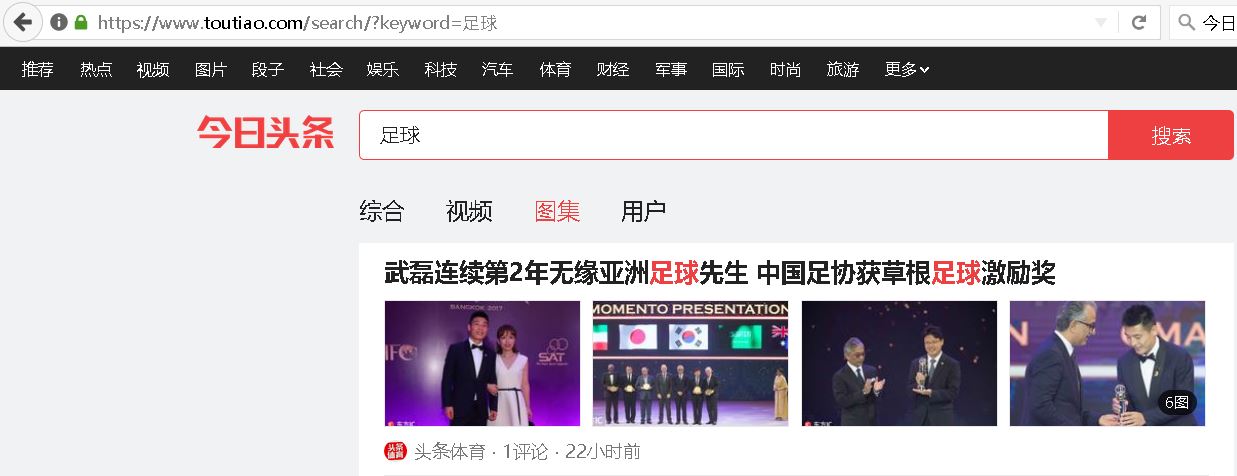
上面图片中可以看出利用今日头条搜索一些关键字,可以返回很多内容,请看四个标签,综合、视频、图集和用户,我们今天讲一下图集。也就是标签选项卡设置为图集,如何设置后面会讲清楚。
Index页的源代码
假设我们搜索足球关键字(哈哈,不搜索美女了。。。),我们看一下网页的源代码是什么情况。
【插入图片,index源代码】

源代码中除了一些基本的html标签,就是各种js了,没有我们想要的一些url内容或者图集的信息。
上面说过了,今日头条采用了ajax技术来加载内容,那么根据ajax技术的特点,肯定有一部分数据会从服务器发送到我们的浏览器上来,否则网页不会显示出这些图集的内容。
那么这些数据在哪里呢?
Ajax加载的数据在哪?
打开浏览器的调试,请选择网络标签,选择XHR内容,看下面出现的几个文件。
【插入图片,如何打开ajax加载的内容】

我们看这几个文件的类型,都是json格式的。
再看search_content的类容,除了offset的值改变止呕,其他都是一样的。因为我们滚动过页面了,每页正好显示20项内容,想必读者一下子就能明白这个offset的内容,就是用来加载多个页面的控制器。
我们看一个search_content的消息头:
【插入图片,json的消息头】

这时一个get请求,我们可以用requests库的get方法直接来请求到json文件。但是url的内容是啥呢?
大家看一下上图中的几个参数,尤其是最后的cur_tab设置为3,因为3才表示的选择的是图集,1的话是综合,2是视频,上面提到过。
我们只要改变其中的offset参数,就能够得到多个页面,每页20个内容。
我们再来看一下响应内容:
【插入图片,json的响应信息】

因为是json格式的内容,里面都是一些key:value格式的内容,我们主要关注data下面的20个内容,每个内容中都包含article_url关键字信息,这个信息就是打开每个图集的url,我们通过这个url就能访问具体的图集了。
关于网站解析的内容今天就讲到这里,我们再来看一下代码,如何获取这些每个图集的url。
1、获取index页面的json内容
import requests
from urllib.parser import urlencode
def get_page_index(offset):
#cur_tab标签一定要写正确,3才代表图集,很重要
data={
'offset':offset,
'format':'json',
'keyword':'足球',
'autoload':'true',
'count':'20',
'cur_tab':'3'
}
url='https://www.toutiao.com/search_content/?'+urlencode(data)
try:
response = requests.get(url)
if response.status_code==200:
#print(response.text)
return response.text
else:
return None
except Exception:
print('请求索引页出错!')
return None
我们设置了一个offset参数,这样就能控制获取哪一个页面,也就是实现自动向下滑动的功能。
data是我们在get请求时url的参数内容,我们用一个字典来表示,使用urlencode来编码。
这个访问还是很顺利的,并没有再提交额外的header参数。
2、对json内容进行解析
import json
def parse_page_index(html):
data=json.loads(html)
result=[]
if data and 'data' in data.keys():
for item in data.get('data'):
article_url=item.get('article_url')
if article_url and ('group' in article_url):
result.append(article_url)
return result
因为要解析json内容,所以导入了json库。
我们要获取的是json内容里面,data标签下各项里面的article_url信息,所以设置了一些筛选,data信息中一定要包含'data'关键字才做解析。
由于我们想要图集,虽然设置了cur_tab为3,但是返回的一些url还是不太规范,我们在url中设置一定要包含group字符串,才能视作图集。
然后将每个url都添加到result列表中。
3、开启多进程运行
from multiprocessing import Pool
def main(offset):
html=get_page_index(offset)
for url in parse_page_index(html):
print(url)
if __name__=='__main__':
p=Pool()
p.map(main,[i*20 for i in range(3)])
我们先打开3个页面尝试一下,采用多进程可以快一些,虽然现在代码少,但是理念要掌握。
【插入图片,url结果】
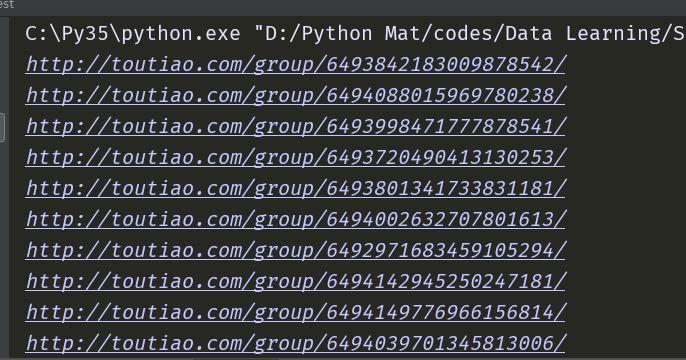
OK,今天就先到这里,明天再继续讲一下如何在这些url中获取图片。

爬虫实战【6】Ajax内容解析-今日头条图集的更多相关文章
- 用Ajax爬取今日头条图片集
Ajax原理 在用requests抓取页面时,得到的结果可能和浏览器中看到的不一样:在浏览器中可以正常显示的页面数据,但用requests得到的结果并没有.这是因为requests获取的都是原始 ...
- 【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图【华为云技术分享】
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- 【Python3网络爬虫开发实战】 分析Ajax爬取今日头条街拍美图
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:haoxuan10 本节中,我们以今日头条为例来尝试通过分析Ajax请求 ...
- 转:【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- 爬虫—分析Ajax爬取今日头条图片
以今日头条为例分析Ajax请求抓取网页数据.本次抓取今日头条的街拍关键字对应的图片,并保存到本地 一,分析 打开今日头条主页,在搜索框中输入街拍二字,打开开发者工具,发现浏览器显示的数据不在其源码里面 ...
- 分析Ajax爬取今日头条街拍美图-崔庆才思路
站点分析 源码及遇到的问题 代码结构 方法定义 需要的常量 关于在代码中遇到的问题 01. 数据库连接 02.今日头条的反爬虫机制 03. json解码遇到的问题 04. 关于response.tex ...
- 分析AJAX抓取今日头条的街拍美图并把信息存入mongodb中
今天学习分析ajax 请求,现把学得记录, 把我们在今日头条搜索街拍美图的时候,今日头条会发起ajax请求去请求图片,所以我们在网页源码中不能找到图片的url,但是今日头条网页中有一个json 文件, ...
- 关于爬虫的日常复习(9)—— 实战:分析Ajax抓取今日头条接拍美图
- Python+Selenium爬虫实战一《将QQ今日话题发布到个人博客》
前提条件: 1.使用Wamp Server部署WordPress个人博客,网上资料较多,这里不过多介绍 思路: 1.首先qq.com首页获取到今日话题的的链接: 2.通过今日话题链接访问到今日话题,并 ...
随机推荐
- 对AOP切面的一些整理与理解
首先上一张AOP的图示 一:几个重要的概念 1> 切面:横切关注点(跨越应用程序多个模块的功能)被模块化的特殊对象[验证切面.日志切面] 2> 通知:切面中的每个方法 3& ...
- Linux学习笔记 (四)归档和压缩
一.zip压缩命令: 1.压缩文件: 格式:zip 压缩文件 源文件 例:zip abc.zip abc //将abc文件压缩到abc.zip文件内. 2.压缩目录: 格式:zip –r 压缩目录 ...
- lodash forIn forOwn 遍历对象属性
_.forIn(object, [iteratee=_.identity]) 使用 iteratee 遍历对象的自身和继承的可枚举属性. function Foo() { this.a = 1; th ...
- 使用apache POI解析Excel文件
1. Apache POI简介 Apache POI是Apache软件基金会的开放源码函式库,POI提供API给Java程式对Microsoft Office格式档案读和写的功能. 2. POI结构 ...
- DropFileName = "svchost.exe" 问题解决方案
1.至以下链接处下载ATTK扫描工具: http://support.trendmicro.com.cn ... stomizedpackage.exe (32位) http://support.tr ...
- javascript中window与document对象、setInterval与setTimeout定时器的用法与区别
一.写在前面 本人前端菜鸟一枚,学习前端不久,学习过程中有很多概念.定义在使用时容易混淆,在此给向我一样刚踏入前端之门的童鞋们归纳一下.今天给大家分享一下js中window与document对象.se ...
- fpga技能树
- centos7下安装mysql5.7和jdk 1.8
安装mysql5.7 具体安装过程可参见官网:A Quick Guide to Using the MySQL Yum Repository 进入/usr/local/src文件夹. cd /usr/ ...
- mock的时候验证代码行是否执行
verify(advertismentService).queryAdvitismentInfForApp(baseBOs, false);
- iOS使用AVCaptureSession自定义相机
关于iOS调用摄像机来获取照片,通常我们都会调用UIImagePickerController来调用系统提供的相机来拍照,这个控件非常好 用.但是有时UIImagePickerController控件 ...