机器学习-无监督机器学习-kmeans-17
1. 什么是聚类
无监督机器学习的一种 输入数据只有X 没有y
将已有的数据 根据相似度 将划分到不同的簇 (花团锦簇)
步骤:
- 随机选择k个簇的中心点
- 样本根据距离中心点的距离分配到不同的簇
- 重新计算簇的中心点
- 重复 2-3直到所有样本 分配的簇不再发生改变
距离的计算:
Euclidean Distance 欧式距离
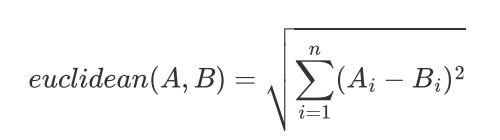
余弦距离
两个向量的夹角余弦值 -1 +1:
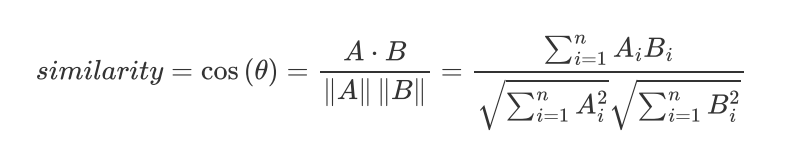
1-cos(theta) 称为余弦距离
欧氏距离体现数值上的绝对差异,而余弦距离体现方向上的相对差异
cosine相似度更适用于文本
举例:

后面两篇文章来自同一篇,余弦距离测度更准确,因为来自相同的分布,
归一化之后两种测量方式存在单调关系 选择谁都一样:
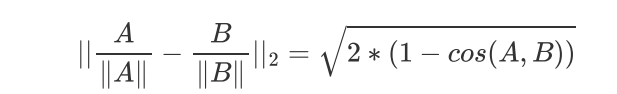
kmeans算法的目标函数:


每个簇里面 元素距离中心点的距离最小
算法不保证找到最好的解,目标函数是非凸函数,通常的做法就是运行KMeans很多次,每次随机初始化不同的初始中心点,然后从多次运行结果中选择最好的局部最优解
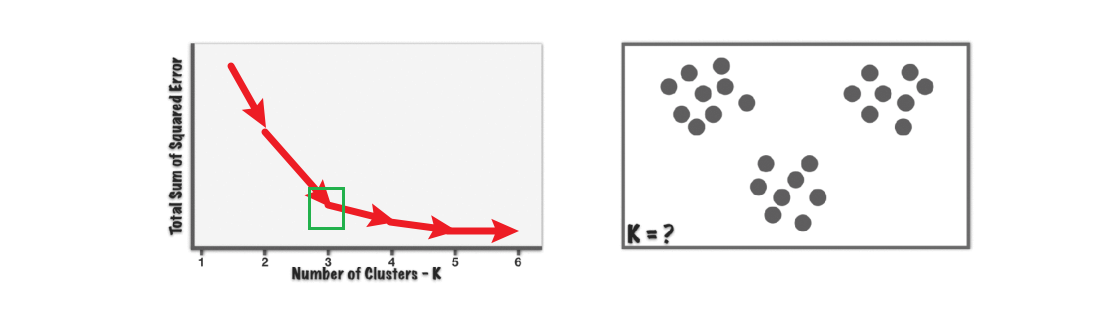
聚类簇的 数目k的选择:
改变聚类数K,然后进行聚类,计算损失函数,拐点处即为推荐的聚类数
聚类本身是为了有监督任务服务的
例如聚类产生features【譬如KMeans用于某个或某些个数据特征的离散化】然后将KMeans离散化后的特征用于下游任务),则可以直接根据下游任务的metrics进行评估更好
例如:衣服尺寸的分类
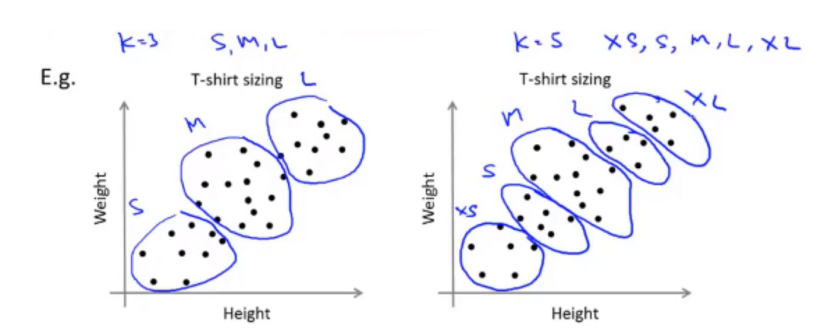
2. 代码实现
#!/usr/bin/env python
# coding: utf-8
# In[6]:
import random
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
# In[3]:
def disCos(vecA, vecB):
return np.dot(vecA, vecB)/(np.sqrt(np.sum(np.square(vecA)))*np.sqrt(np.sum(np.square(vecB))))
# In[4]:
def disEclud(vecA, vecB):
return np.sqrt(np.sum(np.power(vecA-vecB, 2)))
# In[22]:
def ranCent(dataSet, k):
m, n = dataSet.shape
index_list = list(range(m))
np.random.shuffle(index_list)
centroids = dataSet[index_list][:k]
return centroids
# In[44]:
def kMeans(dataSet, k, disMeans=disEclud):
m, n = dataSet.shape
clusterAssment = np.zeros((m, 2)) # 用于存放 属于哪一类 以及距离该类中心点的距离
centroids = ranCent(dataSet, k)
clusterChanged = True
while clusterChanged:
clusterChanged = False
# 1. 将样本点 根据距离最近 划分到所属类别
for i in range(m):
minDist = float("inf")
minIndex = -1
for j in range(k):
distJI = disMeans(centroids[j, :], dataSet[i, :])
if distJI < minDist:
minDist = distJI
minIndex = j
if clusterAssment[i, 0] != minDist:
clusterChanged = True # 距离有变化
clusterAssment[i, :] = minIndex, minDist**2 # 将每个样本的所属类别 以及距离 存入
print(centroids)
# 2. 更新每个类的中心点
for cent in range(k):
ptsInCluster = dataSet[np.nonzero(clusterAssment[: 0] == cent)] # 属于该类别的所有x取出
centroids[cent, :] = np.mean(ptsInCluster, axis=0)
return centroids, clusterAssment
# In[47]:
import jieba
doc1 = '我爱北京北京天安门'
doc2 = '我爱北京颐和园'
doc3 = "世界杯梅西夺冠"
doc4 = "世界杯精彩"
docs = [doc1, doc2, doc3, doc4]
docs = [" ".join(list(jieba.cut(sentence))) for sentence in docs]
X = TfidfVectorizer().fit_transform(docs)
result = kMeans(X.A, k=2, disMeans=disCos)
result
# In[48]:
a = np.array([[1, 2], [2, 4], [3, 6]])
a
# In[49]:
a[:, 0] # 取出第一个维度
# In[50]:
a[:, 1]
# In[53]:
np.mean(a, axis=0) # 沿着 竖直方向求平均
机器学习-无监督机器学习-kmeans-17的更多相关文章
- 1(1).有监督 VS 无监督
对比一 : 有标签 vs 无标签 有监督机器学习又被称为“有老师的学习”,所谓的老师就是标签.有监督的过程为先通过已知的训练样本(如已知输入和对应的输出)来训练,从而得到一个最优模型,再将这个模型应用 ...
- 学习笔记CB008:词义消歧、有监督、无监督、语义角色标注、信息检索、TF-IDF、隐含语义索引模型
词义消歧,句子.篇章语义理解基础,必须解决.语言都有大量多种含义词汇.词义消歧,可通过机器学习方法解决.词义消歧有监督机器学习分类算法,判断词义所属分类.词义消歧无监督机器学习聚类算法,把词义聚成多类 ...
- 深度学习——无监督,自动编码器——尽管自动编码器与 PCA 很相似,but自动编码器既能表征线性变换,也能表征非线性变换;而 PCA 只能执行线性变换
自动编码器是一种有三层的神经网络:输入层.隐藏层(编码层)和解码层.该网络的目的是重构其输入,使其隐藏层学习到该输入的良好表征. 自动编码器神经网络是一种无监督机器学习算法,其应用了反向传播,可将目标 ...
- darktrace 亮点是使用的无监督学习(贝叶斯网络、聚类、递归贝叶斯估计)发现未知威胁——使用无人监督 机器学习反而允许系统发现罕见的和以前看不见的威胁,这些威胁本身并不依赖 不完善的训练数据集。 学习正常数据,发现异常!
先说说他们的产品:企业免疫系统(基于异常发现来识别威胁) 可以看到是面向企业内部安全的! 优点整个网络拓扑的三维可视化企业威胁级别的实时全局概述智能地聚类异常泛频谱观测 - 高阶网络拓扑;特定群集,子 ...
- 机器学习聚类算法之K-means
一.概念 K-means是一种典型的聚类算法,它是基于距离的,是一种无监督的机器学习算法. K-means需要提前设置聚类数量,我们称之为簇,还要为之设置初始质心. 缺点: 1.循环计算点到质心的距离 ...
- 机器学习 - 算法 - 聚类算法 K-MEANS / DBSCAN算法
聚类算法 概述 无监督问题 手中无标签 聚类 将相似的东西分到一组 难点 如何 评估, 如何 调参 基本概念 要得到的簇的个数 - 需要指定 K 值 质心 - 均值, 即向量各维度取平均 距离的度量 ...
- 无监督LDA、PCA、k-means三种方法之间的的联系及推导
\(LDA\)是一种比较常见的有监督分类方法,常用于降维和分类任务中:而\(PCA\)是一种无监督降维技术:\(k\)-means则是一种在聚类任务中应用非常广泛的数据预处理方法. 本文的 ...
- kaggle信用卡欺诈看异常检测算法——无监督的方法包括: 基于统计的技术,如BACON *离群检测 多变量异常值检测 基于聚类的技术;监督方法: 神经网络 SVM 逻辑回归
使用google翻译自:https://software.seek.intel.com/dealing-with-outliers 数据分析中的一项具有挑战性但非常重要的任务是处理异常值.我们通常将异 ...
- web安全之机器学习入门——2.机器学习概述
目录 0 前置知识 什么是机器学习 机器学习的算法 机器学习首先要解决的两个问题 一些基本概念 数据集介绍 1 正文 数据提取 数字型 文本型 数据读取 0 前置知识 什么是机器学习 通过简单示例来理 ...
- 【机器学习】Google机器学习工程的43条最佳实践
https://blog.csdn.net/ChenVast/article/details/81449509 本文档旨在帮助那些掌握机器学习基础知识的人从Google机器学习的最佳实践中获益.它提供 ...
随机推荐
- 神经网络优化篇:详解梯度消失/梯度爆炸(Vanishing / Exploding gradients)
梯度消失/梯度爆炸 训练神经网络,尤其是深度神经所面临的一个问题就是梯度消失或梯度爆炸,也就是训练神经网络的时候,导数或坡度有时会变得非常大,或者非常小,甚至于以指数方式变小,这加大了训练的难度. 接 ...
- 如何构建一个 NodeJS 影院微服务并使用 Docker 部署
如何构建一个 NodeJS 影院微服务并使用 Docker 部署 前言 如何构建一个 NodeJS 影院微服务并使用 Docker 部署.在这个系列中,将构建一个 NodeJS 微服务,并使用 Doc ...
- 聊一聊如何结合Microsoft.Extensions.DependenyInjection和Castle.Core
.net下 aop的实现AspectCore+Microsoft.Extensions.DependenyInjection.Autofac+Castle .DoraInterception+Micr ...
- linux中mysql下载安装部署
创建mysql文件 mkdir mysql 首先通过yum下载wget命令 yum -y install wget 在mysql文件中通过wget下载MySQL存储库 wget https://dev ...
- 华为云GaussDB助力工商银行、华夏银行斩获“十佳卓越实践奖”
近日,2023金融街论坛年会在北京成功举办.活动期间,由北京金融科技产业联盟举办的全球金融科技大会系列活动--分布式数据库金融应用研究与实践大赛获奖结果正式公布.其中,由华为云GaussDB参与支持的 ...
- 数据湖探索DLI新功能:基于openLooKeng的交互式分析
摘要:基于华为开源openLooKeng引擎的交互式分析功能,将重磅发布便于用户构建轻量级流.批.交互式全场景数据湖. 在这个"信息爆炸"的时代,大数据已经成为这个时代的关键词之一 ...
- GaussDB(DWS)字符串处理函数返回错误结果集排查
摘要:在使用字符串处理函数时,有时会出现非预期结果的场景.在排除使用问题后,应该从encoding和数据本身开始排查. 本文分享自华为云社区<GaussDB(DWS)字符串处理函数返回错误结果集 ...
- GaussDB(DWS)集群中寻找节点CPU占用高的语句
摘要:本文主要通过实例讲解如何通过gs_cpuwatcher.sh 脚本寻找CPU占用高语句. 本文分享自华为云社区<GaussDB(DWS) gs_cpuwatcher.sh 脚本如何寻找CP ...
- pip升级和卸载安装的第三方库
pip install --upgrade 第三方库名 pip uninstall 第三方库名
- 火山引擎 ByteHouse:如何提升 18000 节点的 ClickHouse 可用性?
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 ClickHouse 是业内被广泛使用的 OLAP 引擎.当集群规模过大时,ClickHouse 则面临使用局限性 ...