MKV与MatroskaExtractor
mkv封装格式相关内容可以参考:MKV 文件格式解析_Martyn哥的博客-CSDN博客_mkv 格式解析
本篇主要是用来记录MatroskaExtractor是如何解析EBML的,如何解析EBML header以及SEGMENT的
构造函数
先看构造函数,android MKV文件的解析需要依赖外部库mkvparser,首先会去解析EBML header(这个部分在sniff中会先调用一次判断是否为mkv文件)
MatroskaExtractor::MatroskaExtractor(DataSourceHelper *source)
: mDataSource(source),
mReader(new DataSourceBaseReader(mDataSource)),
mSegment(NULL),
mExtractedThumbnails(false),
mIsWebm(false),
mSeekPreRollNs(0) {
off64_t size;
mIsLiveStreaming =
(mDataSource->flags()
& (DataSourceBase::kWantsPrefetching
| DataSourceBase::kIsCachingDataSource))
&& mDataSource->getSize(&size) != OK; // 1、解析EBML header
mkvparser::EBMLHeader ebmlHeader;
long long pos;
if (ebmlHeader.Parse(mReader, pos) < 0) {
return;
} if (ebmlHeader.m_docType && !strcmp("webm", ebmlHeader.m_docType)) {
mIsWebm = true;
} // 2、创建Segment
long long ret =
mkvparser::Segment::CreateInstance(mReader, pos, mSegment); if (ret) {
CHECK(mSegment == NULL);
return;
} if (mIsLiveStreaming) {
// from mkvparser::Segment::Load(), but stop at first cluster
ret = mSegment->ParseHeaders();
if (ret == 0) {
long len;
ret = mSegment->LoadCluster(pos, len);
if (ret >= 1) {
// no more clusters
ret = 0;
}
} else if (ret > 0) {
ret = mkvparser::E_BUFFER_NOT_FULL;
}
} else {
// 3、parse Segment header
ret = mSegment->ParseHeaders();
if (ret < 0) {
ALOGE("Segment parse header return fail %lld", ret);
delete mSegment;
mSegment = NULL;
return;
} else if (ret == 0) {
// 找到Cues
const mkvparser::Cues* mCues = mSegment->GetCues();
// 找到SeekHead
const mkvparser::SeekHead* mSH = mSegment->GetSeekHead();
if ((mCues == NULL) && (mSH != NULL)) {
size_t count = mSH->GetCount();
const mkvparser::SeekHead::Entry* mEntry;
for (size_t index = 0; index < count; index++) {
mEntry = mSH->GetEntry(index);
if (mEntry->id == libwebm::kMkvCues) { // Cues ID
long len;
long long pos;
mSegment->ParseCues(mEntry->pos, pos, len);
mCues = mSegment->GetCues();
ALOGV("find cue data by seekhead");
break;
}
}
} if (mCues) {
long len;
ret = mSegment->LoadCluster(pos, len);
ALOGV("has Cue data, Cluster num=%ld", mSegment->GetCount());
} else {
long status_Load = mSegment->Load();
ALOGW("no Cue data,Segment Load status:%ld",status_Load);
}
} else if (ret > 0) {
ret = mkvparser::E_BUFFER_NOT_FULL;
}
} if (ret < 0) {
char uri[1024];
if(!mDataSource->getUri(uri, sizeof(uri))) {
uri[0] = '\0';
}
ALOGW("Corrupt %s source: %s", mIsWebm ? "webm" : "matroska",
uriDebugString(uri).c_str());
delete mSegment;
mSegment = NULL;
return;
} // 获取tracks
addTracks();
}
EBMLHeader::Parse
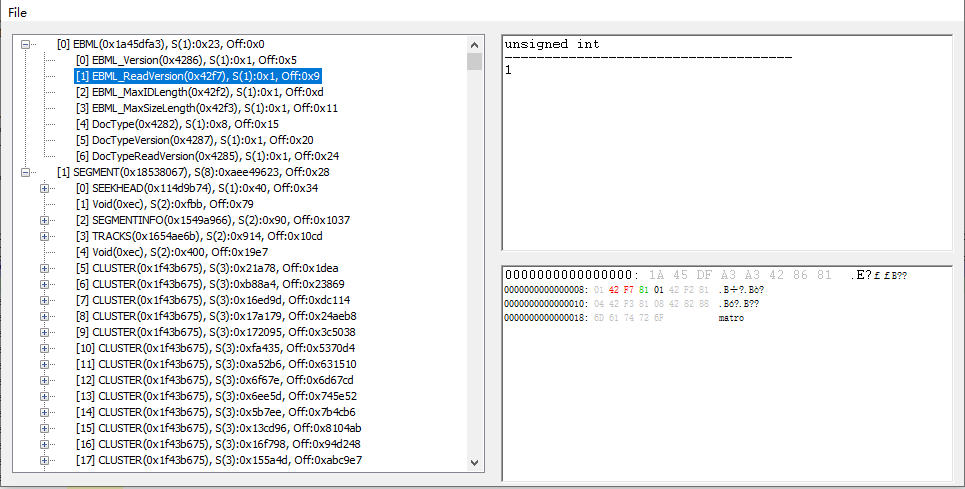
下图是EMBL Tree解析的mkv文件,EBML_ReadVersion是element id(0x47),对应红色部分;后面的s(1):0x1,括号里的1表示数据长度,冒号后面的0x01表示数据内容的长度为1,对应绿色部分(这里的计算比较复杂一些,使用的是ReadUInt);最后面的0x01表示数据内容;
long long EBMLHeader::Parse(IMkvReader* pReader, long long& pos) {
if (!pReader)
return E_FILE_FORMAT_INVALID;
long long total, available;
long status = pReader->Length(&total, &available);
if (status < 0) // error
return status;
pos = 0;
// 检查0x1A的位置
while (pos < kMaxScanBytes) {
status = pReader->Read(pos, 1, &scan_byte);
if (status < 0) // error
return status;
else if (status > 0)
return E_BUFFER_NOT_FULL;
if (scan_byte == kEbmlByte0)
break;
++pos;
}
long len = 0;
// 读取ID
const long long ebml_id = ReadID(pReader, pos, len);
if (ebml_id == E_BUFFER_NOT_FULL)
return E_BUFFER_NOT_FULL;
// 检查ID是否为0x1A45DFA3,mkv文件会以这四个字节为开头
if (len != 4 || ebml_id != libwebm::kMkvEBML)
return E_FILE_FORMAT_INVALID;
// Move read pos forward to the EBML header size field.
// 修改文件读取偏移量
pos += 4;
// Read length of size field.
// 接下来的一个字节表示数据长度,下面这部分到ReadUInt之前都是在检查数据长度是否正常
long long result = GetUIntLength(pReader, pos, len);
if (result < 0) // error
return E_FILE_FORMAT_INVALID;
else if (result > 0) // need more data
return E_BUFFER_NOT_FULL;
if (len < 1 || len > 8)
return E_FILE_FORMAT_INVALID;
if ((total >= 0) && ((total - pos) < len))
return E_FILE_FORMAT_INVALID;
if ((available - pos) < len)
return pos + len; // try again later
// 真正读取数据长度
// Read the EBML header size.
result = ReadUInt(pReader, pos, len);
if (result < 0) // error
return result;
pos += len; // consume size field
// pos now designates start of payload
if ((total >= 0) && ((total - pos) < result))
return E_FILE_FORMAT_INVALID;
if ((available - pos) < result)
return pos + result;
const long long end = pos + result;
Init();
while (pos < end) {
long long id, size;
status = ParseElementHeader(pReader, pos, end, id, size);
if (status < 0) // error
return status;
if (size == 0)
return E_FILE_FORMAT_INVALID;
if (id == libwebm::kMkvEBMLVersion) {
m_version = UnserializeUInt(pReader, pos, size);
if (m_version <= 0)
return E_FILE_FORMAT_INVALID;
} else if (id == libwebm::kMkvEBMLReadVersion) {
m_readVersion = UnserializeUInt(pReader, pos, size);
if (m_readVersion <= 0)
return E_FILE_FORMAT_INVALID;
} else if (id == libwebm::kMkvEBMLMaxIDLength) {
m_maxIdLength = UnserializeUInt(pReader, pos, size);
if (m_maxIdLength <= 0)
return E_FILE_FORMAT_INVALID;
} else if (id == libwebm::kMkvEBMLMaxSizeLength) {
m_maxSizeLength = UnserializeUInt(pReader, pos, size);
if (m_maxSizeLength <= 0)
return E_FILE_FORMAT_INVALID;
} else if (id == libwebm::kMkvDocType) {
if (m_docType)
return E_FILE_FORMAT_INVALID;
status = UnserializeString(pReader, pos, size, m_docType);
if (status) // error
return status;
} else if (id == libwebm::kMkvDocTypeVersion) {
m_docTypeVersion = UnserializeUInt(pReader, pos, size);
if (m_docTypeVersion <= 0)
return E_FILE_FORMAT_INVALID;
} else if (id == libwebm::kMkvDocTypeReadVersion) {
m_docTypeReadVersion = UnserializeUInt(pReader, pos, size);
if (m_docTypeReadVersion <= 0)
return E_FILE_FORMAT_INVALID;
}
pos += size;
}
if (pos != end)
return E_FILE_FORMAT_INVALID;
// Make sure DocType, DocTypeReadVersion, and DocTypeVersion are valid.
if (m_docType == NULL || m_docTypeReadVersion <= 0 || m_docTypeVersion <= 0)
return E_FILE_FORMAT_INVALID;
// Make sure EBMLMaxIDLength and EBMLMaxSizeLength are valid.
if (m_maxIdLength <= 0 || m_maxIdLength > 4 || m_maxSizeLength <= 0 ||
m_maxSizeLength > 8)
return E_FILE_FORMAT_INVALID;
return 0;
}
long long ReadID(IMkvReader* pReader, long long pos, long& len) {
if (pReader == NULL || pos < 0)
return E_FILE_FORMAT_INVALID;
// Read the first byte. The length in bytes of the ID is determined by
// finding the first set bit in the first byte of the ID.
unsigned char temp_byte = 0;
// 先读取一个字节,读到得应该是0x1A
int read_status = pReader->Read(pos, 1, &temp_byte);
if (read_status < 0)
return E_FILE_FORMAT_INVALID;
else if (read_status > 0) // No data to read.
return E_BUFFER_NOT_FULL;
if (temp_byte == 0) // ID length > 8 bytes; invalid file.
return E_FILE_FORMAT_INVALID;
int bit_pos = 0;
const int kMaxIdLengthInBytes = 4;
const int kCheckByte = 0x80;
// Find the first bit that's set.
// 这里会对应到博文里面的 ID数据长度等于起始0的个数加1
bool found_bit = false;
for (; bit_pos < kMaxIdLengthInBytes; ++bit_pos) {
if ((kCheckByte >> bit_pos) & temp_byte) { // 用0x80不断向右移位,并且和读到数据与运算,计算0的个数
found_bit = true;
break;
}
}
if (!found_bit) {
// The value is too large to be a valid ID.
return E_FILE_FORMAT_INVALID;
}
// Read the remaining bytes of the ID (if any).
const int id_length = bit_pos + 1; // ID长度等于起始0的个数加1
long long ebml_id = temp_byte;
for (int i = 1; i < id_length; ++i) {
ebml_id <<= 8;
read_status = pReader->Read(pos + i, 1, &temp_byte);
if (read_status < 0)
return E_FILE_FORMAT_INVALID;
else if (read_status > 0)
return E_BUFFER_NOT_FULL;
ebml_id |= temp_byte; // 继续往后读取ID,并做与运算,返回真正的ID
}
len = id_length;
return ebml_id;
}
long long GetUIntLength(IMkvReader* pReader, long long pos, long& len) {
if (!pReader || pos < 0)
return E_FILE_FORMAT_INVALID;
long long total, available;
int status = pReader->Length(&total, &available);
if (status < 0 || (total >= 0 && available > total))
return E_FILE_FORMAT_INVALID;
len = 1;
if (pos >= available)
return pos; // too few bytes available
unsigned char b;
// 读取下一个字节 0xA3
status = pReader->Read(pos, 1, &b);
if (status != 0)
return status;
if (b == 0) // we can't handle u-int values larger than 8 bytes
return E_FILE_FORMAT_INVALID;
unsigned char m = 0x80;
// 数据长度为起始0的个数 + 1
while (!(b & m)) {
m >>= 1;
++len;
}
return 0; // success
}
long long ReadUInt(IMkvReader* pReader, long long pos, long& len) {
if (!pReader || pos < 0)
return E_FILE_FORMAT_INVALID;
len = 1;
unsigned char b;
int status = pReader->Read(pos, 1, &b);
if (status < 0) // error or underflow
return status;
if (status > 0) // interpreted as "underflow"
return E_BUFFER_NOT_FULL;
if (b == 0) // we can't handle u-int values larger than 8 bytes
return E_FILE_FORMAT_INVALID;
unsigned char m = 0x80;
// 数据长度为起始0的个数 + 1(这个长度为数据长度的长度)
while (!(b & m)) {
m >>= 1;
++len;
}
// result为数据内容的长度,第一个字节需要用m取反并做与运算
long long result = b & (~m);
++pos;
for (int i = 1; i < len; ++i) {
status = pReader->Read(pos, 1, &b);
if (status < 0) {
len = 1;
return status;
}
if (status > 0) {
len = 1;
return E_BUFFER_NOT_FULL;
}
result <<= 8;
result |= b;
++pos;
}
return result;
}
Segment::CreateInstance
看完上面的内容,Segment是如何创建的就很简单了
long long Segment::CreateInstance(IMkvReader* pReader, long long pos,
Segment*& pSegment) {
if (pReader == NULL || pos < 0)
return E_PARSE_FAILED; pSegment = NULL; long long total, available; const long status = pReader->Length(&total, &available); if (status < 0) // error
return status; if (available < 0)
return -1; if ((total >= 0) && (available > total))
return -1; for (;;) {
if ((total >= 0) && (pos >= total))
return E_FILE_FORMAT_INVALID; // Read ID
long len;
long long result = GetUIntLength(pReader, pos, len); if (result) // error, or too few available bytes
return result; if ((total >= 0) && ((pos + len) > total))
return E_FILE_FORMAT_INVALID; if ((pos + len) > available)
return pos + len; const long long idpos = pos;
// 读取element id
const long long id = ReadID(pReader, pos, len); if (id < 0)
return E_FILE_FORMAT_INVALID; pos += len; // consume ID // Read Size
// 下面是老套的数据长度检查
result = GetUIntLength(pReader, pos, len); if (result) // error, or too few available bytes
return result; if ((total >= 0) && ((pos + len) > total))
return E_FILE_FORMAT_INVALID; if ((pos + len) > available)
return pos + len;
// 读取数据内容长度
long long size = ReadUInt(pReader, pos, len); if (size < 0) // error
return size; pos += len; // consume length of size of element // Pos now points to start of payload // Handle "unknown size" for live streaming of webm files.
const long long unknown_size = (1LL << (7 * len)) - 1; // Segment的id为0x18 53 80 67
if (id == libwebm::kMkvSegment) {
if (size == unknown_size)
size = -1; else if (total < 0)
size = -1; else if ((pos + size) > total)
size = -1;
// 创建Segment,传入参数为Segment element起始位置、数据内容开始位置、数据长度
pSegment = new (std::nothrow) Segment(pReader, idpos, pos, size);
if (pSegment == NULL)
return E_PARSE_FAILED; return 0; // success
} if (size == unknown_size)
return E_FILE_FORMAT_INVALID; if ((total >= 0) && ((pos + size) > total))
return E_FILE_FORMAT_INVALID; if ((pos + size) > available)
return pos + size; pos += size; // consume payload
}
}
Segment::ParseHeaders
这个方法用于parse Segment中的track、seekhead等信息,比较重要,它会找到对应的element id以及数据,如何解析数据的这里就不贴代码了,如果碰到问题可以去查看相关的parse方法
long long Segment::ParseHeaders() {
// Outermost (level 0) segment object has been constructed,
// and pos designates start of payload. We need to find the
// inner (level 1) elements.
long long total, available;
const int status = m_pReader->Length(&total, &available);
if (status < 0) // error
return status;
if (total > 0 && available > total)
return E_FILE_FORMAT_INVALID;
const long long segment_stop = (m_size < 0) ? -1 : m_start + m_size;
if ((segment_stop >= 0 && total >= 0 && segment_stop > total) ||
(segment_stop >= 0 && m_pos > segment_stop)) {
return E_FILE_FORMAT_INVALID;
}
for (;;) {
if ((total >= 0) && (m_pos >= total))
break;
if ((segment_stop >= 0) && (m_pos >= segment_stop))
break;
long long pos = m_pos;
const long long element_start = pos;
// Avoid rolling over pos when very close to LLONG_MAX.
unsigned long long rollover_check = pos + 1ULL;
if (rollover_check > LLONG_MAX)
return E_FILE_FORMAT_INVALID;
if ((pos + 1) > available)
return (pos + 1);
// 很熟悉,检查数据长度
long len;
long long result = GetUIntLength(m_pReader, pos, len);
if (result < 0) // error
return result;
if (result > 0) {
// MkvReader doesn't have enough data to satisfy this read attempt.
return (pos + 1);
}
if ((segment_stop >= 0) && ((pos + len) > segment_stop))
return E_FILE_FORMAT_INVALID;
if ((pos + len) > available)
return pos + len;
const long long idpos = pos;
// 读取ID
const long long id = ReadID(m_pReader, idpos, len);
if (id < 0)
return E_FILE_FORMAT_INVALID;
// 如果ID 为Cluster则结束本次循环
if (id == libwebm::kMkvCluster)
break;
pos += len; // consume ID
if ((pos + 1) > available)
return (pos + 1);
// Read Size
// 检查数据长度
result = GetUIntLength(m_pReader, pos, len);
if (result < 0) // error
return result;
if (result > 0) {
// MkvReader doesn't have enough data to satisfy this read attempt.
return (pos + 1);
}
if ((segment_stop >= 0) && ((pos + len) > segment_stop))
return E_FILE_FORMAT_INVALID;
if ((pos + len) > available)
return pos + len;
// 读取数据内容长度
const long long size = ReadUInt(m_pReader, pos, len);
if (size < 0 || len < 1 || len > 8) {
// TODO(tomfinegan): ReadUInt should return an error when len is < 1 or
// len > 8 is true instead of checking this _everywhere_.
return size;
}
pos += len; // consume length of size of element
// Avoid rolling over pos when very close to LLONG_MAX.
rollover_check = static_cast<unsigned long long>(pos) + size;
if (rollover_check > LLONG_MAX)
return E_FILE_FORMAT_INVALID;
const long long element_size = size + pos - element_start;
// Pos now points to start of payload
if ((segment_stop >= 0) && ((pos + size) > segment_stop))
return E_FILE_FORMAT_INVALID;
// We read EBML elements either in total or nothing at all.
if ((pos + size) > available)
return pos + size;
// 如果ID为Info,则去创建SegmentInfo
if (id == libwebm::kMkvInfo) {
if (m_pInfo)
return E_FILE_FORMAT_INVALID;
m_pInfo = new (std::nothrow)
SegmentInfo(this, pos, size, element_start, element_size);
if (m_pInfo == NULL)
return -1;
const long status = m_pInfo->Parse();
if (status)
return status;
// 如果ID为Track,则去创建Track
} else if (id == libwebm::kMkvTracks) {
if (m_pTracks)
return E_FILE_FORMAT_INVALID;
m_pTracks = new (std::nothrow)
Tracks(this, pos, size, element_start, element_size);
if (m_pTracks == NULL)
return -1;
// 调用Tracks.parse方法来解析Track信息
const long status = m_pTracks->Parse();
if (status)
return status;
// 如果ID为Cues,则创建Cues对象
} else if (id == libwebm::kMkvCues) {
if (m_pCues == NULL) {
m_pCues = new (std::nothrow)
Cues(this, pos, size, element_start, element_size);
if (m_pCues == NULL)
return -1;
}
// 如果id为SeekHead,那么创建SeekHead对象
} else if (id == libwebm::kMkvSeekHead) {
if (m_pSeekHead == NULL) {
m_pSeekHead = new (std::nothrow)
SeekHead(this, pos, size, element_start, element_size);
if (m_pSeekHead == NULL)
return -1;
const long status = m_pSeekHead->Parse();
if (status)
return status;
}
} else if (id == libwebm::kMkvChapters) {
if (m_pChapters == NULL) {
m_pChapters = new (std::nothrow)
Chapters(this, pos, size, element_start, element_size);
if (m_pChapters == NULL)
return -1;
const long status = m_pChapters->Parse();
if (status)
return status;
}
} else if (id == libwebm::kMkvTags) {
if (m_pTags == NULL) {
m_pTags = new (std::nothrow)
Tags(this, pos, size, element_start, element_size);
if (m_pTags == NULL)
return -1;
const long status = m_pTags->Parse();
if (status)
return status;
}
}
m_pos = pos + size; // consume payload
}
if (segment_stop >= 0 && m_pos > segment_stop)
return E_FILE_FORMAT_INVALID;
if (m_pInfo == NULL) // TODO: liberalize this behavior
return E_FILE_FORMAT_INVALID;
if (m_pTracks == NULL)
return E_FILE_FORMAT_INVALID;
return 0; // success
}
本篇大致就先到这,了解了MKV是如何解析EBML的,后续如果有问题就很容易去定位了。
MKV与MatroskaExtractor的更多相关文章
- 【多媒体封装格式详解】---MKV
http://blog.csdn.net/tx3344/article/details/8162656# http://blog.csdn.net/tx3344/article/details/817 ...
- 多媒体封装格式----mkv
Matroska 开源多媒体容器标准.MKV属于其中的一部分.Matroska常见的有.MKV视频格式.MKA音频格式..MKS字幕格式..MK3D files (stereoscopic/3D vi ...
- 【转】用ffmpeg转多音轨的mkv文件
命令: ffmpeg -i AmericanCaptain.mkv -map 0:v -vcodec copy -map 0:a:1 -acodec copyAmericanCaptain.mp4 - ...
- How to convert mkv to mp4 lossless
ffmpeg -i example.mkv -vcodec copy -acodec copy example.mp4
- 怎么把mkv转成mp4,有什么方法
Mkv怎样转换成MP4呢?mkv是一种开放标准的自由的容器和文件格式,是一种多媒体封装格式,能够在一个文件中容纳无限数量的视频.音频.图片或字幕轨道.所以其不是一种压缩格式,而是Matroska定义的 ...
- 多媒体文件格式之MKV
[时间:2016-07] [状态:Open] MKV是一种开源的多媒体封装格式,是Matroska中应用比较多的格式之一.常见的后缀格式是.mkv(视频,包括音频和字幕)..mka(纯音频)..mks ...
- [批处理]批量提取MKV资源
最初是下了部没字幕的动漫,是720P MKV格式的,当时没注意,下完了以后才发现是没字幕的 后来去射手上找没有,百度了半天也没有 最后只能求救与已经下了这部动漫是MKV格式且是内挂字幕的人来帮忙 最后 ...
- vob文件转mkv
下载了一部片子,是所谓的dvd原盘,就是用软件将dvd碟片rip下来,视频文件是一堆vob文件.觉得这片子没必要看原盘,想压缩成mkv以减小体积,同时保持合适的清晰度. 首先想到用handbrake这 ...
- 视频格式mkv、mp4、avi、flv、mov、wmv、webm特点和区别
mkv是一种多媒体封装格式,这个封装格式可把多种不同编码的影像及 16 条或以上不同格式的音频和语言不同的字幕封装到一个 Matroska Media 档内. 它也是其中一种开放原始码的多媒体封装格式 ...
- win7下MKVToolNix进行mkv字幕封装
MKVToolNix下载地址(https://www.fosshub.com/MKVToolNix.html) 下载安装后打开,当时没创建桌面图标,GUI地址(C:\ProgramData\Micro ...
随机推荐
- 我为什么选择Wiki.js记笔记?
很长一段时间里,我都被困扰着,感觉陷入了笔记的泥潭,而积累的如此多的笔记也没有形成我自己的知识体系. 之前的记笔记方式 笔记的来源 微信公众号 技术博客 纸质书籍 官网文档 PDF 自己的零散想法 网 ...
- Graph Embedding-DeepWalk
一言以蔽之,DeepWalk是在graph上,通过随机游走来产生一段定长的结点序列,并将其通过word2vec的方式获得各个结点的embedding的算法. DeepWalk一共涉及以下几个内容: 随 ...
- mysql 重新整理——索引优化explain字段介绍一 [九]
前言 在七种介绍了explain这东西,那么具体来看下它是如何来运行的吧. 正文 id 来看一条语句:EXPLAIN select * from departments,dept_emp,employ ...
- 6个高级Vue3知识技巧
Vue 3是一个非常流行的前端框架,广泛应用于大型互联网企业和个人项目. 虽然我们已经熟悉了一些常见的 Vue 3 知识,但还有一些不太常见但实用性很强的点可以帮助我们进一步优化和提升 Vue 3 应 ...
- 树莓派和esp8266在局域网下使用UDP通信,esp8266采集adc数据传递给树莓派,树莓派在web上显示结果
树莓派和esp8266需要在同一局域网下 esp8266使用arduino开发: 接入一个电容土壤湿度传感器,采集湿度需要使用adc #include <ESP8266WiFi.h> #i ...
- 链栈的实现 C语言/C++
堆栈的链式存储C/C++实现--链栈 与顺序栈相比,链栈的优点在于不存在栈满上溢的问题.链栈通常使用单链表实现,进栈.出栈操作就是在单链表表头的 插入.删除操作.用单链表实现链栈时,使用不带头结点的单 ...
- Serverless 选型:深度解读 Serverless 架构及平台选择
作者 | 悟鹏 阿里巴巴技术专家 导读:本文尝试以日常开发流程为起点,分析开发者在每个阶段要面对的问题,然后组合解决方案,提炼面向 Serverless 的开发模型,并与业界提出的 Serverle ...
- 飞天大数据产品价值解读— SaaS模式云数据仓库MaxCompute
飞天大数据产品价值解读 - SaaS模式云数据仓库 MaxCompute摘要:企业在数字化转型过程中面临数据技术平台建设和运营的诸多挑战,随着现代化数据仓库向多功能.服务化方向发展演进,技术侧的变革为 ...
- 龙蜥开源Plugsched:首次实现 Linux kernel 调度器热升级 | 龙蜥技术
简介:对于plugsched而言,无论是 bugfix,还是性能优化,甚至是特性的增.删.改,都可胜任. 文/龙蜥社区内核开发人员 陈善佩.吴一昊.邓二伟 Plugsched 是 Linux 内 ...
- 谈谈C++新标准带来的属性(Attribute)
简介: 从C++11开始,标准引入了一个新概念"属性(attribute)",本文将简单介绍一下目前在C++标准中已经添加的各个属性以及常用属性的具体应用. 作者 | 寒冬来源 | ...