案例解析丨 Spark Hive 自定义函数应用
摘要:Spark目前支持UDF,UDTF,UDAF三种类型的自定义函数。
1. 简介
Spark目前支持UDF,UDTF,UDAF三种类型的自定义函数。UDF使用场景:输入一行,返回一个结果,一对一,比如定义一个函数,功能是输入一个IP地址,返回一个对应的省份。UDTF使用场景: 输入一行,返回多行(hive),一对多, 而sparkSQL中没有UDTF, spark中用flatMap即可实现该功能。UDAF: 输入多行,返回一行, aggregate(主要用于聚合功能,比如groupBy,count,sum), 这些是spark自带的聚合函数,但是复杂相对复杂。
Spark底层其实以CatalogFunction结构封装了一个函数,其中FunctionIdentifier描述了函数名字等基本信息,FunctionResource描述了文件类型(jar或者file)和文件路径;Spark的SessionCatalog提供了函数注册,删除,获取等一些列接口,Spark的Executor在接收到函数执行sql请求时,通过缓存的CatalogFunction信息,找到CatalogFunction中对应的jar地址以及ClassName, JVM动态加载jar,并通过ClassName反射执行对应的函数。

图1. CatalogFunction结构体
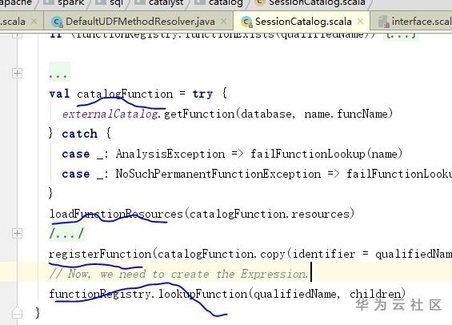
图2. 注册加载函数逻辑
Hive的HiveSessionCatalog是继承Spark的SessionCatalog,对Spark的基本功能做了一层装饰以适配Hive的基本功能,其中包括函数功能。HiveSimpleUDF对应UDF,HiveGenericUDF对应GenericUDF,HiveUDAFFunction对应AbstractGenericUDAFResolve以及UDAF,HiveGenericUDTF对应GenericUDTF
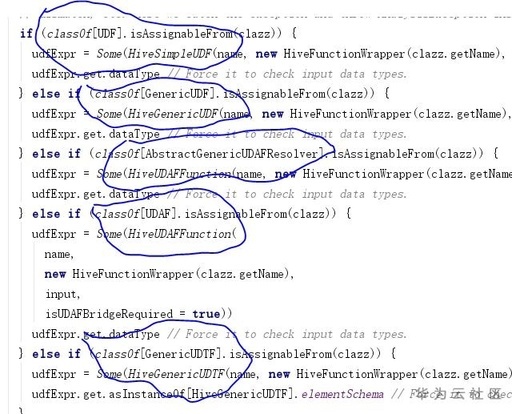
图3. Hive装饰spark函数逻辑
2. UDF
UDF是最常用的函数,使用起来相对比较简单,主要分为两类UDF:简单数据类型,继承UDF接口;复杂数据类型,如Map,List,Struct等数据类型,继承GenericUDF接口。
简单类型实现UDF时,可自定义若干个名字evaluate为的方法,参数和返回类型根据需要自己设置。因为UDF接口默认使用DefaultUDFMethodResolver去方法解析器获取方法,解析器是根据用户输入参数和写死的名字evaluate去反射寻找方法元数据。当然用户也可以自定义解析器解析方法。

图4. 自定义UDF简单示例
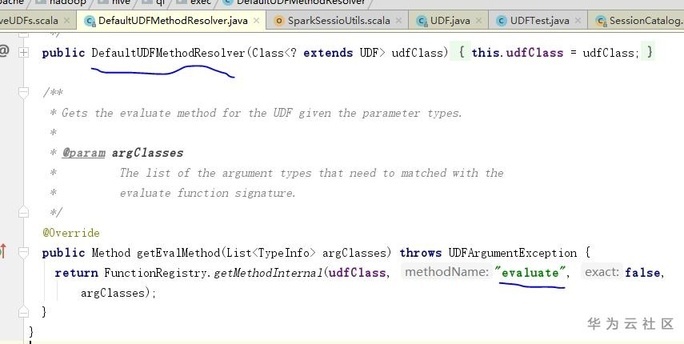
图5.默认UDF方法解析器
3. UDAF
UDAF是聚合函数,目前实现方式主要有三种:实现UDAF接口,比较老的简答实现方式,目前已经被废弃;实现UserDefinedAggregateFunction,目前使用比较普遍方式,按阶段实现接口聚集数据;实现AbstractGenericUDAFResolver,实现相对UserDefinedAggregateFunction方式稍微复杂点,还需要实现一个计算器Evaluator(如通用计算器GenericUDAFEvaluator),UDAF的逻辑处理主要发生在Evaluator。
UserDefinedAggregateFunction定义输入输出数据结构,实现初始化缓冲区(initialize),聚合单条数据(update),聚合缓存区(merge)以及计算最终结果(evaluate)。
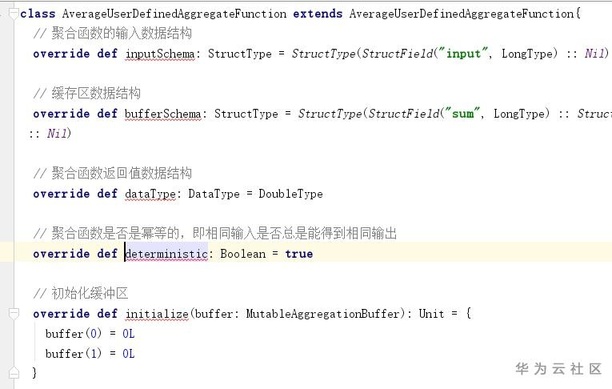

图6.自定义UDAF简单示例
4. UDTF
UDTF简单粗暴的理解是一行生成多行的自动函数,可以生成多行多列,又被称为表生成函数。目前实现方式是实现GenericUDTF接口,实现2个接口,initialize接口参数校验,列的定义,process接口接受一行数据,切割数据。


图7.自定义UDTF简单示例
案例解析丨 Spark Hive 自定义函数应用的更多相关文章
- hive -- 自定义函数和Transform
hive -- 自定义函数和Transform UDF操作单行数据, UDAF:聚合函数,接受多行数据,并产生一个输出数据行 UDTF:操作单个数据 使用udf方法: 第一种: add jar xxx ...
- Hive自定义函数的学习笔记(1)
前言: hive本身提供了丰富的函数集, 有普通函数(求平方sqrt), 聚合函数(求和sum), 以及表生成函数(explode, json_tuple)等等. 但不是所有的业务需求都能涉及和覆盖到 ...
- hive自定义函数(UDF)
首先什么是UDF,UDF的全称为user-defined function,用户定义函数,为什么有它的存在呢?有的时候 你要写的查询无法轻松地使用Hive提供的内置函数来表示,通过写UDF,Hive就 ...
- hive自定义函数学习
1介绍 Hive自定义函数包括三种UDF.UDAF.UDTF UDF(User-Defined-Function) 一进一出 UDAF(User- Defined Aggregation Funcat ...
- hive自定义函数UDF UDTF UDAF
Hive 自定义函数 UDF UDTF UDAF 1.UDF:用户定义(普通)函数,只对单行数值产生作用: UDF只能实现一进一出的操作. 定义udf 计算两个数最小值 public class Mi ...
- Spark SQL 自定义函数类型
Spark SQL 自定义函数类型 一.spark读取数据 二.自定义函数结构 三.附上长长的各种pom 一.spark读取数据 前段时间一直在研究GeoMesa下的Spark JTS,Spark J ...
- Hive 自定义函数(转)
Hive是一种构建在Hadoop上的数据仓库,Hive把SQL查询转换为一系列在Hadoop集群中运行的MapReduce作业,是MapReduce更高层次的抽象,不用编写具体的MapReduce方法 ...
- Hive 自定义函数
hive 支持自定义UDF,UDTF,UDAF函数 以自定义UDF为例: 使用一个名为evaluate的方法 package com.hive.custom; import org.apache.ha ...
- Hive 自定义函数 UDF UDAF UDTF
1.UDF:用户定义(普通)函数,只对单行数值产生作用: 继承UDF类,添加方法 evaluate() /** * @function 自定义UDF统计最小值 * @author John * */ ...
- Hadoop之Hive自定义函数的陷阱
A left join B, 这个B会连到A. 如<A1,B>, <A2,B>,在处理第一条记录的时候将B.clear(),则第二条记录的B是[]空的这是自定义UDF函数必须注 ...
随机推荐
- py2neo函数merge参数报错
代码 a1 = Node("house", name='303') g.merge(a1) 执行报错 Primary label and primary key are requi ...
- 理解maven命令package、install、deploy的联系与区别(转)
https://blog.csdn.net/zhaojianting/article/details/80324533 我们在用maven构建java项目时,最常用的打包命令有mvn package. ...
- RLHF · PBRL | RUNE:鼓励 agent 探索 reward model 更不确定的 (s,a)
论文题目: Reward uncertainty for exploration in preference-based reinforcement learning,是 ICLR 2022 的文章, ...
- 龙芯发布 .NET 8 SDK 8.0.100-rc2 LoongArch64
随着.NET 8的发布的临近,国内的社区朋友们也很关心龙芯.NET 团队对于Loongarch .NET 8的发布时间,目前从龙芯.NET编译器团队的可靠信息,Loongarch .NET 8的发布会 ...
- 【Servlet】两种配置
web.xml中Servlet的注解 <servlet> <!-- servlet的内部名称,⾃定义 --> <servlet-name>类名</servle ...
- maven 配置(cmd 黑窗口执行 mvn 时默认的 settings 文件和 idea maven 相关配置)
写在前面: 本文章用于记录博主平时遇到的问题,步骤略粗糙,目的在于记录一边后续博主自己查找,如果能帮助到其他人更好.文章中用到的链接均为自行引入,侵删,谢谢(2I2Rc*@JY8) 问题说明:在一次使 ...
- ConcurrentModificationException日志关键字报警引发的思考
本文将记录和分析日志中的ConcurrentModificationException关键字报警,还有一些我的思考,希望对大家有帮助. 一.背景 近期,在日常的日志关键字报警分析时,发现我负责的一个电 ...
- npm install 报-4048错误
报错原因: 有缓存 权限不够 有三种解决方法: 第一种:找到.npmrc文件并删除 在 C:\Users\自己用户的文件夹\ 下找到 .npmrc 文件并删除 注意:这个文件是隐藏的,需要显示隐藏才能 ...
- 文心一言 VS 讯飞星火 VS chatgpt (156)-- 算法导论12.3 3题
三.用go语言,对于给定的 n 个数的集合,可以通过先构造包含这些数据的一棵二叉搜索树(反复使用TREE-INSERT 逐个插入这些数),然后按中序遍历输出这些数的方法,来对它们排序.这个排序算法的最 ...
- AI浪潮下,大模型如何在音视频领域运用与实践?
视频云大模型算法「方法论」. 刘国栋|演讲者 在AI技术发展如火如荼的当下,大模型的运用与实践在各行各业以千姿百态的形式展开.音视频技术在多场景.多行业的应用中,对于智能化和效果性能的体验优化有较为极 ...