es从线上库导出数据并导入开发环境
背景
来了个需求,需要从某个线上es库查询一些数据出来并进行大屏展示。问需求方有没有开发环境的es库,答:没有,说要不直连他们的线上库。
后面想想也行吧,业务方都这么说了,结果开网络的流程被打回了,理由是网络隔离。
于是,只能采用从线上es库导出文件,然后在开发环境原样搭建这么一个es库并导入的办法。
了解到线上es库,版本是5.4.3,准备在开发环境恢复的那个索引的数据量大概是有20来个g。
我们是使用elasticdump来进行数据导入导出的,数据量小的时候用这个还是可以,但20 来个g这种,导入的过程还是有一些坑的,当时一开始没加一些参数,搞了一晚上都没弄完,后面研究了下,速度才快了,所以简单记录下。
开发环境es搭建
简单搭建
先找到了官方的5.4.3版本的文档。
https://www.elastic.co/guide/en/elasticsearch/reference/5.4/getting-started.html
首先是搭建,参考官方:https://www.elastic.co/guide/en/elasticsearch/reference/5.4/zip-targz.html
我是用tar包这种方式:
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.4.3.tar.gz
sha1sum elasticsearch-5.4.3.tar.gz
tar -xzf elasticsearch-5.4.3.tar.gz
cd elasticsearch-5.4.3/
./bin/elasticsearch
结果启动报错:
[root@VM-0-6-centos elasticsearch-5.4.3]# ./bin/elasticsearch
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
网上查了下,把内存改了下,我的云主机内存小,大家看着改吧:
[root@VM-0-6-centos elasticsearch-5.4.3]# vim config/jvm.options
-Xms256m
-Xmx256m
再启动,再报错:
Caused by: java.lang.RuntimeException: can not run elasticsearch as root
创建个用户、用户组吧:
// --先看看有没有es的相关用户存在
cat /etc/passwd
groupadd elasticsearch
useradd elasticsearch -g elasticsearch
chown -R elasticsearch:elasticsearch /opt/upload/elasticsearch-5.4.3
然后可以单开个shell
su elasticsearch
cd /opt/upload/elasticsearch-5.4.3
bin/elasticsearch
这样就前台启动起来了。默认的日志就在es安装目录下:
/opt/upload/elasticsearch-5.4.3/logs/elasticsearch.log
curl -X GET "localhost:9200/?pretty"
后台运行:
后台运行并记录pid到pid file:
./bin/elasticsearch -d -p pid
停止:
kill `cat pid`
关于配置
网上很多安装教程会涉及把这两个配置相关的目录,改成es用户,如这种:
chown elasticsearch:elasticsearch -R /var/log/elasticsearch
但这个路径还是要根据实际来,这个path.logs/path.data在config/elasticsearch.yml 中配置,我们这里没配置,所以就在安装目录下,所以不需要单独去chown修改权限。
除了这个之外,还有很多配置项,开发环境可以无所谓,线上还是得每个参数好好斟酌。
这些参数配置的文档:
https://www.elastic.co/guide/en/elasticsearch/reference/5.4/important-settings.html#path-settings
还有很多重要的配置:
https://www.elastic.co/guide/en/elasticsearch/reference/5.4/setting-system-settings.html
样例数据导入
在看官网时,发现还有样例数据辅助学习,试了下,还是不错的。
原地址已经404了,在网上找了下:
https://blog.csdn.net/qq_20667511/article/details/109614359
https://github.com/elastic/elasticsearch/blob/7.5/docs/src/test/resources/accounts.json
https://github.com/elastic/elasticsearch/issues/88146
数据导入:
https://www.elastic.co/guide/en/elasticsearch/reference/5.4/gs-exploring-data.html
curl -H "Content-Type: application/json" -XPOST 'localhost:9200/bank/account/_bulk?pretty&refresh' --data-binary "@accounts.json"
curl 'localhost:9200/_cat/indices?v'
esdump导入数据
elasticsearch-dump安装
https://github.com/elasticsearch-dump/elasticsearch-dump
这个是用js写的,我这边是先在本地虚拟机用npm安装这个module(有网络),然后把这个模块拷贝到内网es服务器上去跑导入本地文件的;当然它也支持从一个es/文件导出,直接导入到另一个es/文件。
反正就是目标和源都可以是文件和es服务。
npm install elasticdump -g
or 安装指定版本的module
npm i elasticdump@6.104.1
https://www.npmjs.com/package/elasticdump/v/6.104.1?activeTab=readme
找到elasticdump这个node,打tar包,拷贝到无网络的服务器上
ll /root/upload/node-v12.3.0-linux-x64/lib/node_modules
tar -cvf elasticdump.tar elasticdump
目标服务器上解压:
/root/upload/node-v16.20.2-linux-x64/lib/node_modules
此时,执行elasticdump不生效,找不到,所以要在path下建立软连接:
cd /root/upload/node-v16.20.2-linux-x64/bin
ln -s ../lib/node_modules/elasticdump/bin/elasticdump elasticdump
ln -s ../lib/node_modules/elasticdump/bin/multielasticdump multielasticdump
导入(慢)
我是从文件导入新搭建的es服务。根据导出语句写导入语句即可:
注意,数据量大的时候,下面语句比较慢,看完全文再操作。
elasticdump --input=/root/upload/root/esbackup/20231204/base20231204/common_mapping.json --output=http://localhost:9200/base20231204 --type=mapping
elasticdump --input=/root/upload/root/esbackup/20231204/base20231204/common_data.json --output=http://localhost:9200/base20231204 --type=data
elasticdump --input=/root/upload/root/esbackup/20231204/base20231204/data_mapping.json --output=http://localhost:9200/data --type=mapping
后台导入:
nohup elasticdump --input=/root/upload/root/esbackup/20231204/base20231204/data_data.json --output=http://localhost:9200/data --type=data 2>&1 &
导入(快)
后面的语句:
nohup elasticdump --input=/root/upload/root/esbackup/20231204/history20231204/common_data.json --output=http://localhost:9200/data20231204 --type=data --noRefresh --limit 10000 --support-big-int --fileSize 1gb 2>&1 &
主要是增加了--noRefresh,这个才是主要的。
参数的解释:
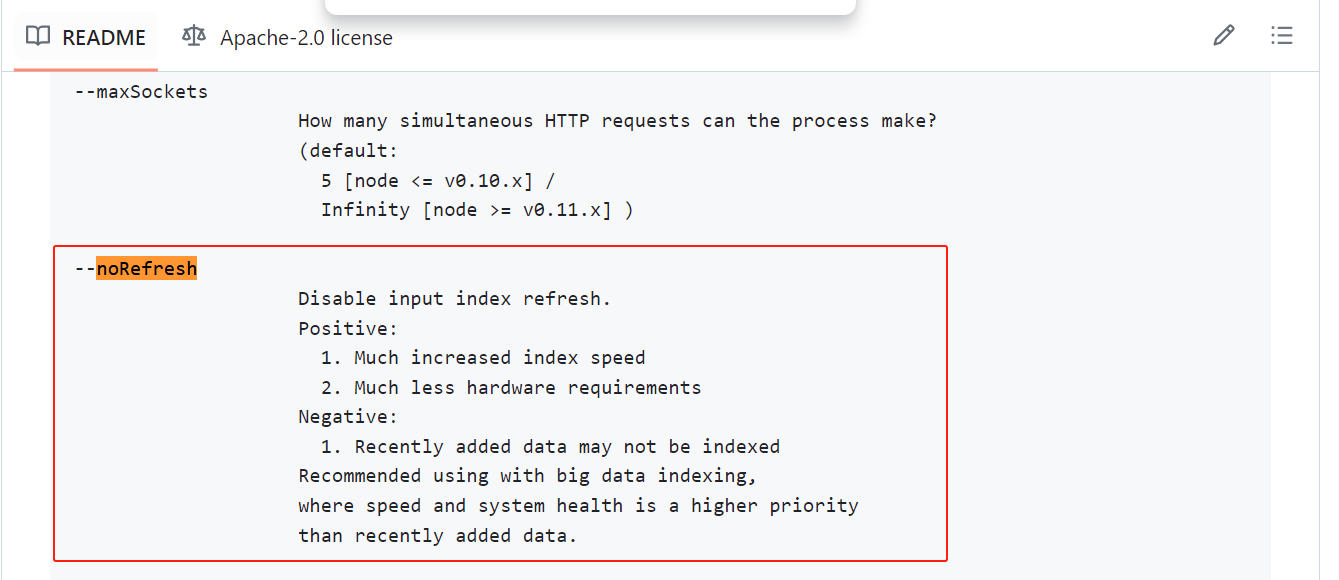
开了这个选项后,导入快多了,之前是一晚上都搞不完。
kibana
顺便记录下kibana的安装。
https://www.elastic.co/guide/en/kibana/5.4/targz.html
wget https://artifacts.elastic.co/downloads/kibana/kibana-5.4.3-linux-x86_64.tar.gz
sha1sum kibana-5.4.3-linux-x86_64.tar.gz
tar -xzf kibana-5.4.3-linux-x86_64.tar.gz
cd kibana/
启动前改下配置:
cd config/
vim kibana.yml
elasticsearch.url: "http://localhost:9200"
server.host: 0.0.0.0
其他
本来一开始规划是后端对接es,给前端提供接口;后来计划是前端直接对接es(前端为了避免跨域,还是通过后端nginx转发es请求到es服务器)。
当时本来还研究了下java client的版本兼容,后面就没弄了。
https://www.elastic.co/guide/en/elasticsearch/client/index.html
客户端这块,Java Client只支持7.0后版本的服务端;
Java Rest Client这块,5.6版本的高级客户端,不支持es服务端5.4.3版本,所以,如果要用的话,都只能使用5.4或5.5或5.6的低级客户端。

https://www.elastic.co/guide/en/elasticsearch/client/java-rest/5.6/java-rest-high-compatibility.html
参考链接
https://www.elastic.co/guide/en/elastic-stack/5.4/index.html
https://www.elastic.co/guide/en/elastic-stack/5.4/elastic-stack.html
https://www.elastic.co/guide/en/elasticsearch/reference/5.4/getting-started.html
https://www.elastic.co/guide/en/kibana/5.4/introduction.html
es从线上库导出数据并导入开发环境的更多相关文章
- sqlloader导出数据和导入数据
分类: Oracle 忙了一天终于把sqlloader导出数据和导入数据弄清楚了,累死俺了... 这个总结主要分为三个大部分,第一部分(实例,主要分两步),第二部分(参数小总结),第三部分(完全参数总 ...
- Mac上利用VScode配置c/c++开发环境
Mac上利用VScode配置c/c++开发环境 哭辽,Typora里面最好不要插入表情,不然保存会闪退 首先你要有一个vscode 在扩展里面下载c/c++ 第一步 ⬆+com+p 打开命令模式:选择 ...
- 如何在微软Windows平台上打造出你的Linux开发环境(转载)
如何在微软Windows平台上打造出你的Linux开发环境 投递人 itwriter 发布于 2013-12-10 11:18 评论(1) 有348人阅读 原文链接 [收藏] « » 英文原文: ...
- git 先建立本地分支,再传给线上库
cd 进入本地一个文件夹 git clone 文件下来 进入右下角 develop分支(remote braches) 新建分支 (check out) a 把新分支 a 传上线上 新建一个对立 ...
- SQL Server 2008 导出数据与导入数据任务介绍
一. 实例数据库介绍 源数据库Test_Other_DB:存在tb_Class,tb_Student,tb_TestTable三张表. 目标数据库TestDB_Output:空库,不含任何表. 二. ...
- 从Oracle导出数据并导入到Hive
1.配置源和目标的数据连接 源(oracle): 目标(Hive 2.1.1),需要事先将hive的驱动程序导入HHDI的lib目录中. Hive2.1.1需要的jar包如下:可根据自身情况更换had ...
- oracle 导出数据和导入数据
导出数据 exp zl_gj/zlkj@gqxt grants=y tables=(zl_gj.ckgj,zl_gj.gjlx,zl_gj.rkgj) file=c:\gj.dmp log=c:\g ...
- 在64位的ubuntu 14.04 上开展32位Qt 程序开发环境配置(pro文件中增加 QMAKE_CXXFLAGS += -m32 命令)
为了能中一个系统上开发64或32位C++程序,费了些周折,现在终于能够开始干过了.在此记录此时针对Q5.4版本的32位开发环境配置过程. 1. 下载Qt 5.4 的32位版本,进行安装,安装过程中会发 ...
- Windows7上搭建Cocos2d-x 3.1.1开发环境
前言 现在,越来越多的公司采用Cocos2d-x 3.0来开发游戏了,但是现在这样的文章并不多,所以打算写一系列来帮助初学者快速掌握Cocos2d-x 3.0.首先就从开发环境的大家说起吧. 开发工具 ...
- 【原创干货】大数据Hadoop/Spark开发环境搭建
已经自学了好几个月的大数据了,第一个月里自己通过看书.看视频.网上查资料也把hadoop(1.x.2.x).spark单机.伪分布式.集群都部署了一遍,但经历短暂的兴奋后,还是觉得不得门而入. 只有深 ...
随机推荐
- Linux 下运行.NET 6 7 8 程序遇到的两个问题
一. /lib64/libstdc++.so.6: version `GLIBCXX_3.4.21' not found 的解决办法 1. 下载 libstdc++.so.6.0.21 文件 注意区分 ...
- 数据探索之道:查询Web API数据中的JSON字符串列
前言 在当今数据驱动的时代,对数据进行探索和分析变得愈发关键.Web API作为广泛应用的数据源,提供了丰富的信息和资源.然而,面对包含JSON字符串列的Web API数据时,我们常常遇到一个挑战:如 ...
- Java 设计模式课堂作业记录
第二章 P25,有人将面向对象设计原则简单归类为 3 条:①封装变化点: ②对接口进行编程: ③多使用组合,而不是继承.请查阅相关资料谈谈理解 3.7 : 该三大原则 应该算 是OO的基础,很多OO设 ...
- (组合游戏)SG函数与SG定理详解
有一段时间没记录知识类的博客了,这篇博客就说一下SG函数和SG定理吧 SG函数是用于解决博弈论中公平组合游戏(Impartial Combinatorial Games,ICG)问题的一种方法. 什么 ...
- 传智黑马git学习笔记
- uni-app实现扫码签到
1 uni.scanCode({ 2 success: res => { 3 this.$http({ 4 url: '/checkin/scanSign', 5 data: { 6 codeI ...
- P2241
这么多年不写代码,竟然忘了longlong这茬,我半天没想明白错在哪里,过了好久才反应过来.浪费不少时间,真的得记住longlong 啊.... Code #include <iostream& ...
- CSS3之transition
随着css3不断地发展,越来越多的页面特效可以被实现. 例如当我们鼠标悬浮在某个tab上的时候,给它以1s的渐进变化增加一个背景颜色.渐进的变化可以让css样式变化得不那么突兀,也显得交互更加柔和. ...
- Redis内存问题的学习之一
Redis内存问题的学习之一 背景 前几天帮同事看redis的问题 发现info memory 显示 60GB 但是实际上 save出来的dump文件只有 800M 然后导入到其他的redis之后, ...
- SQLServer 执行计划的简单学习和与类型转换的影响
SQLServer 执行计划的简单学习和与类型转换的影响 背景 最近一直在看SQLServer数据库 索引.存储.还有profiler的使用 并且用到了 deadlock graph 但是感觉还是不太 ...