Sparse稀疏检索介绍与实践
Sparse稀疏检索介绍
在处理大规模文本数据时,我们经常会遇到一些挑战,比如如何有效地表示和检索文档,当前主要有两个主要方法,传统的文本BM25检索,以及将文档映射到向量空间的向量检索。
BM25效果是有上限的,但是文本检索在一些场景仍具备较好的鲁棒性和可解释性,因此不可或缺,那么在NN模型一统天下的今天,是否能用NN模型来增强文本检索呢,答案是有的,也就是我们今天要说的sparse 稀疏检索。
传统的BM25文本检索其实就是典型的sparse稀疏检索,在BM25检索算法中,向量维度为整个词表,但是其中大部分为0,只有出现的关键词或子词(tokens)有值,其余的值都设为零。这种表示方法不仅节省了存储空间,而且提高了检索效率。
向量的形式, 大概类似:
{
'19828': 0.2085,
'3508': 0.2374,
'7919': 0.2544,
'43': 0.0897,
'6': 0.0967,
'79299': 0.3079
}
key是term的编号,value是NN模型计算出来的权重。
稀疏向量与传统方法的比较
当前流行的sparse检索,大概是通过transformer模型,为doc中的term计算weight,这样与传统的BM25等基于频率的方法相比,sparse向量可以利用神经网络的力量,提高了检索的准确性和效率。BM25虽然能够计算文档的相关性,但它无法理解词语的含义或上下文的重要性。而稀疏向量则能够通过神经网络捕捉到这些细微的差别。
稀疏向量的优势
- 计算效率:稀疏向量在处理包含零元素的操作时,通常比密集向量更高效。
- 信息密度:稀疏向量专注于关键特征,而不是捕捉所有细微的关系,这使得它们在文本搜索等应用中更为高效。
- 领域适应性:稀疏向量在处理专业术语或罕见关键词时表现出色,例如在医疗领域,许多专业术语不会出现在通用词汇表中,稀疏向量能够更好地捕捉这些术语的细微差别。
稀疏向量举例
SPLADE 是一款开源的transformer模型,提供sparse向量生成,下面是效果对比,可以看到sparse介于BM25和dense之间,比BM25效果好。
| Model | MRR@10 (MS MARCO Dev) | Type |
|---|---|---|
| BM25 | 0.184 | Sparse |
| TCT-ColBERT | 0.359 | Dense |
| doc2query-T5 link | 0.277 | Sparse |
| SPLADE | 0.322 | Sparse |
| SPLADE-max | 0.340 | Sparse |
| SPLADE-doc | 0.322 | Sparse |
| DistilSPLADE-max | 0.368 | Sparse |
Sparse稀疏检索实践
模型介绍
国内的开源模型中,BAAI的BGE-M3提供sparse向量向量生成能力,我们用这个来进行实践。
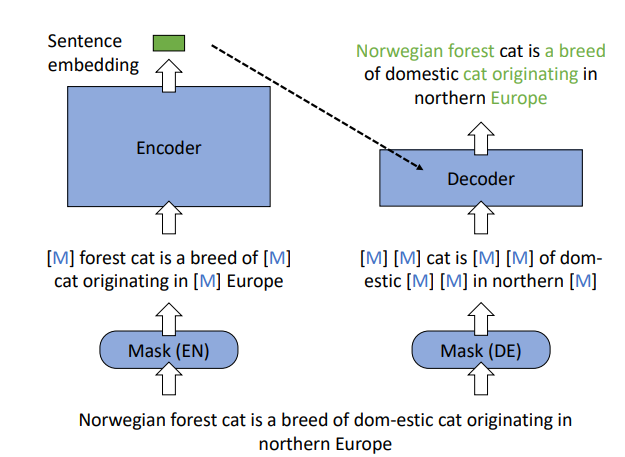
BGE是通过RetroMAE的预训练方式训练的类似bert的预训练模型。
常规的Bert预训练采用了将输入文本随机Mask再输出完整文本这种自监督式的任务,RetroMAE采用一种巧妙的方式提高了Embedding的表征能力,具体操作是:将低掩码率的的文本A输入到Encoder种得到Embedding向量,将该Embedding向量与高掩码率的文本A输入到浅层的Decoder向量中,输出完整文本。这种预训练方式迫使Encoder生成强大的Embedding向量,在表征模型中提升效果显著。
向量生成
先安装
!pip install -U FlagEmbedding
然后引入模型
from FlagEmbedding import BGEM3FlagModel
model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True)
编写一个函数用于计算embedding:
def embed_with_progress(model, docs, batch_size):
batch_count = int(len(docs) / batch_size) + 1
print("start embedding docs", batch_count)
query_embeddings = []
for i in tqdm(range(batch_count), desc="Embedding...", unit="batch"):
start = i * batch_size
end = min(len(docs), (i + 1) * batch_size)
if end <= start:
break
output = model.encode(docs[start:end], return_dense=False, return_sparse=True, return_colbert_vecs=False)
query_embeddings.extend(output['lexical_weights'])
return query_embeddings
然后分别计算query和doc的:
query_embeddings = embed_with_progress(model, test_sets.queries, batch_size)
doc_embeddings = embed_with_progress(model, test_sets.docs, batch_size)
然后是计算query和doc的分数,model.compute_lexical_matching_score(交集的权重相乘,然后累加),注意下面的代码是query和每个doc都计算了,计算量会比较大,在工程实践中需要用类似向量索引的方案(当前qdrant、milvus等都提供sparse检索支持)
# 检索topk
recall_results = []
import numpy as np
for i in tqdm(range(len(test_sets.query_ids)), desc="recall...", unit="query"):
query_embeding = query_embeddings[i]
query_id = test_sets.query_ids[i]
if query_id not in test_sets.relevant_docs:
continue
socres = [model.compute_lexical_matching_score(query_embeding, doc_embedding) for doc_embedding in doc_embeddings]
topk_doc_ids = [test_sets.doc_ids[i] for i in np.argsort(socres)[-20:][::-1]]
recall_results.append(json.dumps({"query": test_sets.queries[i], "topk_doc_ids": topk_doc_ids, "marked_doc_ids": list(test_sets.relevant_docs[query_id].keys())}))
# recall_results 写入到文件
with open("recall_results.txt", "w", encoding="utf-8") as f:
f.write("\n".join(recall_results))
最后,基于测试集,我们可以计算召回率:
import json
# 读取 JSON line 文件
topk_doc_ids_list = []
marked_doc_ids_list = []
with open("recall_results.txt", "r") as file:
for line in file:
data = json.loads(line)
topk_doc_ids_list.append(data["topk_doc_ids"])
marked_doc_ids_list.append(data["marked_doc_ids"])
# 计算 recall@k
def recall_at_k(k):
recalls = []
for topk_doc_ids, marked_doc_ids in zip(topk_doc_ids_list, marked_doc_ids_list):
# 提取前 k 个召回结果
topk = set(topk_doc_ids[:k])
# 计算交集
intersection = topk.intersection(set(marked_doc_ids))
# 计算 recall
recall = len(intersection) / min(len(marked_doc_ids), k)
recalls.append(recall)
# 计算平均 recall
average_recall = sum(recalls) / len(recalls)
return average_recall
# 计算 recall@5, 10, 20
recall_at_5 = recall_at_k(5)
recall_at_10 = recall_at_k(10)
recall_at_20 = recall_at_k(20)
print("Recall@5:", recall_at_5)
print("Recall@10:", recall_at_10)
print("Recall@20:", recall_at_20)
在测试集中,测试结果:
Recall@5: 0.7350086355785777
Recall@10: 0.8035261945883735
Recall@20: 0.8926130345462158
在这个测试集上,比BM25测试出来的结果要更好,但是仅凭这个尚不能否定BM25,需要综合看各自的覆盖度,综合考虑成本与效果。
参考
- Sparse Vectors in Qdrant: Pure Vector-based Hybrid Search https://qdrant.tech/articles/sparse-vectors/
- BGE(BAAI General Embedding)解读 https://zhuanlan.zhihu.com/p/690856333
Sparse稀疏检索介绍与实践的更多相关文章
- 关于Axure RP软件的介绍——软件工程实践第二次个人作业
关于Axure RP软件的介绍——软件工程实践第二次个人作业 Axure RP是一个非常专业的快速原型设计的一个工具,客户提出需求,然后根据需求定义和规格.设计功能和界面的专家能够快速创建应用软件或W ...
- RabbitMQ系列(三)RabbitMQ交换器Exchange介绍与实践
RabbitMQ交换器Exchange介绍与实践 RabbitMQ系列文章 RabbitMQ在Ubuntu上的环境搭建 深入了解RabbitMQ工作原理及简单使用 RabbitMQ交换器Exchang ...
- RabbitMQ交换器Exchange介绍与实践
RabbitMQ交换器Exchange介绍与实践 RabbitMQ系列文章 RabbitMQ在Ubuntu上的环境搭建 深入了解RabbitMQ工作原理及简单使用 RabbitMQ交换器Exchang ...
- CNN网络介绍与实践:王者荣耀英雄图片识别
欢迎大家前往腾讯云社区,获取更多腾讯海量技术实践干货哦~ 作者介绍:高成才,腾讯Android开发工程师,2016.4月校招加入腾讯,主要负责企鹅电竞推流SDK.企鹅电竞APP的功能开发和技术优化工作 ...
- sparse 稀疏函数的用法2
sparse函数 功能:Create sparse matrix-创建稀疏矩阵 用法1:S=sparse(X)——将矩阵X转化为稀疏矩阵的形式,即矩阵X中任何零元素去除,非零元素及其下标(索引)组成矩 ...
- 【原创】Kuberneters-HelmV3.3.1入门介绍及实践
一.为什么需要Helm? Kubernetes目前已成为容器编排的事实标准,随着传统架构向微服务容器化架构的转变,从一个巨大的单体的应用切分为多个微服务,每个微服务可独立部署和扩展,实现了敏捷开发和快 ...
- 高并发应用场景下的负载均衡与故障转移实践,AgileEAS.NET SOA 负载均衡介绍与实践
一.前言 AgileEAS.NET SOA 中间件平台是一款基于基于敏捷并行开发思想和Microsoft .Net构件(组件)开发技术而构建的一个快速开发应用平台.用于帮助中小型软件企业建立一条适合市 ...
- SVN 分支及合并的介绍和实践---命令行
写在前面 一些相关的概念和原理 进行分支开发的最佳实践 合并的分类 在 Eclipse 中进行合并操作 相关资源 写在前面 本文是由演讲整理而来的,介绍了 SVN 分支与合并的概念.流程和一些实际操作 ...
- WPF: 只读依赖属性的介绍与实践
在设计与开发 WPF 自定义控件时,我们常常为会控件添加一些依赖属性以便于绑定或动画等.事实上,除了能够添加正常的依赖属性外,我们还可以为控件添加只读依赖属性(以下统称"只读属性" ...
- sparse 稀疏函数的用法
sparse函数 功能:创建稀疏矩阵 用法1:S=sparse(X)—将矩阵X转化为稀疏矩阵的形式,即矩阵X中任何零元素去除,非零元素及其下标(索引)组成矩阵S. 如果X本身是稀疏的,sparse(X ...
随机推荐
- Python项目维护不了?可能是测试没到位。Django的单元测试和集成测试初探
前言 好久没搞 Django 了,最近维护一个我之前用 Django 开发的项目竟然有亲切的感觉 测试,在以前确实是经常被忽略的话题,特别是对于 Python Web 这种快速开发框架,怎么敏捷怎么来 ...
- Codeforces Round 920 (Div. 3)(A~F)
目录 A B C D E F A 按题意模拟即可 #include <bits/stdc++.h> #define int long long #define rep(i,a,b) for ...
- el-select封装(单选框、多选框、全选功能)
先看看设计图: 网上找了一溜,都是扯淡,样式也没个 自己动手吧,先把样式搞定 popper-class="xx-option" 所有单选框都用 :after和:before类 + ...
- WPF入门教程系列目录
WPF入门教程系列一--基础 WPF入门教程系列二--Application介绍 WPF入门教程系列三--Application介绍(续) WPF入门教程系列四--Dispatcher介绍 WPF入门 ...
- C++ Qt开发:QNetworkAccessManager网络接口组件
Qt 是一个跨平台C++图形界面开发库,利用Qt可以快速开发跨平台窗体应用程序,在Qt中我们可以通过拖拽的方式将不同组件放到指定的位置,实现图形化开发极大的方便了开发效率,本章将重点介绍如何运用QNe ...
- java中webSocket发送图片文件数据非常慢
一.问题由来 目前在开发的这个小程序中有一个功能需要和Unity客户端进行互动操作,互动的大致流程为在微信小程序中点击一个操作,发送一个HTTP请求, Java后台收到这个请求后,会给Unity客户端 ...
- Multi-Runtime多运行时架构
概念 Multi-Runtime Multi-Runtime 是一种服务端架构思路,把应用里的所有中间件挪到 Sidecar 里,使得"业务运行时"和"技术运行时&quo ...
- Kotlin/Java 读取Jar文件里的指定文件
原文地址:Kotlin/Java 读取Jar文件里的指定文件 | Stars-One的杂货小窝 jar包本质上也是压缩文件,下面给出如何读取jar包里某个文件的源码: val jarFile = Ja ...
- ffmpeg播放器-音视频解码流程
目录 音视频介绍 音视频解码流程 FFmpeg解码的数据结构说明 AVFormatContext数据结构说明 AVInputFormat数据结构说明 AVStream数据结构说明 AVCodecCon ...
- 使用TS封装操作MongoDB数据库的工具方法
使用TS封装操作MongoDB数据库的工具方法 前言 在做毕业设计过程中采用了MongoDb存储应用的日志信息,总结了一些CRUD方法与大家分享一下,最终使用效果可跳转到业务调用示例这一小节查看 关于 ...