CNN --入门MNIST识别
Smiling & Weeping
---- 下次你撑伞低头看水洼,
就会想起我说雨是神的烟花。
简介:主要是看刘二大人的视频讲解:https://www.bilibili.com/video/BV1Y7411d7Ys/?spm_id_from=333.337.search-card.all.click
题目及提交链接:Digit Recognizer | Kaggle
深度学习入门的学习项目,使用CNN(Convolutional Nerual Network)
对于Basic CNN的理解:
- 分成两个部分:前一个部分叫做Feature Extraction,后一部分叫做Classification(其中Feature Extraction又可以分为Convolution,Subsampling等)
- 其中要求卷积核的通道数量与输入通道数量一致。这种卷积核的总数和输出通道数目的总数一致(详见链接PDF)
- 卷积(convolution)后,C(channels),W(width),H(height),其中padding和pooling(小技巧:若要卷积W,H不变,取整kernel_size/2)
- 卷积层:保存图像的空间信息
- 卷积层要求输入输出是四维张量(B,C,W,H),全连接层的输入输出都是二维张量(B,Input_feature)
- 卷积(线性变换),激活函数(非线性变换),池化;这个过程若干次后,view打平,进入全连接层
1 import torch
2 import torch.nn.functional as F
3 import torch.nn as nn
4 import torch.optim as optim
5 import torch.autograd as lr_scheduler
6 from torch.utils.data import DataLoader, Dataset
7 from torchvision import transforms
8 from torchvision.utils import make_grid
9 from torchvision import datasets
10 from torch.autograd import Variable
11 from sklearn.model_selection import train_test_split
12 import pandas as pd
13 import numpy as np
14 import matplotlib.pyplot as plt
15
16 batch_size = 64
17 transform = transforms.Compose([transforms.ToTensor()])
18 train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
19 train_loader = torch.utils.data.DataLoader(dataset=train_dataset, shuffle=True, batch_size=batch_size)
20 #同样的方式加载一下测试集
21 test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
22 test_loader = torch.utils.data.DataLoader(dataset=test_dataset, shuffle=False, batch_size=batch_size)
23
24 # 使用卷积神经网络进行图像特征提取
25 # (batch, 1, 28, 28) -> (batch, 10, 24, 24) -> 池化 (batch, 10, 12, 12) -> (batch, 20, 8, 8) -> (batch, 20 , 4, 4) -> (batch, 320) -> (batch, 10)
26 class Net(torch.nn.Module):
27 def __init__(self):
28 super(Net, self).__init__()
29 self.conv1 = torch.nn.Conv2d(1, 10, kernel_size = 5)
30 self.conv2 = torch.nn.Conv2d(10, 20, kernel_size = 5)
31 self.pooling = torch.nn.MaxPool2d(2)
32 self.fc = torch.nn.Linear(320, 10)
33
34 def forward(self, x):
35 # Flatten data from (n, 1, 28, 28) to (n, 784)
36 batch_size = x.size(0)
37 x = F.relu(self.pooling(self.conv1(x)))
38 x = F.relu(self.pooling(self.conv2(x)))
39 x = x.view(batch_size, -1) # Flatten
40 x = self.fc(x)
41 return x
42
43 model = Net()
44 # print(model)
45 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
46 model.to(device)
47 criterion = torch.nn.CrossEntropyLoss(size_average=True)
48 optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
49
50 def train(epoch):
51 running_loss = 0.0
52 for batch_idx, data in enumerate(train_loader, 0):
53 inputs, target = data
54 inputs, target = inputs.to(device), target.to(device)
55 optimizer.zero_grad()
56
57 # forward + backward + update
58 outputs = model(inputs)
59 # 计算真实值 和 测量值 之间的误差
60 loss = criterion(outputs, target)
61 loss.backward()
62 optimizer.step()
63
64 running_loss += loss.item()
65 if batch_idx % 300 == 299:
66 print('[%d, %5d] loss: %3f' % (epoch + 1, batch_idx+1, running_loss / 2000))
67 running_loss = 0.0
68
69 def test():
70 correct = 0
71 total = 0
72 with torch.no_grad():
73 for data in test_loader:
74 inputs, target = data
75 inputs, target = inputs.to(device), target.to(device)
76 outputs = model(inputs)
77 _, prediction = torch.max(outputs.data, dim=1)
78 total += target.size(0)
79 correct += (prediction == target).sum().item()
80 print('Accuracy on test set: %d %% [%d/%d]' % (100*correct / total, correct, total))
81 return correct/total
82
83 epoch_list = []
84 acc_list = []
85 for epoch in range(10):
86 train(epoch)
87 acc = test()
88 epoch_list.append(epoch)
89 acc_list.append(acc)
90
91 plt.plot(epoch_list, acc_list)
92 plt.ylabel("accuracy")
93 plt.xlabel("epoch")
94 plt.show()
95
96 class DatasetSubmissionMNIST(torch.utils.data.Dataset):
97 def __init__(self, file_path, transform=None):
98 self.data = pd.read_csv(file_path)
99 self.transform = transform
100
101 def __len__(self):
102 return len(self.data)
103
104 def __getitem__(self, index):
105 image = self.data.iloc[index].values.astype(np.uint8).reshape((28, 28, 1))
106
107
108 if self.transform is not None:
109 image = self.transform(image)
110
111 return image
112
113 transform = transforms.Compose([
114 transforms.ToPILImage(),
115 transforms.ToTensor(),
116 transforms.Normalize(mean=(0.5,), std=(0.5,))
117 ])
118
119 submissionset = DatasetSubmissionMNIST('/kaggle/input/digit-recognizer/test.csv', transform=transform)
120 submissionloader = torch.utils.data.DataLoader(submissionset, batch_size=batch_size, shuffle=False)
121
122 submission = [['ImageId', 'Label']]
123
124 with torch.no_grad():
125 model.eval()
126 image_id = 1
127
128 for images in submissionloader:
129 images = images.cuda()
130 log_ps = model(images)
131 ps = torch.exp(log_ps)
132 top_p, top_class = ps.topk(1, dim=1)
133
134 for prediction in top_class:
135 submission.append([image_id, prediction.item()])
136 image_id += 1
137
138 print(len(submission) - 1)
139 import csv
140
141 with open('submission.csv', 'w') as submissionFile:
142 writer = csv.writer(submissionFile)
143 writer.writerows(submission)
144
145 print('Submission Complete!')
146 # summission.to_csv('/kaggle/working/submission.csv', index=False)
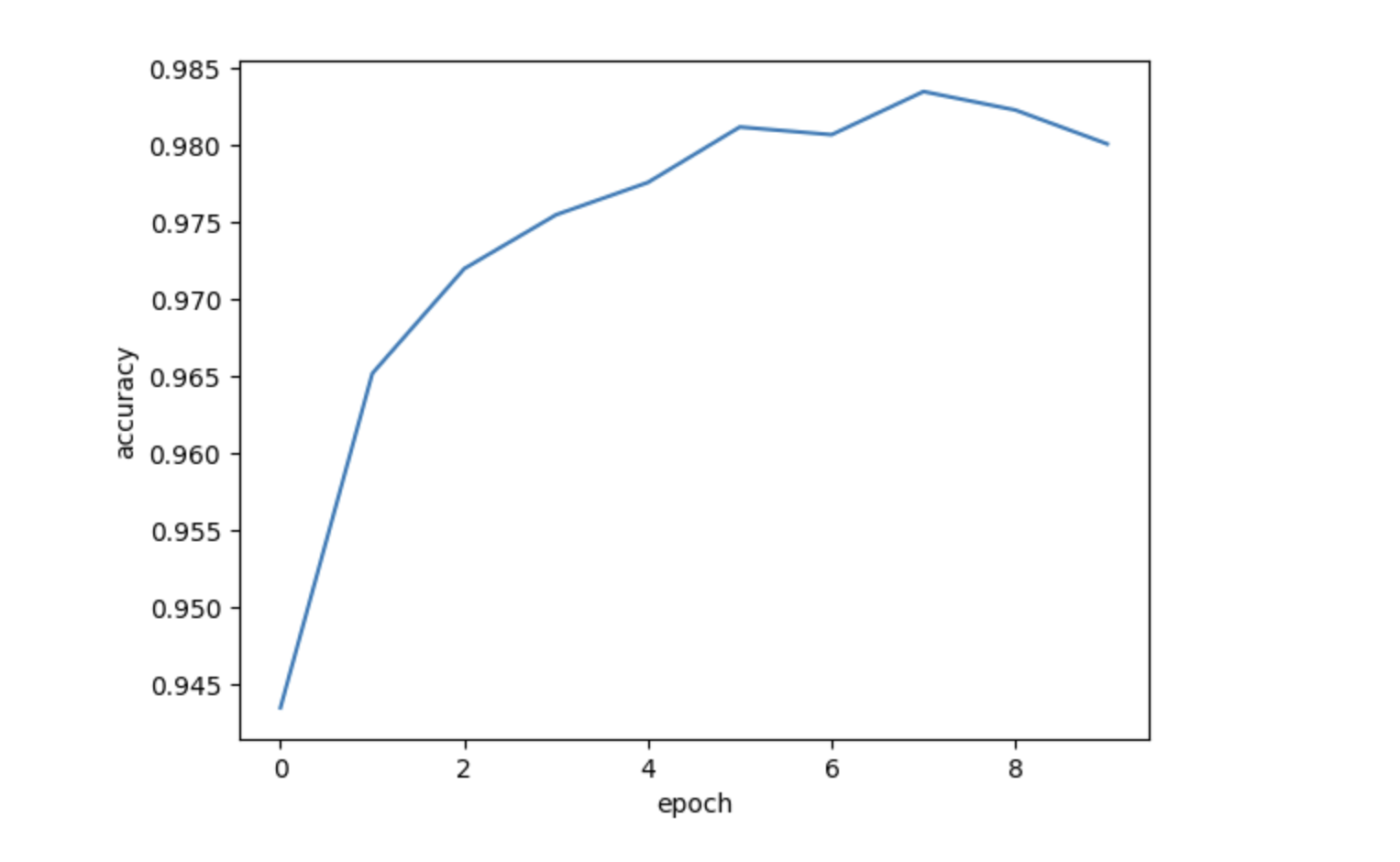
就效果来说,也就一般,后面的Advance CNN 会有更高的效率和准确性,大家可以敲一下代码放在自己的编译器上跑一下
对了,这是GPU版本,若用CPU,把所有的device删除就可以,--<-<-<@
文章到此结束,我们下次再见
一束光线,可能会摔碎
但仍旧光芒四射
CNN --入门MNIST识别的更多相关文章
- 使用tensorflow实现cnn进行mnist识别
第一个CNN代码,暂时对于CNN的BP还不熟悉.但是通过这个代码对于tensorflow的运行机制有了初步的理解 ''' softmax classifier for mnist created on ...
- NLP用CNN分类Mnist,提取出来的特征训练SVM及Keras的使用(demo)
用CNN分类Mnist http://www.bubuko.com/infodetail-777299.html /DeepLearning Tutorials/keras_usage 提取出来的特征 ...
- 用标准3层神经网络实现MNIST识别
一.MINIST数据集下载 1.https://pjreddie.com/projects/mnist-in-csv/ 此网站提供了mnist_train.csv和mnist_test.cs ...
- 利用CNN进行流量识别 本质上就是将流量视作一个图像
from:https://netsec2018.files.wordpress.com/2017/12/e6b7b1e5baa6e5ada6e4b9a0e59ca8e7bd91e7bb9ce5ae89 ...
- 机器学习: Tensor Flow +CNN 做笑脸识别
Tensor Flow 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库.节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数 ...
- 机器学习: Tensor Flow with CNN 做表情识别
我们利用 TensorFlow 构造 CNN 做表情识别,我们用的是FER-2013 这个数据库, 这个数据库一共有 35887 张人脸图像,这里只是做一个简单到仿真实验,为了计算方便,我们用其中到 ...
- 机器不学习:CNN入门讲解-为什么要有最后一层全连接
哈哈哈,又到了讲段子的时间 准备好了吗? 今天要说的是CNN最后一层了,CNN入门就要讲完啦..... 先来一段官方的语言介绍全连接层(Fully Connected Layer) 全连接层常简称为 ...
- CNN入门讲解-为什么要有最后一层全连接?
原文地址:https://baijiahao.baidu.com/s?id=1590121601889191549&wfr=spider&for=pc 今天要说的是CNN最后一层了,C ...
- halcon视觉入门钢珠识别
halcon视觉入门钢珠识别 经过入门篇,我们有了基础的视觉识别知识.现在加以应用. 有如下图片: 我们需要识别图片中比较明亮的中间区域,有黑色的钢珠,我们需要知道他的位置和面积. 分析如何识别 编写 ...
- Halcon视觉入门芯片识别
Halcon视觉入门芯片识别 需求 有如下图的一个摆盘,摆盘的方格中摆放芯片,一个格子中只放一个,我们需要知道每个方格中是否有芯片去指导我们将芯片放到空的方格中. 分析 通过图片分析得出 我们感兴趣的 ...
随机推荐
- 如何进行基于Anolis OS的企业级Java应用规模化实践?|龙蜥技术
简介:提供了7×24小时的专属钉钉或者电话支持,响应时间保证到在业务不可用情况下10分钟响应,业务一般的问题在一小时可以获得响应,主要城市可以两小时内得到到达现场的服务. 本文作者郁磊,是Java语 ...
- [GPT] ./ssh/known_hosts 是什么
~/.ssh/known_hosts 是一个SSH客户端用来存储已知的远程主机的公钥的文件,这些公钥用于验证连接到远程主机时它们是否为真实可信的主机. 当你首次通过SSH连接到一个新的远程主机时, ...
- dotnet win32 使用 WIC 获取系统编解码器
在 Windows 系统上,有一个很重要的概念是 Windows Imaging Component 也就是 WIC 层,这是专门用来处理多媒体相关的系统组件,特别是用来处理图片相关,包括编码和解码和 ...
- dotnet 将任意时区的 DateTimeOffset 转换为中国时区时间文本
本文告诉大家在拿到任意时区的 DateTimeOffset 对象,将 DateTimeOffset 转换为使用中国的 +8 时区表示的时间 在开始之前,需要说明的是,采用 DateTimeOffset ...
- aspnetcore插件开发dll热加载
该项目比较简单,只是单纯的把业务的dll模块和controller的dll做了一个动态的添加删除处理,目的就是插件开发.由于该项目过于简单,请勿吐槽.复杂的后续可以通过泛型的实体.dto等做业务和接口 ...
- 利用Navicat的历史日志查询表的索引信息(还可以查询很多系统级别的信息)
1.使用前提 所有的能用Navicat连接的数据库都可以使用这个方法 DDL/DML语句都有 2.Navicat中的历史日志 3.比如查询mysql的表的索引 先打开"历史记录" ...
- 【Oracle】导出全库备份,导入指定的schema并替换现有的表
需求:开发环境,每天晚上做了全库导出备份.由于误操作,现在要恢复指定的schema下的所有表,操作思路如下: 1.全库导出备份的语句 expdp system/oracle full=y dumpfi ...
- CSS自适应网页(CSS第一篇)
CSS的属性: 用浏览器自带的审查元素对一些页面进行调整,快捷键是F12. 网页允许宽度自适应: 在代码的头部加入一行viewport元标签. <meta name="viewpor ...
- threejs
- iceoryx源码阅读(三)——共享内存通信(一)
目录 0 导引 1 整体通信结构 2 RelativePointer 2.1 原理 2.2 PointerRepository 2.3 构造函数 2.4 get函数 3 ShmSafeUnmanage ...