【RocketMQ】消息的存储总结
当Broker收到生产者的消息发送请求时,会对请求进行处理,从请求中解析发送的消息数据,接下来以单个消息的接收为例,看一下消息的接收过程。
数据校验
封装消息
首先Broker会创建一个MessageExtBrokerInner对象封装从请求中解析到的消息数据,它会将Topic信息、队列ID、消息内容、消息属性、发送消息时间、发送消息的主机地址等信息设置到MessageExtBrokerInner中,后续都使用这个MessageExtBrokerInner对象来操纵消息。
接下来会判断是否开启事务,开启事务与未开启事务时调用的方法不一致,这里以未开启事务为例,看下消息的持久化过程。
消息校验
在存储消息之前,需要对消息进行一系列的校验,保证收到的消息有效合法。
Broker存储合法性检查
主要对Broker是否可以写入消息进行检查,包含以下几个方面:
- 判断是否处于关闭消息存储的状态,如果处于关闭状态则不再受理消息的存储;
- Broker是否是从节点,从节点只能读不能写;
- Broker是否有写权限,如果没有写入权限,不能进行写入操作;
- 操作系统是否处于PAGECACHE繁忙状态,处于繁忙状态同样不能进行写入操作;
消息长度检查
主要是对主题的长度校验和消息属性的长度校验。
LMQ(Light Message Queue)
主要判断在开启LMQ(Light Message Queue)时是否超过了最大消费数量。
消息写入
对消息进行校验完毕之后,就可以对消息进行写入了。
前面说到Broker将收到的消息封装为了MessageExtBrokerInner对象,这里会新增以下设置:
(1)设置消息存储的时间(当前时间);
(2)计算消息体的CRC值,并设置到对应的成员变量中;
(3)如果发送消息的主机地址或者当前存储消息的Broker地址使用了IPV6,设置相应的IPV6标识;
写入缓冲区
RocketMQ会将消息数据先写入内存buffer,写入之前还会做一些校验:
(1)对消息属性数据的长度进行校验判断是否超过限定值;
(2)对消息整体内容长度进行校验,判断是否超过最大的长度限制;
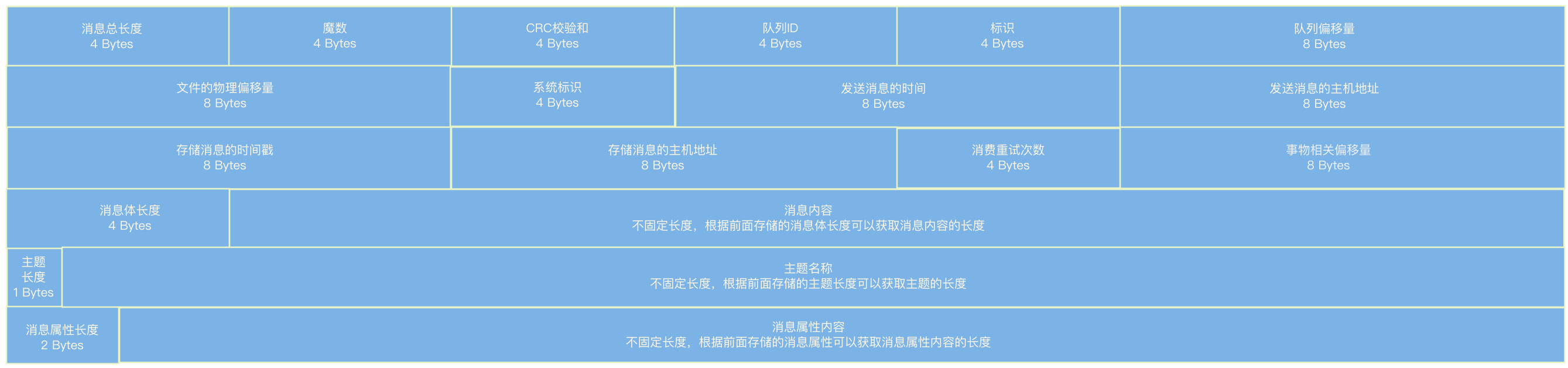
校验通过之后,会根据消息总体内容的长度对buffer进行初始化,也就是根据需要的大小申请一块内存区域,开始写入以下数据:
- 消息总长度,占4个字节;
- 魔数,占4个字节;
- 消息体CRC校验和,占4个字节;
- 队列ID,占4个字节;
- 标识,占4个字节;
- 队列的偏移量,占8个字节;
- 消息在文件的物理偏移量,占8个字节;
- 系统标识,占4个字节;
- 发送消息的时间戳,占8个字节;
- 发送消息的主机地址,占8个字节;
- 存储时间戳,占8个字节;
- 存储消息的主机地址,占8个字节;
- 消息的重试次数,占4个字节;
- 事务相关偏移量,占8个字节;
- 消息内容的长度,占4个字节;
- 消息内容,由于消息内容不固定,所以长度不固定;
- 主题名称的长度,占1个字节;
- 主题名称内容,长度不固定;
- 消息属性长度,占2个字节;
- 消息属性内容,长度不固定;
整体存储格式如下:
获取CommitLog
RocketMQ将每一条消息存储到CommitLog文件中,存储文件的根目录由配置参数storePathRootDir决定:

默认每一个CommitLog的文件大小为1G,如果文件写满会新建一个CommitLog文件,以该文件中第一条消息的偏移量为文件名,小于20位用0补齐。
比如第一个文件中第一条消息的偏移量为0,那么第一个文件的名称为00000000000000000000,当这个文件存满之后,需要重新建立一个CommitLog文件,一个文件大小为1G,
1GB = 1024*1024*1024 = 1073741824 Bytes,所以下一个文件就会被命名为00000000001073741824。
在持久化消息之前,需要知道消息要写入哪个CommitLog文件,RocketMQ通过一个队列(对应MappedFileQueue)存储了记录了所有的CommitLog文件(对应MappedFile),并提供了相关方法获取到当前正在使用的那个CommitLog。
mappedFileQueue是所有mappedFile的集合,可以理解为CommitLog文件所在的那个目录。
MappedFile可以看做是每一个Commitlog文件的映射对象,每一个CommitLog对于一个MappedFile对象。
如果获取到的CommitLog取为空或者已写满,可能是首次写入消息还未创建文件或者上一次写入的文件已达到规定的大小(1G),此时会新建一个CommitLog文件。
需要注意,在获取CommitLog之前会加锁,一是防止在多线程情况下创建多个CommitLog,二是接下来要往CommitLog中写入消息内容,防止多线程情况下数据错乱。
写入CommitLog
知道要写入哪个CommitLog之后,就可以将之前已经写入缓冲区buffer的消息数据写入到CommitLog了。
RocketMQ提供了两种方式进行写入:
(1)通过暂存池将数据写入缓冲区
在开启暂存池时,会先将数据都写入字节缓冲区ByteBuffer中,ByteBuffer在申请内存时,可以申请JVM堆内内存(HeapByteBuffer),也可以申请堆外内存(DirectByteBuffer),RocketMQ使用的是堆外内存DirectByteBuffer。
暂存池
类似线程池,只不过池中存放的是提前申请好的内存(ByteBuffer),RocketMQ会预先申请一些内存,从源码中可以看到申请的是堆外内存,然后放入池中,需要用时从池中获取,使用完毕后会归还到池中。
暂存池的开启条件
需要同时满足以下三个条件时才会开启暂存池:
- 配置中允许开启暂存池;
- Broker的角色不能是
SLAVE; - 刷盘策略为异步刷盘;
从条件3中可以看出异步刷盘时才可以开启暂存池的使用,因为异步刷盘,很有可能是积攒了一批消息,需要同时刷入磁盘,所以使用暂存池可以将之前写入的消息先暂存在内存缓冲区中,等待执行刷盘时,将积攒的消息一起刷入磁盘中,而同步刷盘由于每次写入完毕之后要立刻刷回磁盘,那么就没有必要使用暂存池缓存数据了。
(2)通过文件映射
未开启暂存池时使用文件映射,使用MappedByteBuffer映射对应的CommitLog文件,MappedByteBuffer是ByteBuffer的子类,它可以将磁盘的文件内容映射到虚拟地址空间,通过虚拟地址访问物理内存中映射的文件内容,对文件内容进行操作。
使用MappedByteBuffer可以减少数据的拷贝,详细内容可参考【Java】Java中的零拷贝。
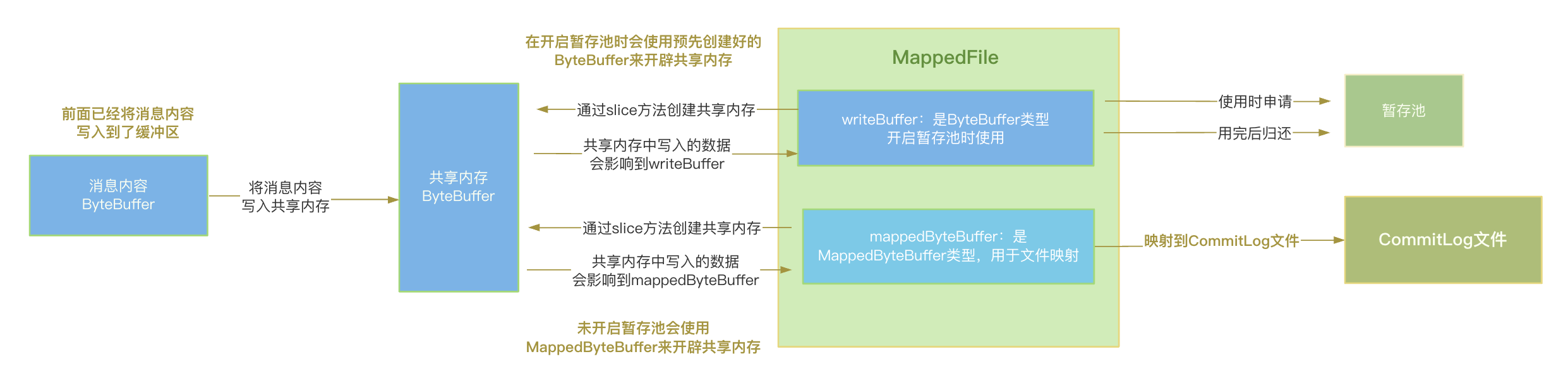
消息写入流程
了解了写入方式之后,来看下消息的写入流程:
CommitLog对应的
MappedFile对象中记录了当前文件的写入位置,首先会判断准备写入的位置是否小于文件总大小,如果小于意味着当前文件可以进行内容写入,反之说明此文件已写满,不能继续下一步,需要返回错误信息;判断是否开启暂存池,开启暂存池时使用
MappedFile中的ByteBuffer来开辟共享内存,否则使用MappedFile中的;
MappedByteBuffer来开辟。
开辟共享内存之后,往共享内存中写入的数据,会影响到开辟它那个
ByteBuffer或者MappedByteBuffer中;
将之前已经写入缓冲区的消息数据写入到开辟的共享内存中;
返回消息写入结果,有以下几种状态:
- PUT_OK:写入成功;
- END_OF_FILE:超过文件大小;
- MESSAGE_SIZE_EXCEEDED:消息长度超过最大允许长度:
- PROPERTIES_SIZE_EXCEEDED:消息、属性超过最大允许长度;
- UNKNOWN_ERROR:未知异常;
需要注意,此时消息驻留在操作系统的PAGECACHE中,接下来需要根据刷盘策略决定何时将内容刷入到硬盘中。
RocketMQ消息存储相关源码可参考:【RocketMQ】【源码】消息的存储
刷盘处理
在以上的消息写入步骤完成之后,会进行刷盘操作。
有两种刷盘策略:
同步刷盘:表示消息写入到内存之后需要立刻刷到磁盘文件中。
异步刷盘:表示消息写入内存成功之后就返回,由MQ定时将数据刷入到磁盘中,会有一定的数据丢失风险。
不管同步刷盘还是异步刷盘,都是唤醒对应的刷盘线程来进行,这里不对唤醒的具体过程进行讲解,如果想了解可参考【RocketMQ】【源码】消息的刷盘机制。
同步刷盘
前面讲到,暂存池只有在异步刷盘时才可以启用,所以设置为同步刷盘时,使用的是文件映射的方式写入数据,在同步刷盘时直接通过MappedByteBuffer的force方法将数据flush到磁盘文件即可。
异步刷盘
异步刷盘有开启暂存池和未开启两种情况。
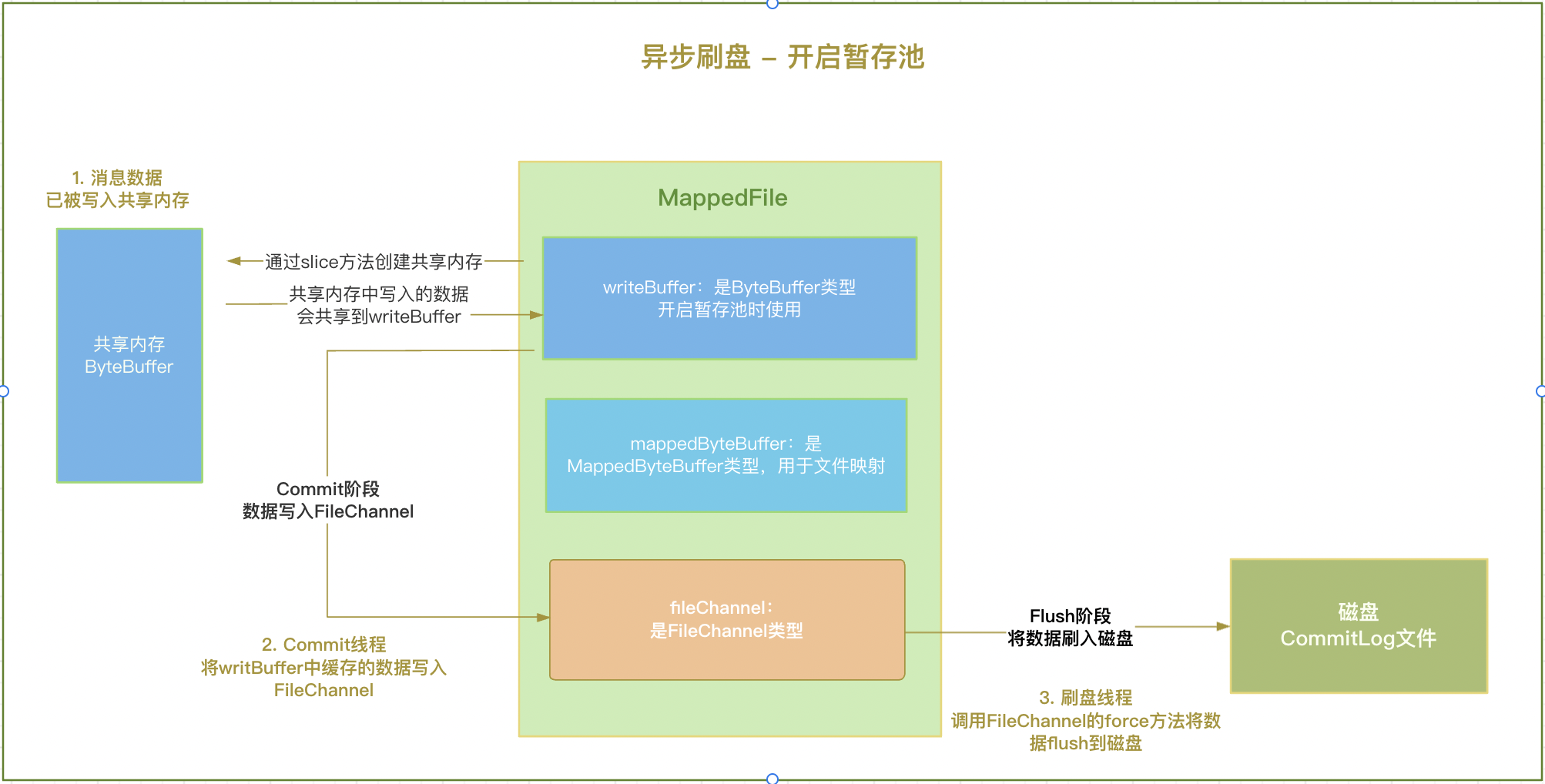
开启暂存池
开启暂存池时,可以分为Commit和Flush两个阶段。
(1)Commit阶段
在开启暂存池时,数据会先写入缓冲区ByteBuffer中,并未映射到CommitLog文件中,所以首先会唤醒Commit线程,将ByteBuffer中的数据写入到CommitLog对应的FileChannel中。
(2)Flush阶段
数据被写入FileChannel之后,就会唤醒Flush线程,再调用FileChannel的force方法将数据flush到磁盘。
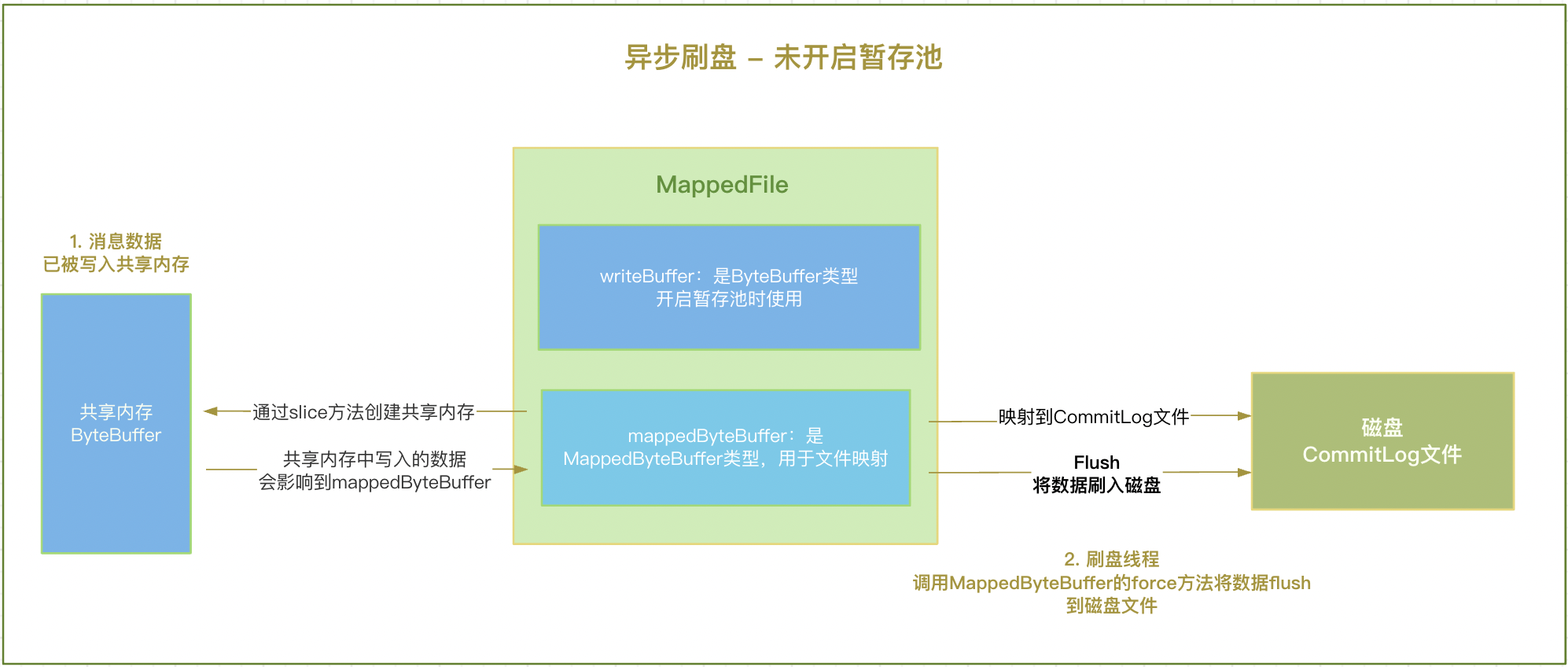
未开启暂存池
未开启暂存池时使用文件映射的方式,直接唤醒Flush线程,调用MappedByteBuffer的force方法将数据flush到磁盘文件即可。
总结
通过上面分析消息的持久化过程,来看下RocketMQ提升性能的一些地方。
(1)RocketMQ在写入数据到CommitLog时,采用的是顺序写的方式,顺序写比随机写文件效率要高很多。
(2)在异步刷盘时,可以使用暂存池,暂存池会提前申请好内存,申请内存是一个比较重的操作,所以避免在消息写入时申请内存,以此提高效率。
(3)RocketMQ使用了MappedByteBuffer文件映射的方式,向CommitLog写入数据,可以减少数据的拷贝过程。
参考
【RocketMQ】消息的存储总结的更多相关文章
- 从源码分析RocketMq消息的存储原理
rocketmq在存储消息的时候,最终是通过mmap映射成磁盘文件进行存储的,本文就消息的存储流程作一个整理.源码版本是4.9.2 主要的存储组件有如下4个: CommitLog:存储的业务层,接收& ...
- 【RocketMQ】消息的存储
Broker对消息的处理 BrokerController初始化的过程中,调用registerProcessor方法注册了处理器,在注册处理器的代码中可以看到创建了处理消息发送的处理器对象SendMe ...
- RocketMQ消息轨迹-设计篇
目录 1.消息轨迹数据格式 2.记录消息轨迹 3.如何存储消息轨迹数据 @(本节目录) RocketMQ消息轨迹主要包含两篇文章:设计篇与源码分析篇,本节将详细介绍RocketMQ消息轨迹-设计相关. ...
- 源码分析RocketMQ消息轨迹
目录 1.发送消息轨迹流程 1.1 DefaultMQProducer构造函数 1.2 SendMessageTraceHookImpl钩子函数 1.3 TraceDispatcher实现原理 2. ...
- RocketMQ(消息重发、重复消费、事务、消息模式)
分布式开放消息系统(RocketMQ)的原理与实践 RocketMQ基础:https://github.com/apache/rocketmq/tree/rocketmq-all-4.5.1/docs ...
- 探秘 RocketMQ 消息持久化机制
我们知道 RocketMQ 是一款高性能.高可靠的分布式消息中间件,高性能和高可靠是很难兼得的.因为要保证高可靠,那么数据就必须持久化到磁盘上,将数据持久化到磁盘,那么可能就不能保证高性能了. Roc ...
- RocketMQ 消息丢失场景分析及如何解决
生产者产生消息发送给RocketMQ RocketMQ接收到了消息之后,必然需要存到磁盘中,否则断电或宕机之后会造成数据的丢失 消费者从RocketMQ中获取消息消费,消费成功之后,整个流程结束 1. ...
- 一张图进阶 RocketMQ - 消息发送
前 言 三此君看了好几本书,看了很多遍源码整理的 一张图进阶 RocketMQ 图片链接,关于 RocketMQ 你只需要记住这张图!觉得不错的话,记得点赞关注哦. [重要]视频在 B 站同步更新,欢 ...
- RocketMQ消息短暂而又精彩的一生
大家好,我是三友~~ 这篇文章我准备来聊一聊RocketMQ消息的一生. 不知你是否跟我一样,在使用RocketMQ的时候也有很多的疑惑: 消息是如何发送的,队列是如何选择的? 消息是如何存储的,是如 ...
- RocketMq消息队列使用
最近在看消息队列框架 ,alibaba的RocketMQ单机支持1万以上的持久化队列,支持诸多特性, 目前RocketMQ在阿里集团被广泛应用在订单,交易,充值,流计算,消息推送,日志流式处理,bin ...
随机推荐
- 2021-03-22:小虎去买苹果,商店只提供两种类型的塑料袋,每种类型都有任意数量。1.能装下6个苹果的袋子,2.能装下8个苹果的袋子。小虎可以自由使用两种袋子来装苹果,但是小虎有强迫症,他要求自己使用的袋子数量必须最少,且使用的每个袋子必须装满。给定一个正整数N,返回至少使用多少袋子。如果N无法让使用的每个袋子必须装满,返回-1。
2021-03-22:小虎去买苹果,商店只提供两种类型的塑料袋,每种类型都有任意数量.1.能装下6个苹果的袋子,2.能装下8个苹果的袋子.小虎可以自由使用两种袋子来装苹果,但是小虎有强迫症,他要求自己 ...
- C++实现查询本机信息并且上报
业务需求 共享文件夹.盘会导致系统安全性下降,故IT部门需要搜集公司中每台电脑的共享情况,并且进行上报 关键字 WMI查询.Get请求.C++网络库mongoose 前置需要 1.简单C++语法知识2 ...
- Ubuntu 18.04 (Bionic) 简单快速的安装mongodb
按步骤走,不带脑子式安装(注意4.0版本mongodb官方已经不再支持,以下代码中可以修改mongodb版本号安装,目前最新版为6.0,如果懒得改直接用也可以,文章后边第三章第一条代码会直接升级为最新 ...
- shell脚本中特殊筛选文件
问题描述:在写shell中,总会遇到一些各式各样筛选文件的需求,整理了一些特殊情况 1.查找目标文件下大于100Mb的文件 find $target_dir -type f -size +70M 2. ...
- NVIDIA Maxine Video Effects SDK 編程指南 - 实践小记
NVIDIA Maxine Video Effects SDK 編程指南 - 实践小记 本篇博客重点只说Video Effect的部分,此外还有Audio Effect的部分.还有AR部分,不在本篇范 ...
- [ESP] 私有版Rainmaker User Mapping
[ESP] 私有版Rainmaker User Mapping 1. 设备烧录的程序esp-rainmaker/examples/gpio这个demo 我这里是自己的工程,可以参照 idf.py se ...
- #mac安装Homebrew报错问题:curl: (7) Failed to connect to raw.githubusercontent.com port 443: Connection refused
我们在打开https://brew.sh/index_zh-cn官网的时候都会给你下面这段代码,粘贴复制就可以安装: /bin/bash -c "$(curl -fsSL https://r ...
- List 接口及其常用方法
List 接口基本介绍 List接口是Collection接口的子接口,其主要特点如下: List中元素有序,是按照元素的插入顺序进行排序的.每个元素都有一个与之关联的整数型索引(索引从 0 开始), ...
- Mysql基础篇(四)之事务
一. 事务简介 事务是一组操作的集合,它是一个不可分隔的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败. 就比如:张三给李四转账1000块钱 ...
- 一个C#跨平台的机器视觉和机器学习的开源库
大家都知道OpenCV是一个跨平台的机器视觉和机器学习的开源库,可以运行在Linux.Windows.Android和Mac OS操作系统上,由C++开发. 今天给大家介绍一个用C#对OpenCV封装 ...