[转帖]LSM树详解
https://zhuanlan.zhihu.com/p/181498475
LSM树(Log-Structured-Merge-Tree)的名字往往会给初识者一个错误的印象,事实上,LSM树并不像B+树、红黑树一样是一颗严格的树状数据结构,它其实是一种存储结构,目前HBase,LevelDB,RocksDB这些NoSQL存储都是采用的LSM树。
LSM树的核心特点是利用顺序写来提高写性能,但因为分层(此处分层是指的分为内存和文件两部分)的设计会稍微降低读性能,但是通过牺牲小部分读性能换来高性能写,使得LSM树成为非常流行的存储结构。
1、LSM树的核心思想
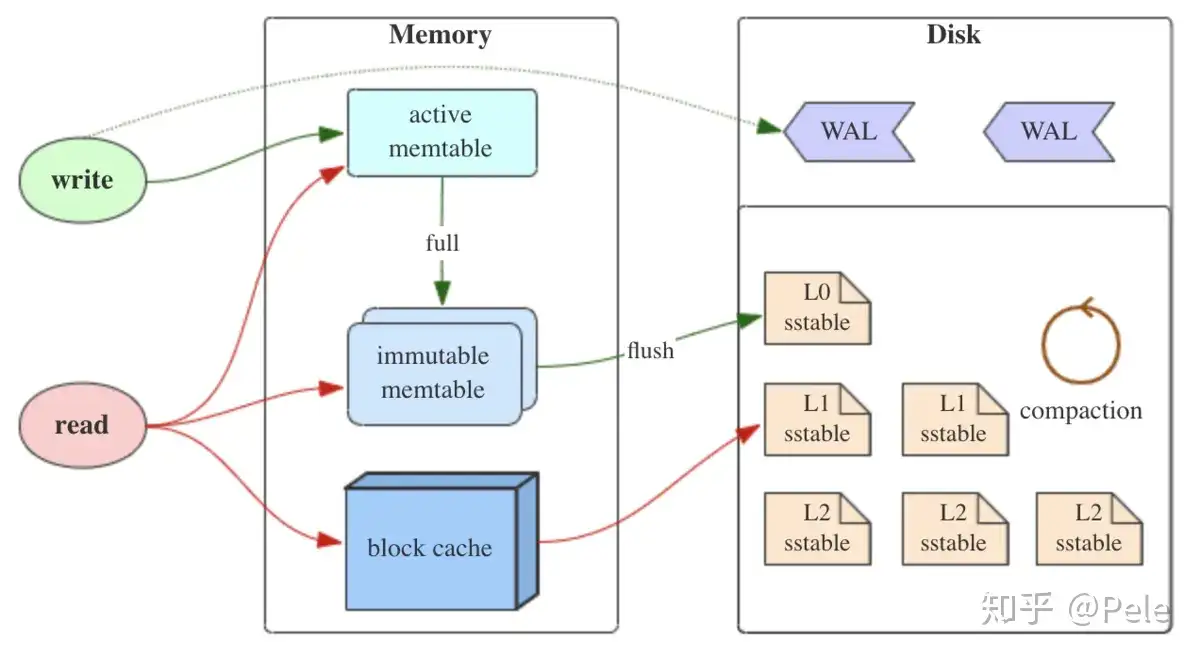
如上图所示,LSM树有以下三个重要组成部分:
1) MemTable
MemTable是在内存中的数据结构,用于保存最近更新的数据,会按照Key有序地组织这些数据,LSM树对于具体如何组织有序地组织数据并没有明确的数据结构定义,例如Hbase使跳跃表来保证内存中key的有序。
因为数据暂时保存在内存中,内存并不是可靠存储,如果断电会丢失数据,因此通常会通过WAL(Write-ahead logging,预写式日志)的方式来保证数据的可靠性。
2) Immutable MemTable
当 MemTable达到一定大小后,会转化成Immutable MemTable。Immutable MemTable是将转MemTable变为SSTable的一种中间状态。写操作由新的MemTable处理,在转存过程中不阻塞数据更新操作。
3) SSTable(Sorted String Table)
有序键值对集合,是LSM树组在磁盘中的数据结构。为了加快SSTable的读取,可以通过建立key的索引以及布隆过滤器来加快key的查找。

这里需要关注一个重点,LSM树(Log-Structured-Merge-Tree)正如它的名字一样,LSM树会将所有的数据插入、修改、删除等操作记录(注意是操作记录)保存在内存之中,当此类操作达到一定的数据量后,再批量地顺序写入到磁盘当中。这与B+树不同,B+树数据的更新会直接在原数据所在处修改对应的值,但是LSM数的数据更新是日志式的,当一条数据更新是直接append一条更新记录完成的。这样设计的目的就是为了顺序写,不断地将Immutable MemTable flush到持久化存储即可,而不用去修改之前的SSTable中的key,保证了顺序写。
因此当MemTable达到一定大小flush到持久化存储变成SSTable后,在不同的SSTable中,可能存在相同Key的记录,当然最新的那条记录才是准确的。这样设计的虽然大大提高了写性能,但同时也会带来一些问题:
1)冗余存储,对于某个key,实际上除了最新的那条记录外,其他的记录都是冗余无用的,但是仍然占用了存储空间。因此需要进行Compact操作(合并多个SSTable)来清除冗余的记录。
2)读取时需要从最新的倒着查询,直到找到某个key的记录。最坏情况需要查询完所有的SSTable,这里可以通过前面提到的索引/布隆过滤器来优化查找速度。
2、LSM树的Compact策略
从上面可以看出,Compact操作是十分关键的操作,否则SSTable数量会不断膨胀。在Compact策略上,主要介绍两种基本策略:size-tiered和leveled。
不过在介绍这两种策略之前,先介绍三个比较重要的概念,事实上不同的策略就是围绕这三个概念之间做出权衡和取舍。
1)读放大:读取数据时实际读取的数据量大于真正的数据量。例如在LSM树中需要先在MemTable查看当前key是否存在,不存在继续从SSTable中寻找。
2)写放大:写入数据时实际写入的数据量大于真正的数据量。例如在LSM树中写入时可能触发Compact操作,导致实际写入的数据量远大于该key的数据量。
3)空间放大:数据实际占用的磁盘空间比数据的真正大小更多。上面提到的冗余存储,对于一个key来说,只有最新的那条记录是有效的,而之前的记录都是可以被清理回收的。
1) size-tiered 策略
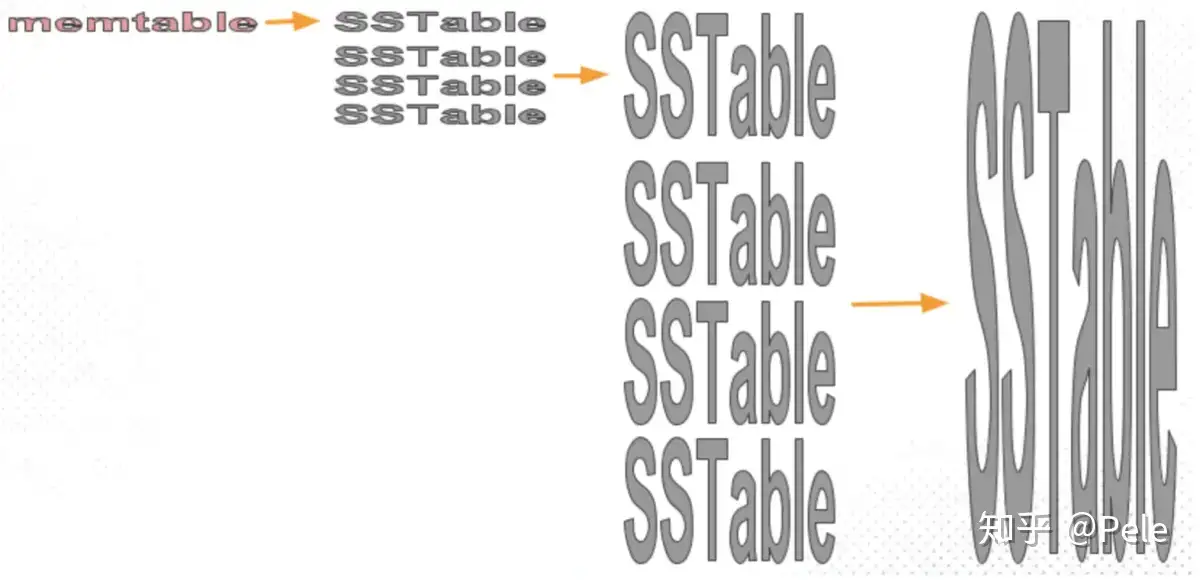
size-tiered策略保证每层SSTable的大小相近,同时限制每一层SSTable的数量。如上图,每层限制SSTable为N,当每层SSTable达到N后,则触发Compact操作合并这些SSTable,并将合并后的结果写入到下一层成为一个更大的sstable。
由此可以看出,当层数达到一定数量时,最底层的单个SSTable的大小会变得非常大。并且size-tiered策略会导致空间放大比较严重。即使对于同一层的SSTable,每个key的记录是可能存在多份的,只有当该层的SSTable执行compact操作才会消除这些key的冗余记录。
2) leveled策略
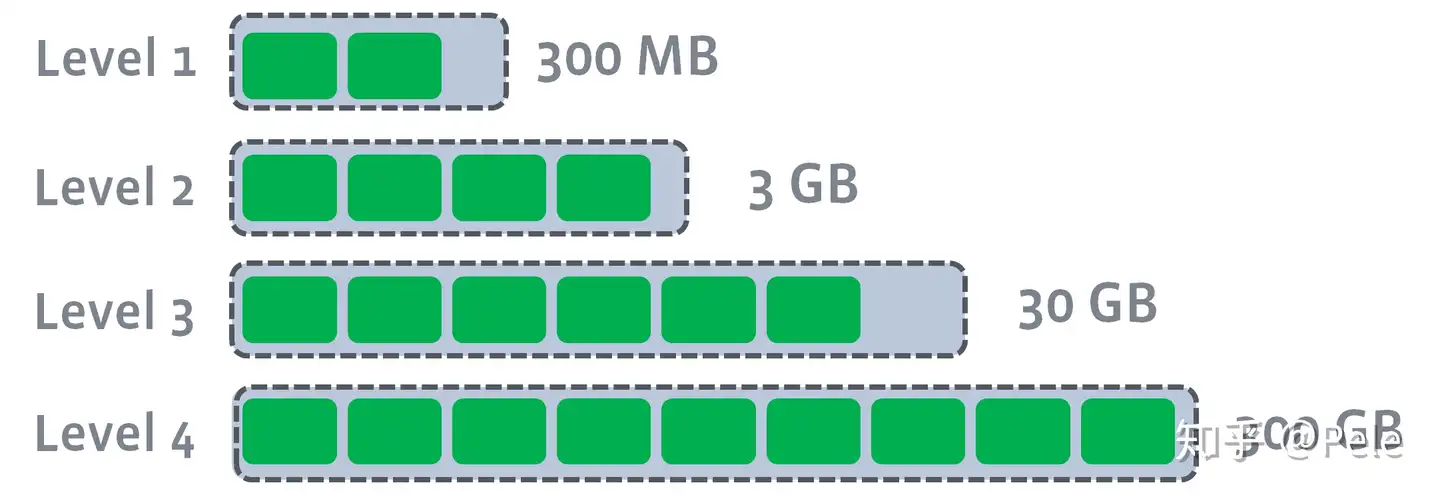
每一层的总大小固定,从上到下逐渐变大
leveled策略也是采用分层的思想,每一层限制总文件的大小。
但是跟size-tiered策略不同的是,leveled会将每一层切分成多个大小相近的SSTable。这些SSTable是这一层是全局有序的,意味着一个key在每一层至多只有1条记录,不存在冗余记录。之所以可以保证全局有序,是因为合并策略和size-tiered不同,接下来会详细提到。
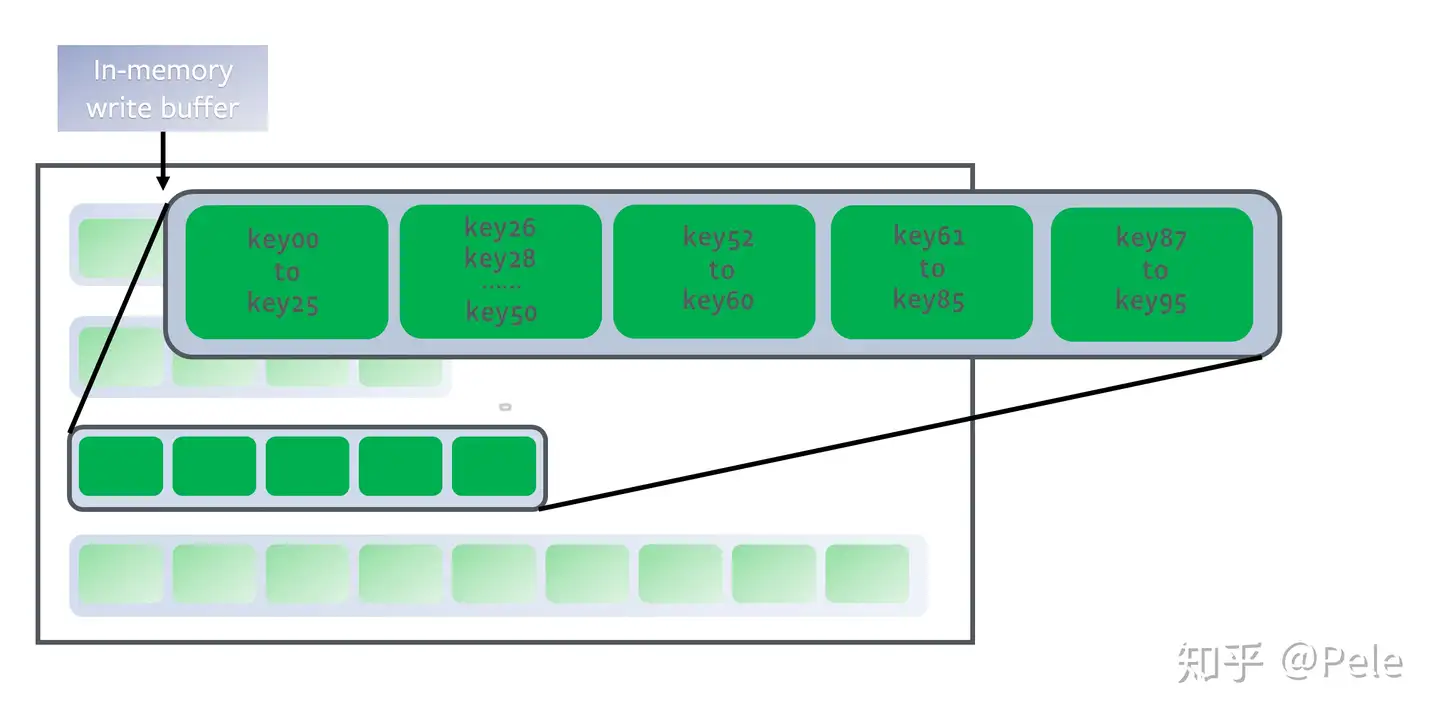
每一层的SSTable是全局有序的
假设存在以下这样的场景:
1) L1的总大小超过L1本身大小限制:
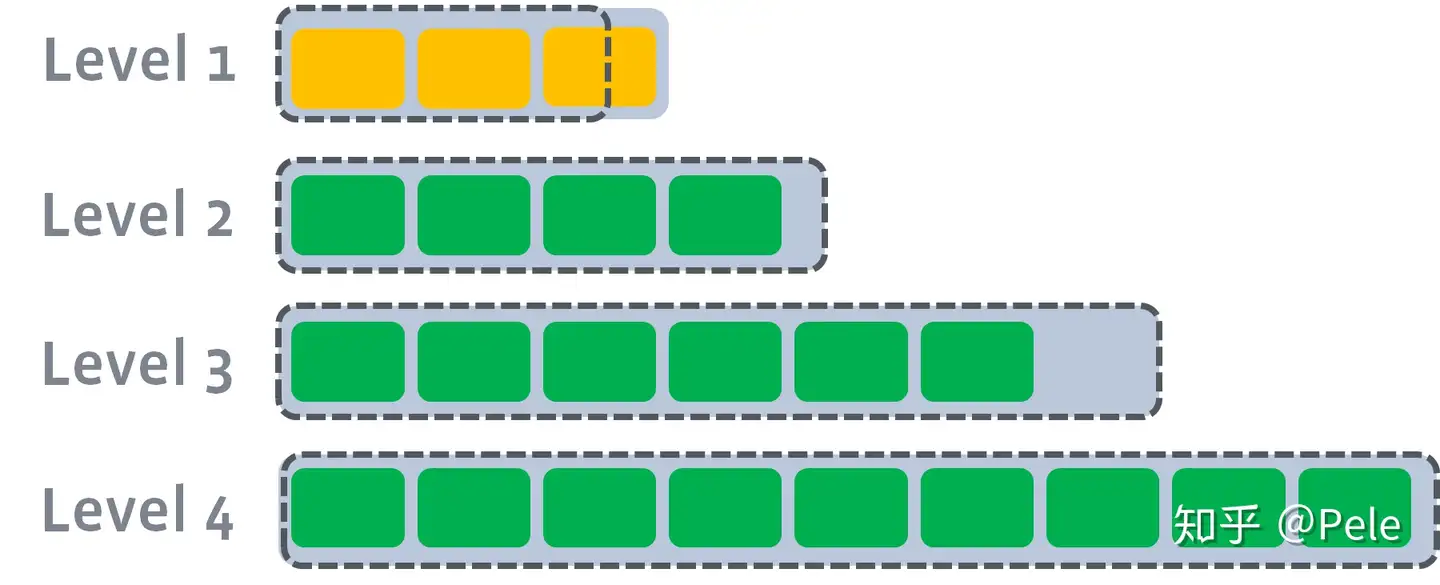
此时L1超过了最大阈值限制
2) 此时会从L1中选择至少一个文件,然后把它跟L2有交集的部分(非常关键)进行合并。生成的文件会放在L2:
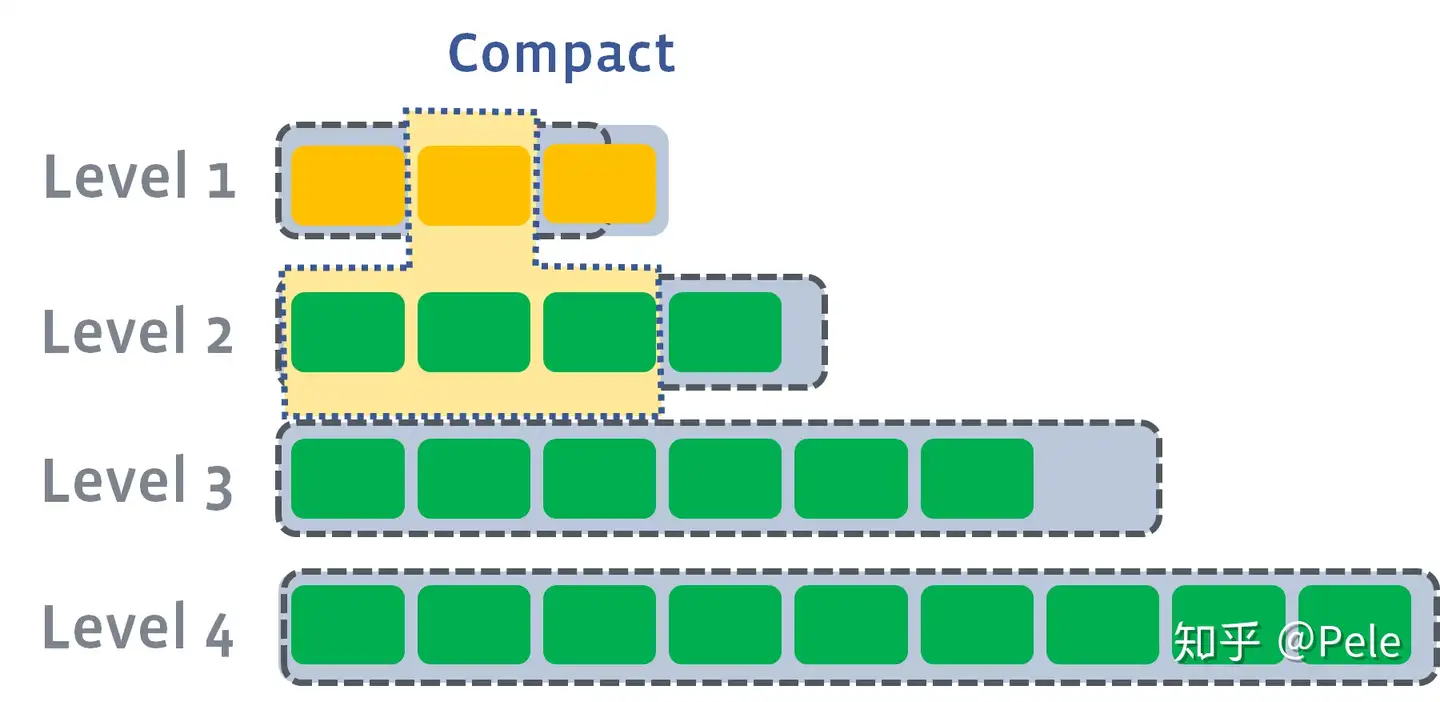
如上图所示,此时L1第二SSTable的key的范围覆盖了L2中前三个SSTable,那么就需要将L1中第二个SSTable与L2中前三个SSTable执行Compact操作。
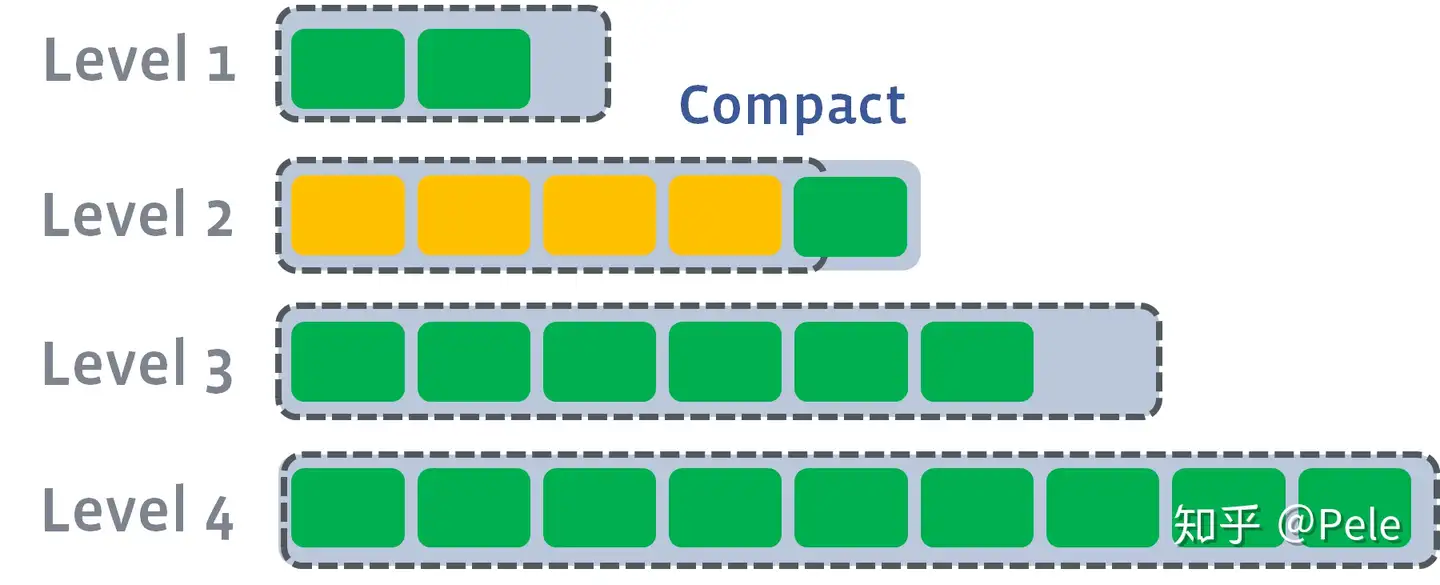
3) 如果L2合并后的结果仍旧超出L5的阈值大小,需要重复之前的操作 —— 选至少一个文件然后把它合并到下一层:
需要注意的是,多个不相干的合并是可以并发进行的:
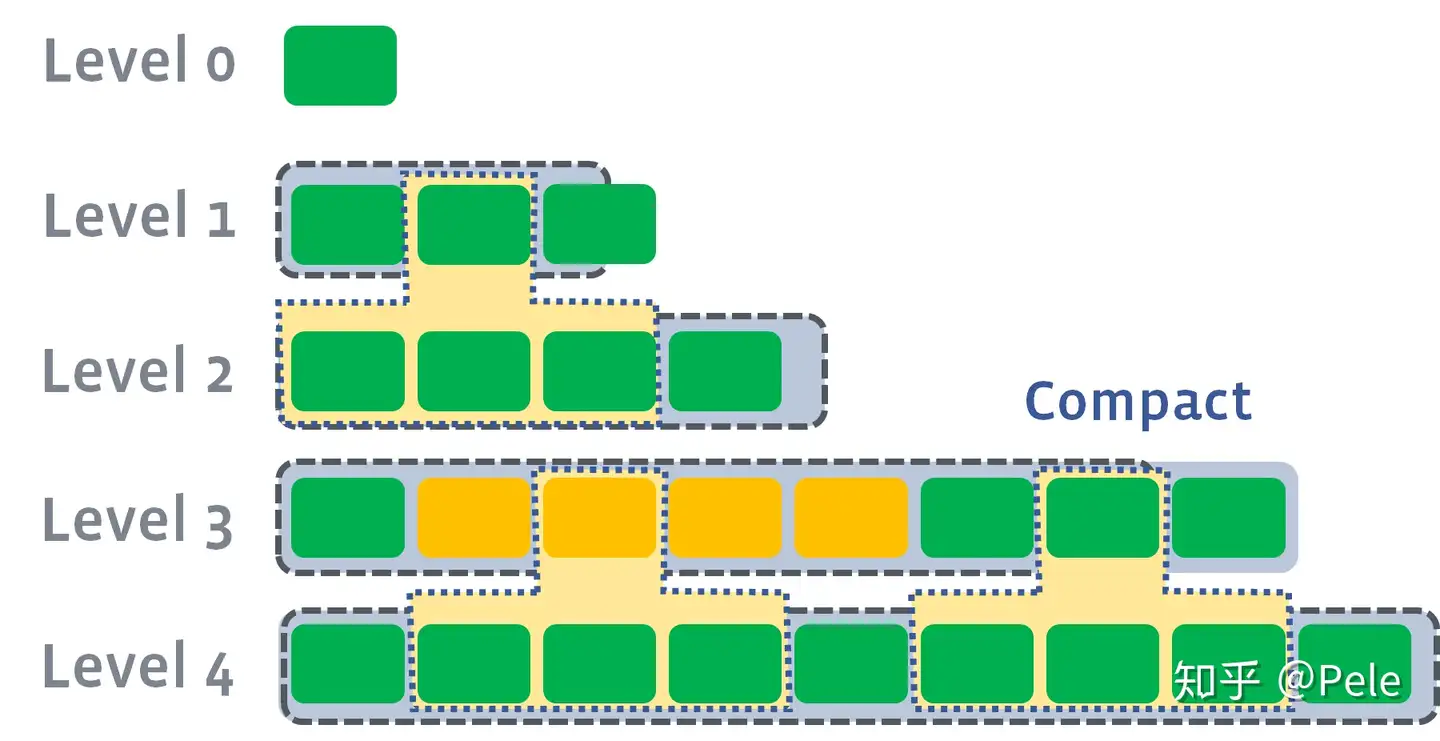
leveled策略相较于size-tiered策略来说,每层内key是不会重复的,即使是最坏的情况,除开最底层外,其余层都是重复key,按照相邻层大小比例为10来算,冗余占比也很小。因此空间放大问题得到缓解。但是写放大问题会更加突出。举一个最坏场景,如果LevelN层某个SSTable的key的范围跨度非常大,覆盖了LevelN+1层所有key的范围,那么进行Compact时将涉及LevelN+1层的全部数据。
3、总结
LSM树是非常值得了解的知识,理解了LSM树可以很自然地理解Hbase,LevelDb等存储组件的架构设计。ClickHouse中的MergeTree也是LSM树的思想,Log-Structured还可以联想到Kafka的存储方式。
虽然介绍了上面两种策略,但是各个存储都在自己的Compact策略上面做了很多特定的优化,例如Hbase分为Major和Minor两种Compact,这里不再做过多介绍,推荐阅读文末的RocksDb合并策略介绍。
PS:封面是在当时百度搜索lsm树的截图,真实截图,非PS。
[转帖]LSM树详解的更多相关文章
- LSM 树详解
LSM树(Log Structured Merged Tree)的名字往往给人一个错误的印象, 实际上LSM树并没有严格的树状结构. LSM 树的思想是使用顺序写代替随机写来提高写性能,与此同时会略微 ...
- 数据结构图文解析之:AVL树详解及C++模板实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- trie字典树详解及应用
原文链接 http://www.cnblogs.com/freewater/archive/2012/09/11/2680480.html Trie树详解及其应用 一.知识简介 ...
- Linux DTS(Device Tree Source)设备树详解之二(dts匹配及发挥作用的流程篇)【转】
转自:https://blog.csdn.net/radianceblau/article/details/74722395 版权声明:本文为博主原创文章,未经博主允许不得转载.如本文对您有帮助,欢迎 ...
- JavaScript---Dom树详解,节点查找方式(直接(id,class,tag),间接(父子,兄弟)),节点操作(增删改查,赋值节点,替换节点,),节点属性操作(增删改查),节点文本的操作(增删改查),事件
JavaScript---Dom树详解,节点查找方式(直接(id,class,tag),间接(父子,兄弟)),节点操作(增删改查,赋值节点,替换节点,),节点属性操作(增删改查),节点文本的操作(增删 ...
- 线段树详解 (原理,实现与应用)(转载自:http://blog.csdn.net/zearot/article/details/48299459)
原文地址:http://blog.csdn.net/zearot/article/details/48299459(如有侵权,请联系博主,立即删除.) 线段树详解 By 岩之痕 目录: 一:综述 ...
- Linux dts 设备树详解(二) 动手编写设备树dts
Linux dts 设备树详解(一) 基础知识 Linux dts 设备树详解(二) 动手编写设备树dts 文章目录 前言 硬件结构 设备树dts文件 前言 在简单了解概念之后,我们可以开始尝试写一个 ...
- Linux dts 设备树详解(一) 基础知识
Linux dts 设备树详解(一) 基础知识 Linux dts 设备树详解(二) 动手编写设备树dts 文章目录 1 前言 2 概念 2.1 什么是设备树 dts(device tree)? 2. ...
- B树、B+树详解
B树.B+树详解 B树 前言 首先,为什么要总结B树.B+树的知识呢?最近在学习数据库索引调优相关知识,数据库系统普遍采用B-/+Tree作为索引结构(例如mysql的InnoDB引擎使用的B+树 ...
- AVL树详解
AVL树 参考了:http://www.cppblog.com/cxiaojia/archive/2012/08/20/187776.html 修改了其中的错误,代码实现并亲自验证过. 平衡二叉树(B ...
随机推荐
- 文心一言 VS 讯飞星火 VS chatgpt (49)-- 算法导论6.2 1题
一.参照图6-2的方法,说明 MAX-HEAPIFY(A,3)在数组 A=(27,17,3,16,13,10,1,5,7,12,4,8,9,0)上的操作过程. 文心一言: 下面是 MAX-HEAPIF ...
- 数仓专家面对面 | 为什么我选择GaussDB(DWS)
摘要:你知道数仓是如何应运而生的吗?你了解数仓未来的发展趋势吗?想知道国内数仓专家的看法吗? 导语 数据仓库的发展一直是备受关注的议题,随着近年来技术的不断演进,数仓也在更新迭代. 你知道数仓是如何应 ...
- App Store上架流程/苹果app发布流程
第一步:拥有自己的苹果开发者账号: 开发账号分为两类:99美元(发布App Store用的,也就是上架苹果商店用这个):299美元(企业授信证书,不用上架appstore 亦可使用.弊端:证书容易被封 ...
- java jar 注册成 windows 服务
1.去github上下载winsw https://github.com/winsw/winsw/releases 2.WinSW.NET4.xml <service> <id> ...
- vmware中 centos 突然不能联网,ens33丢失,见了鬼了..........
本人笔记本上vmware中centos允许一直很稳定,今天启动centos准备docker打包,结果发现不能联网了!!! ifconfig一下,发现ens33没了,见鬼了吧! 于是一通vmware虚拟 ...
- 开源:Taurus.DTS 微服务分布式任务框架,支持即时任务、延时任务、Cron表达式定时任务和广播任务。
前言: 在发布完:开源:Taurus.DTC 微服务分布式事务框架,支持 .Net 和 .Net Core 双系列版本,之后想想,好像除了事务外,感觉里面多了一个任务发布订阅的基础功能. 本想既然都有 ...
- java向一个压缩包里增加文件
如果遇到,向现有的压缩包里增加文件的需求可以参照如下的方式: 思路:1.先将压缩包解压 2.删除旧的压缩包 3.将解压后的文件和希望添加的文件一起重新生成一个压缩包 4.将第一步中解压后的文件删除. ...
- 基于java+springboot的外卖点餐网站、外卖点餐管理系统
该系统是基于java+springboot开发的外卖点餐网站.外卖点餐管理系统.是给师弟开发的课程作业.运行过程中的问题,可以在github咨询作者. 演示地址 前台地址: http://food.g ...
- 解决python报错:ModuleNotFoundError: No module named '_sysconfigdata_x86_64_conda_linux_gnu'
技术背景 在上一篇博客中执行过conda的更新以及用conda安装了gxx_linux-64之后,再执行pip的一些指令时,就会给出如下所示的报错: $ python3 -m pip list Tra ...
- VSCODE中GIT配置
1.问题:无法正常提交 问题描述 *使用vscode提交就会一直卡住**. 参考方案链接:VS CODE GIT 500 问题处理-pudn.com 根据这位博主的描述,应当是设置的这里选择的默认选项 ...