[转帖]什么是ClickHouse?
什么是ClickHouse?
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
在传统的行式数据库系统中,数据按如下顺序存储:
| Row | WatchID | JavaEnable | Title | GoodEvent | EventTime |
|---|---|---|---|---|---|
| #0 | 89354350662 | 1 | Investor Relations | 1 | 2016-05-18 05:19:20 |
| #1 | 90329509958 | 0 | Contact us | 1 | 2016-05-18 08:10:20 |
| #2 | 89953706054 | 1 | Mission | 1 | 2016-05-18 07:38:00 |
| #N | … | … | … | … | … |
处于同一行中的数据总是被物理的存储在一起。
常见的行式数据库系统有:MySQL、Postgres和MS SQL Server。
在列式数据库系统中,数据按如下的顺序存储:
| Row: | #0 | #1 | #2 | #N |
|---|---|---|---|---|
| WatchID: | 89354350662 | 90329509958 | 89953706054 | … |
| JavaEnable: | 1 | 0 | 1 | … |
| Title: | Investor Relations | Contact us | Mission | … |
| GoodEvent: | 1 | 1 | 1 | … |
| EventTime: | 2016-05-18 05:19:20 | 2016-05-18 08:10:20 | 2016-05-18 07:38:00 | … |
这些示例只显示了数据的排列顺序。来自不同列的值被单独存储,来自同一列的数据被存储在一起。
常见的列式数据库有: Vertica、 Paraccel (Actian Matrix,Amazon Redshift)、 Sybase IQ、 Exasol、 Infobright、 InfiniDB、 MonetDB (VectorWise, Actian Vector)、 LucidDB、 SAP HANA、 Google Dremel、 Google PowerDrill、 Druid、 kdb+。
不同的数据存储方式适用不同的业务场景,数据访问的场景包括:进行了何种查询、多久查询一次以及各类查询的比例;每种类型的查询(行、列和字节)读取多少数据;读取数据和更新之间的关系;使用的数据集大小以及如何使用本地的数据集;是否使用事务,以及它们是如何进行隔离的;数据的复制机制与数据的完整性要求;每种类型的查询要求的延迟与吞吐量等等。
系统负载越高,依据使用场景进行定制化就越重要,并且定制将会变的越精细。没有一个系统能够同时适用所有不同的业务场景。如果系统适用于广泛的场景,在负载高的情况下,要兼顾所有的场景,那么将不得不做出选择。是要平衡还是要效率?
OLAP场景的关键特征
- 绝大多数是读请求
- 数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
- 已添加到数据库的数据不能修改。
- 对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
- 宽表,即每个表包含着大量的列
- 查询相对较少(通常每台服务器每秒查询数百次或更少)
- 对于简单查询,允许延迟大约50毫秒
- 列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
- 处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
- 每个查询有一个大表。除了他以外,其他的都很小。
- 查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
很容易可以看出,OLAP场景与其他通常业务场景(例如,OLTP或K/V)有很大的不同, 因此想要使用OLTP或Key-Value数据库去高效的处理分析查询场景,并不是非常完美的适用方案。例如,使用OLAP数据库去处理分析请求通常要优于使用MongoDB或Redis去处理分析请求。
列式数据库更适合OLAP场景的原因
列式数据库更适合于OLAP场景(对于大多数查询而言,处理速度至少提高了100倍),下面详细解释了原因(通过图片更有利于直观理解):
行式
列式
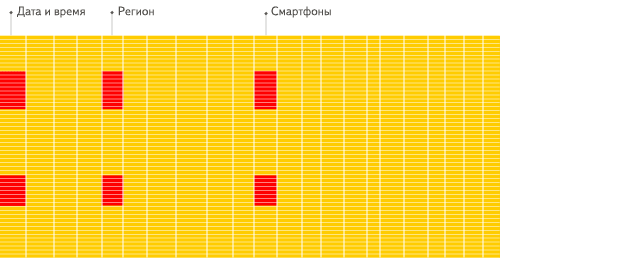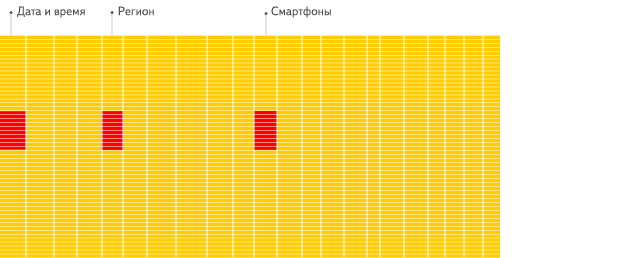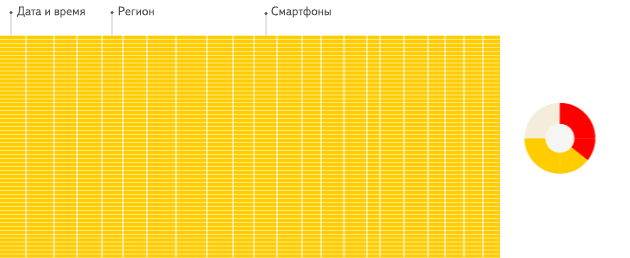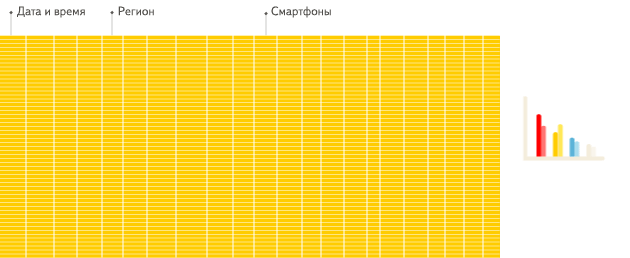
看到差别了么?下面将详细介绍为什么会发生这种情况。
输入/输出
- 针对分析类查询,通常只需要读取表的一小部分列。在列式数据库中你可以只读取你需要的数据。例如,如果只需要读取100列中的5列,这将帮助你最少减少20倍的I/O消耗。
- 由于数据总是打包成批量读取的,所以压缩是非常容易的。同时数据按列分别存储这也更容易压缩。这进一步降低了I/O的体积。
- 由于I/O的降低,这将帮助更多的数据被系统缓存。
例如,查询«统计每个广告平台的记录数量»需要读取«广告平台ID»这一列,它在未压缩的情况下需要1个字节进行存储。如果大部分流量不是来自广告平台,那么这一列至少可以以十倍的压缩率被压缩。当采用快速压缩算法,它的解压速度最少在十亿字节(未压缩数据)每秒。换句话说,这个查询可以在单个服务器上以每秒大约几十亿行的速度进行处理。这实际上是当前实现的速度。
CPU
由于执行一个查询需要处理大量的行,因此在整个向量上执行所有操作将比在每一行上执行所有操作更加高效。同时这将有助于实现一个几乎没有调用成本的查询引擎。如果你不这样做,使用任何一个机械硬盘,查询引擎都不可避免的停止CPU进行等待。所以,在数据按列存储并且按列执行是很有意义的。
有两种方法可以做到这一点:
向量引擎:所有的操作都是为向量而不是为单个值编写的。这意味着多个操作之间的不再需要频繁的调用,并且调用的成本基本可以忽略不计。操作代码包含一个优化的内部循环。
代码生成:生成一段代码,包含查询中的所有操作。
这是不应该在一个通用数据库中实现的,因为这在运行简单查询时是没有意义的。但是也有例外,例如,MemSQL使用代码生成来减少处理SQL查询的延迟(只是为了比较,分析型数据库通常需要优化的是吞吐而不是延迟)。
请注意,为了提高CPU效率,查询语言必须是声明型的(SQL或MDX), 或者至少一个向量(J,K)。 查询应该只包含隐式循环,允许进行优化。
[转帖]什么是ClickHouse?的更多相关文章
- nginx负载均衡基于ip_hash的session粘帖
nginx负载均衡基于ip_hash的session粘帖 nginx可以根据客户端IP进行负载均衡,在upstream里设置ip_hash,就可以针对同一个C类地址段中的客户端选择同一个后端服务器,除 ...
- [转帖]网络协议封封封之Panabit配置文档
原帖地址:http://myhat.blog.51cto.com/391263/322378
- [转帖]零投入用panabit享受万元流控设备——搭建篇
原帖地址:http://net.it168.com/a2009/0505/274/000000274918.shtml 你想合理高效的管理内网流量吗?你想针对各个非法网络应用与服务进行合理限制吗?你是 ...
- 3d数学总结帖
3d数学总结帖,以下是对3d学习过程中数学知识的简单总结 角度值和弧度制的互转 Deg2Rad 角度A1转弧度A2 => A2=A1*PI/180 Rad2Deg 弧度A2转换角度A1 => ...
- [转帖]The Lambda Calculus for Absolute Dummies (like myself)
Monday, May 7, 2012 The Lambda Calculus for Absolute Dummies (like myself) If there is one highly ...
- [转帖]FPGA开发工具汇总
原帖:http://blog.chinaaet.com/yocan/p/5100017074 ----------------------------------------------------- ...
- [Android分享] 【转帖】Android ListView的A-Z字母排序和过滤搜索功能
感谢eoe社区的分享 最近看关于Android实现ListView的功能问题,一直都是小伙伴们关心探讨的Android开发问题之一,今天看到有关ListView实现A-Z字母排序和过滤搜索功能 ...
- AxureRP7.0各类交互效果汇总帖(转)
了便于大家参考,我把这段时间发布分享的所有关于AxureRP7.0的原型做了整理. 以下资源均有对应的RP源文件可以下载. 当然 ,其中有部分是需要通过完成解密游戏[攻略]才能得到下载地址或者下载密码 ...
- 未能加载文件或程序集“Newtonsoft.Json, Version=4.0.0.0, Culture=neutral, PublicKeyToken=30a [问题点数:40分,结帖人u010259408]
未能加载文件或程序集“Newtonsoft.Json, Version=4.0.0.0, Culture=neutral, PublicKeyToken=30a [问题点数:40分,结帖人u01025 ...
- 转帖-[教程] Win7精简教程(简易中度)2016年8月-0day
[教程] Win7精简教程(简易中度)2016年8月 0day 发表于 2016-8-19 16:08:41 https://www.itsk.com/thread-370260-1-1.html ...
随机推荐
- 使用NPOI导出Excel,并在Excel指定单元格插入图片
一.添加Nuget引用 二.弹框选择保存路径 string fileName = $"记录_{DateTime.Now.ToString("yyyyMMdd_HHmmss" ...
- 为什么vacuum后表还是继续膨胀?
摘要: 对于更新和删除操作频繁的表,会存在大量垃圾数据,导致磁盘空间的浪费和查询扫描时额外的IO开销,需要定期执行清理操作(vacuum)来控制行存表以及表上索引的膨胀.本文将对vacuum的原理以及 ...
- 初探语音识别ASR算法
摘要:语音转写文字ASR技术的基本概念与数学原理简介. 本文分享自华为云社区<新手语音入门(三): 语音识别ASR算法初探 | 编码与解码 | 声学模型与语音模型 | 贝叶斯公式 | 音素> ...
- 【Boost】CMake中引用Boost库
概述 在macOS开发时常常使用Boost库,若项目使用CMake进行组织管理和编译,需要掌握在CMake中实现Boost库的引用的基本语法.本片博客结合自己在实际使用过程中的经验进行总结,以期回顾和 ...
- #2054:A == B ?(水题坑人)
Problem Description Give you two numbers A and B, if A is equal to B, you should print "YES&quo ...
- AtCoder ARC 115 E - LEQ and NEQ (延迟标记线段树 or 笛卡尔积 + DP维护)
问题链接:Here 长度为 \(N\) 的数列 \(A_1,-,A_N\) .回答满足以下条件的长度 \(N\) 的数列 \(X_1,-,X_N\) 的个数除以 \(998244353\) 的余数. ...
- 第六届蓝桥杯C++C组 A~F题题解
蓝桥杯历年国赛真题汇总:Here 1. 分机号 X老板脾气古怪,他们公司的电话分机号都是3位数,老板规定,所有号码必须是降序排列,且不能有重复的数位.比如: 751,520,321 都满足要求,而, ...
- 揭秘 vivo 如何打造千万级 DAU 活动中台 - 启航篇
本文首发于 vivo互联网技术 微信公众号 链接: https://mp.weixin.qq.com/s/Ka1pjJKuFwuVL8B-t7CwuA作者:悟空中台研发团队 vivo大厦(南京) 一 ...
- 叮~OpenSCA社区拍了拍您并发来一份开源盛会邀请函
2023数字供应链安全大会(DSS 2023)将于8月10日在北京·国家会议中心举办.本次大会以"开源的力量"为主题,由悬镜安全主办,ISC互联网安全大会组委会.中国软件评测中心( ...
- kafka集群五、__consumer_offsets副本数修改
系列导航 一.kafka搭建-单机版 二.kafka搭建-集群搭建 三.kafka集群增加密码验证 四.kafka集群权限增加ACL 五.kafka集群__consumer_offsets副本数修改 ...