DeepViT:字节提出深层ViT的训练策略 | 2021 arxiv
作者发现深层ViT出现的注意力崩溃问题,提出了新颖的Re-attention机制来解决,计算量和内存开销都很少,在增加ViT深度时能够保持性能不断提高
来源:晓飞的算法工程笔记 公众号
论文: DeepViT: Towards Deeper Vision Transformer

Introduction
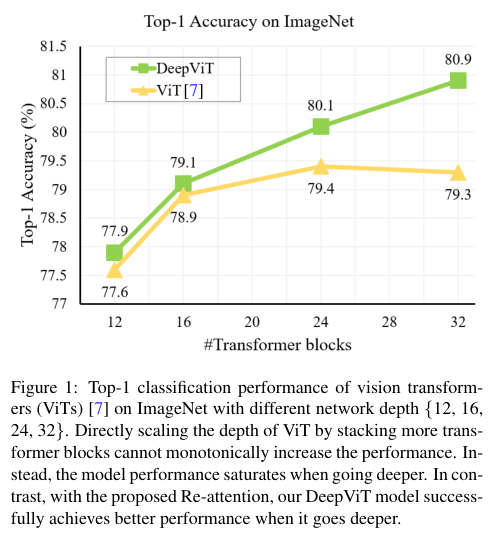
作者在ViT上效仿CNN堆叠更多层来提升性能的做法,但如图1所示,ViT的性能随着层数的增加会快速饱和。经过深入研究,作者发现这种缩放困难可能是由注意力崩溃问题引起。随着网络的深入,各层计算的注意力图逐渐变得相似,甚至在某些层之后几乎相同。这一事实表明,在ViT更深层中,self-attention机制无法有效地学习特征提取规律,阻碍了模型获得预期的性能提升。
为了解决注意力崩溃问题并有效地扩展ViT的深度,作者提出了简单而有效的Re-attention方法。通过可学习的方式,该方法能够在多头自注意力(MHSA)的多个Head间进行信息交换,重新生成注意力图。重新生成的注意力图能够增加层的多样性,而且额外增加的计算和内存成本可以忽略不计。
在没有任何额外的数据增强和正则化策略的情况下,只需用Re-attention替换ViTs中的MHSA模块,就可以训练非常深的ViT模型并得到相应的性能提升,如图2所示。
总体而言,论文的贡献如下:
- 深入研究ViT的行为,观察到ViT不能像CNN那样堆叠更多层中持续来提升性能,并且进一步确定了这种反直觉现象背后的根本原因为注意力崩溃。
- 提出了Re-attention,一种简单而有效的注意机制,通过在不同注意头之间的进行信息交换来生成新的注意力图。
- 第一个在ImageNet-1k上成功从零开始训练32层ViT并获得相应的性能提升,达到SOTA。
Revisiting Vision Transformer
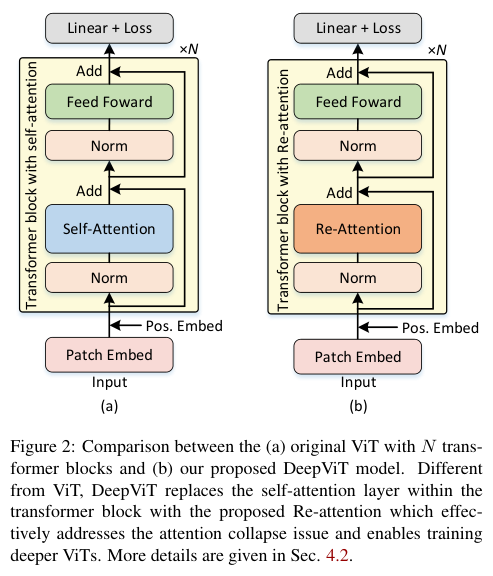
ViT模型如图2(a) 所示,由三个主要组件组成:用于Patch Embedding的线性层(即将高分辨率输入图像映射到低分辨率特征图),用于特征编码的多个包含MHSA和MLP的Transformer Block,用于分类分数预测的线性层。
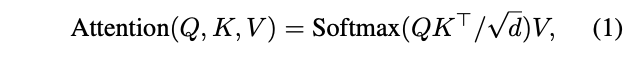
其中,最关键的MHSA层如公式1所示,也是Re-attention替换的目标。
Attention Collapse
作者对ViT随深度增加而变化的性能进行了系统研究。首先根据DeiT的设置将中间层维度和MHSA的Head数量分别固定为384和12,然后堆叠不同数量的transformer blocks(从12到32不等)来构建不同深度的ViT模型。如前面所说的,作者惊讶地发现分类准确率会随着模型的深入而缓慢提高并快速饱和,在使用24个transformer blocks后提升就停止了。这一现象表明,现有的ViT难以从更深层次的架构中获益。
这样的问题非常违反直觉,也值得探索。在CNN的早期开发阶段也观察到了类似的问题(即如何有效地训练深层模型),但后来被ResNet妥善解决了。通过更深入地研究transfromer的架构,作者认为自注意机制在ViT中起着关键作用,这使得它与CNN有显着不同。因此,作者首先研究自注意机制,观察其生成的注意力图如何随着模型的深入而变化
为了测量各层注意力图的变化,需计算不同层注意力图之间的相似度:
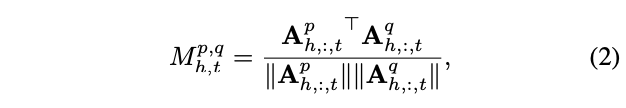
其中,\(M^{p,q}\)是层p和q的注意力图之间的余弦相似度矩阵,每个元素\(M^{p,q}_{h,t}\)衡量headh和tokent对应的层间注意力图的相似度。\(A^{∗}_{h,:,t}\) 是一个T维向量,表示输入token序列t对T个输出标记中的每一个的贡献程度。因此,\(M^{p,q}_{h,t}\)提供了关于token的权重如何从p层变化到q层的度量手段。当\(M^{p,q}_{h,t}\)等于1时,这意味着token序列t在层p和q中对self-attention的作用完全相同。
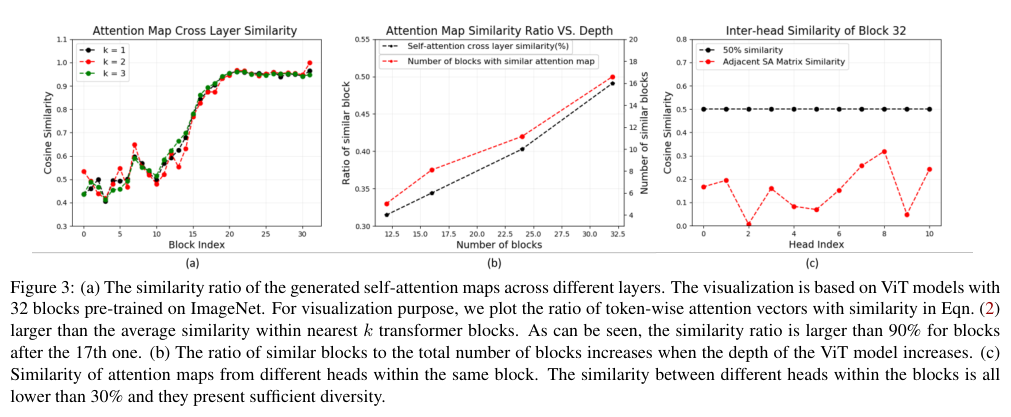
基于公式2,将ImageNet-1k上预训练32层ViT模型的所有注意力图之间的相似性进行可视化。如图3a所示,在第17层之后,相邻\(k\)层的注意力图的相似度大于90%,这表明后面学习的注意力图都是相似的,即注意力崩溃问题。
为了进一步验证不同深度的ViT是否存在这种现象,我们分别对12、16、24和32层的ViT进行了相同的实验,并计算了具有相似注意力图的块的数量。结果如图3b所示,当添加更多层时,相似注意力图的层数量与总层数的比率增加。

为了解注意力崩溃如何影响ViT模型的性能,作者基于32层ViT模型,比较最终输出特征与每个中间层输出余弦相似度。结果如图4所示,学习到的特征在第20层之后停止变化,而且注意力图相似度的增加与特征相似度之间存在密切的相关性。这一观察表明,注意力崩溃是造成ViT不可扩展问题的根本原因。
Re-attention for Deep ViT
将ViT扩展到更深的一个主要障碍是注意力崩溃问题,作者提出了两种解决方法,一种是增加自注意计算的中间维度,另一种是Re-attention机制。
Self-Attention in Higher Dimension Space
克服注意力崩溃的一种直接解决方案是增加每个token的embedding维度。增加维度能够增强每个token embedding的表达能力,从而编码更多信息,生成更加多样化的注意力图以及减少相似性。
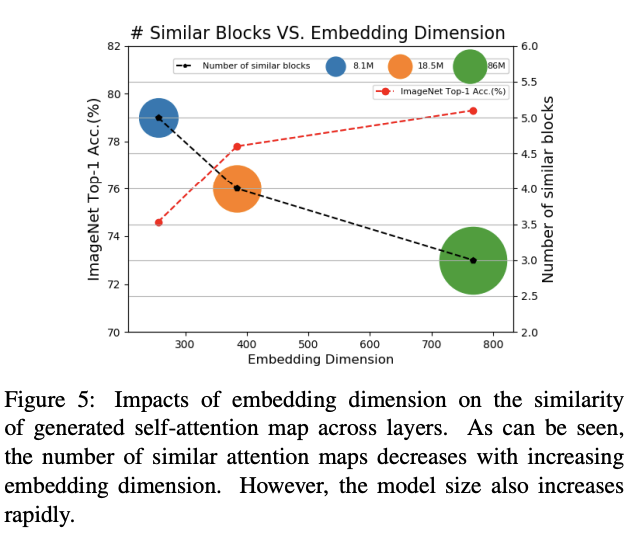
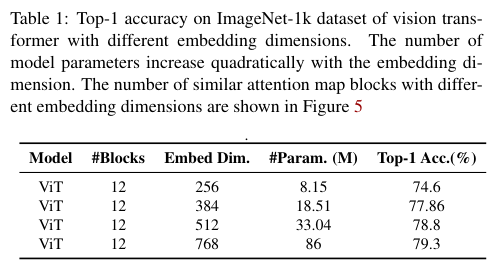
作者基于12层ViT进行了不同中间维度的快速实验,维度范围从256到768。如图5和表1所示,增加embedding维度能够减少具有相似注意力图的层数以及缓解注意力崩溃,模型性能也得到相应的提高。这验证了作者的核心假设,注意力崩溃是ViT扩展的主要瓶颈。尽管这个方法有效,但持续增加embedding维度会显著增加计算成本,而且带来的性能提升往往也会减弱。此外,更大的模型通常需要更多的数据进行训练,存在过拟合风险以及降低训练效率。
Re-attention
虽然不同transformer block之间的注意力图的相似性很高,但作者发现来自同一个Transformer block的不同Head的注意力图的相似性非常小,如图3c所示。实际上,同一自注意力层的不同Head主要关注输入token的不同方面。于是作者打算建立Head间交互来重新生成注意力图,使得训练的深层ViT的性能更优。

Re-attention使用Head的注意力图作为基础,通过动态聚合生成一组新的注意力图。为了实现这一点,首先定义一个可学习的变换矩阵\(\Theta\in\mathbb{R}^{H\times H}\),在乘以V之前,使用该矩阵混合多个Head的注意力图重新生成新的注意力图。具体来说,Re-attention可定义为以下公式:
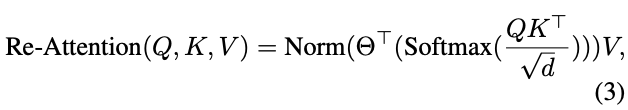
其中变换矩阵\(\Theta\)沿Head
维度乘以自注意力图A,Norm是归一化函数,用于减少每层的方差,\(\Theta\)是可端到端学习的。
Re-attention 的优点有两个:
- 与其他注意力增强方法相比(随机丢弃注意力图元素或调节
SoftMax温度),Re-attention利用Head之间的交互来收集互补信息,可以更好地提高注意力图的多样性。 - Re-attention高效且易于实现,与原始的自注意力相比,只需要几行代码和可忽略不计的计算开销,比增加嵌入维度的方法更高效。
Experiments
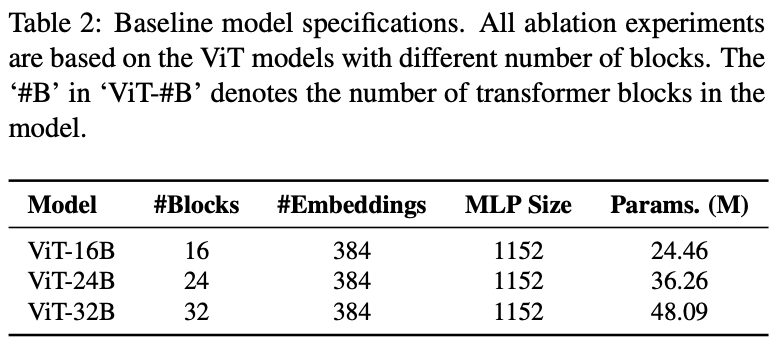
实验的基础模型配置,输入图片大小都是224x224。
More Analysis on Attention Collapse
Attention reuse
作者在24层和32层ViT模型上进行注意力复用的实验,将一个block的的注意力图直接共享给之后的所有块,block的选择为最后一个注意力图与相邻层的相似度小于90%的block。更多实现细节可以在补充材料中找到。
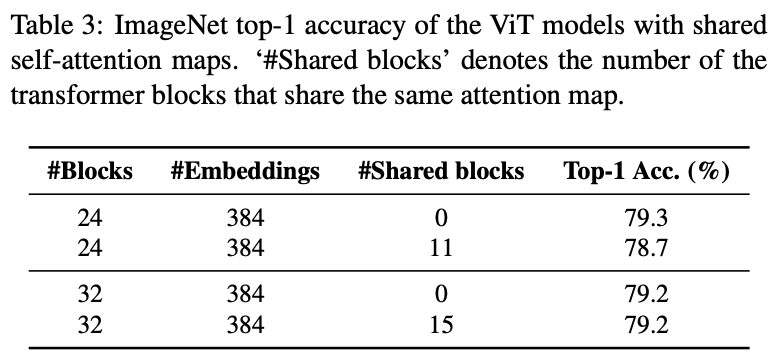
结果如表3所示,共享注意力图的性能下降并不明显,这意味着注意力崩溃问题确实存在。当模型很深时,添加更多层的效率低下。
Visualization

原始MHSA和Re-attention的注意力图可视化如图6所示。原始的MHSA学在较早层中主要关注相邻token之间的局部关系,并且随着层的深入逐渐覆盖更多token,最后在深层中具有高度相似性全局平均注意力图。在添加Re-attention后,深层的注意力图保持了多样性,并且与相邻层具有较小的相似性
Analysis on Re-attention
Re-attention v.s. Self-attention
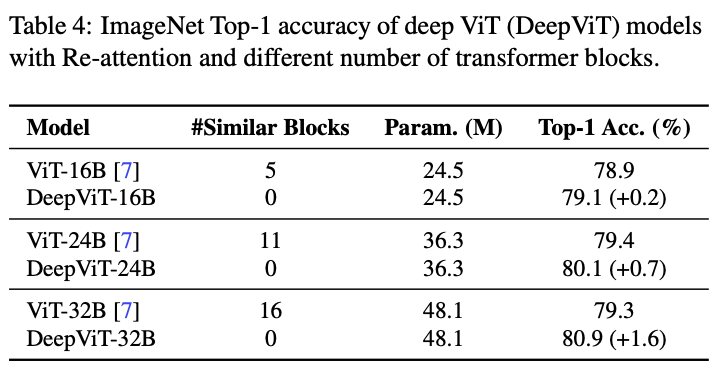
不同层数ViT上替换Re-attention对比。
Comparison to adding temperature in self-attention
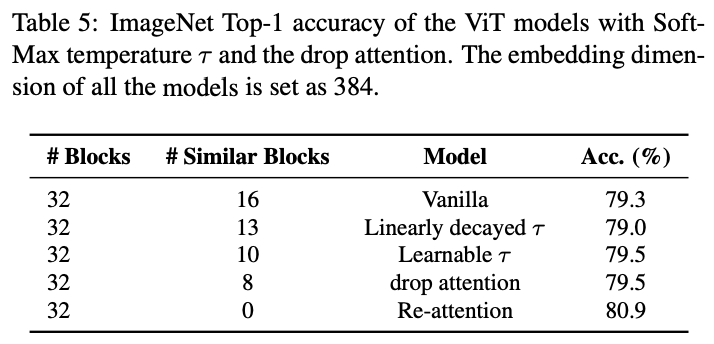
对比不同的缓解注意力图平滑问题的策略。
Comparison to dropping attentions
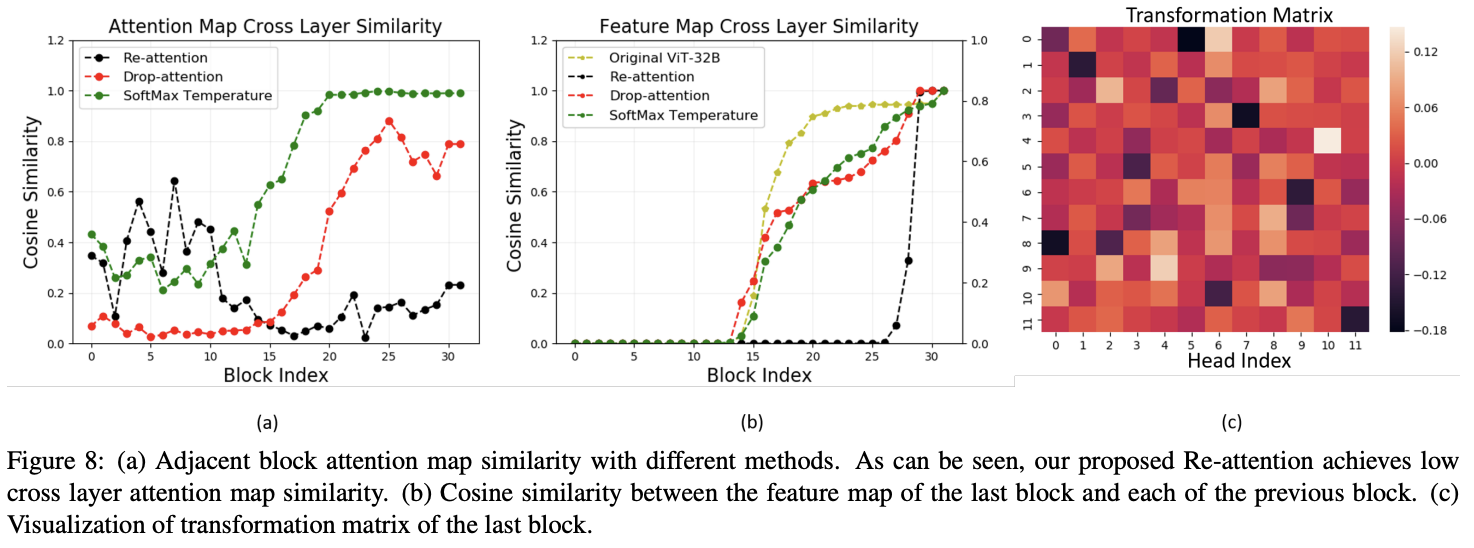
对比注意力图dropout以及温度调节对相似性的影响。
Comparison with other SOTA models
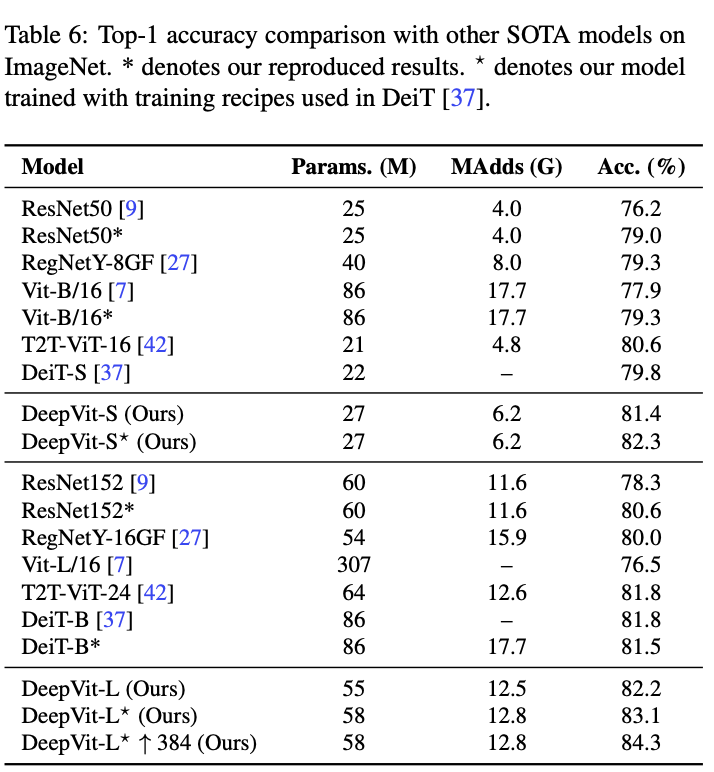
对比SOTA方法。
Conclusion
作者发现深层ViT出现的注意力崩溃问题,提出了新颖的Re-attention机制来解决,计算量和内存开销都很少,在增加ViT深度时能够保持性能不断提高。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

DeepViT:字节提出深层ViT的训练策略 | 2021 arxiv的更多相关文章
- 伯克利、OpenAI等提出基于模型的元策略优化强化学习
基于模型的强化学习方法数据效率高,前景可观.本文提出了一种基于模型的元策略强化学习方法,实践证明,该方法比以前基于模型的方法更能够应对模型缺陷,还能取得与无模型方法相近的性能. 引言 强化学习领域近期 ...
- Bert不完全手册3. Bert训练策略优化!RoBERTa & SpanBERT
之前看过一条评论说Bert提出了很好的双向语言模型的预训练以及下游迁移的框架,但是它提出的各种训练方式槽点较多,或多或少都有优化的空间.这一章就训练方案的改良,我们来聊聊RoBERTa和SpanBER ...
- CSG:清华大学提出通过分化类特定卷积核来训练可解释的卷积网络 | ECCV 2020 Oral
论文提出类特定控制门CSG来引导网络学习类特定的卷积核,并且加入正则化方法来稀疏化CSG矩阵,进一步保证类特定.从实验结果来看,CSG的稀疏性能够引导卷积核与类别的强关联,在卷积核层面产生高度类相关的 ...
- 腾讯推出超强少样本目标检测算法,公开千类少样本检测训练集FSOD | CVPR 2020
论文提出了新的少样本目标检测算法,创新点包括Attention-RPN.多关系检测器以及对比训练策略,另外还构建了包含1000类的少样本检测数据集FSOD,在FSOD上训练得到的论文模型能够直接迁移到 ...
- 知识图谱顶会论文(KDD-2022) kgTransformer:复杂逻辑查询的预训练知识图谱Transformer
论文标题:Mask and Reason: Pre-Training Knowledge Graph Transformers for Complex Logical Queries 论文地址: ht ...
- BERT总结:最先进的NLP预训练技术
BERT(Bidirectional Encoder Representations from Transformers)是谷歌AI研究人员最近发表的一篇论文:BERT: Pre-training o ...
- RF的特征子集选取策略(spark ml)
支持连续变量和类别变量,类别变量就是某个属性有三个值,a,b,c,需要用Feature Transformers中的vectorindexer处理 上来是一堆参数 setMaxDepth:最大树深度 ...
- ECCV 2018 | 旷视科技提出统一感知解析网络UPerNet,优化场景理解
全球计算机视觉三大顶会之一 ECCV 2018(European Conference on Computer Vision)即将于 9 月 8 -14 日在德国慕尼黑拉开帷幕.届时,旷视首席科学家孙 ...
- DeepMind提出新型超参数最优化方法:性能超越手动调参和贝叶斯优化
DeepMind提出新型超参数最优化方法:性能超越手动调参和贝叶斯优化 2017年11月29日 06:40:37 机器之心V 阅读数 2183 版权声明:本文为博主原创文章,遵循CC 4.0 BY ...
- 【论文笔记】张航和李沐等提出:ResNeSt: Split-Attention Networks(ResNet改进版本)
github地址:https://github.com/zhanghang1989/ResNeSt 论文地址:https://hangzhang.org/files/resnest.pdf 核心就是: ...
随机推荐
- java的jdbc插入的时候,遇到null情况报错问题
分析原因: 在执行SQL时MyBatis会自动通过对象中的属性给SQL中参数赋值,它会自动将Java类型转换成数据库的类型.而一旦传入的是null它就无法准确判断这个类型应该是什么,就有可能将类型转换 ...
- C语言:if语句嵌套应用(小剧场)
#include <stdio.h> int main() { int num,i; printf("一天Jackson.W打开了电脑想学习C语言\n"); print ...
- The attempt was made from the following location: com.ruoyi.framework.config.ResourcesConfig.corsFilter(ResourcesConfig.java:57)
报错信息: 8:42:12.529 [restartedMain] ERROR o.s.b.w.e.t.TomcatStarter - [onStartup,61] - Error starting ...
- 4G EPS 中的 Control Plane
目录 文章目录 目录 前文列表 控制平面 归属环境部分 无线接入网络部分 核心网络 EPS CP 中的 GTP-C UP 中的 GTP-U Tunnel 两端的 F-TEID 需要通过 CP 的信令流 ...
- Linux安装ElastSearch
Linux安装ES 准备好Linux系统,软件安装前需要对当前系统做一些优化配置 系统配置修改 一.内存优化 在/etc/sysctl.conf添加如下内容: fs.file-max=655360 系 ...
- 14个Flink SQL性能优化实践分享
本文分享自华为云社区<Flink SQL性能优化实践> ,作者:超梦. 在大数据处理领域,Apache Flink以其流处理和批处理一体化的能力,成为许多企业的首选.然而,随着数据量的增长 ...
- MVCC(多版本并发控制)详解
在 MySQL InnoDB存储引擎下,RC.RR 基于 MVCC 进行并发事务控制, MVCC 是基于"数据版本"对并发事务进行访问 用一个例子来解释一下,下面是一张事务执行流程 ...
- linux使用过程中遇到的常见问题
1 xxxx is not in the sudoers file. This incident will be reported. 解决方式:https://www.cnblogs.com/xym4 ...
- Idea克隆检出git项目
1.我这里假设你已经安装好了Idea和Git环境 2. .
- 增补博客 第八篇 python 中国大学排名数据分析与可视化
[题目描述]以软科中国最好大学排名为分析对象,基于requests库和bs4库编写爬虫程序,对2015年至2019年间的中国大学排名数据进行爬取:(1)按照排名先后顺序输出不同年份的前10位大学信息, ...