Hadoop -- HDFS 读写数据
一、HDFS读写文件过程
1.读取文件过程
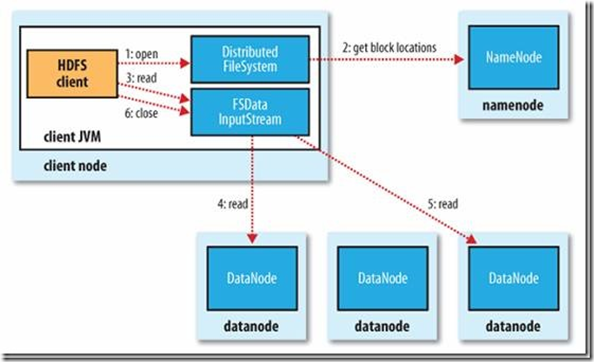
1) 初始化FileSystem,然后客户端(client)用FileSystem的open()函数打开文件
2) FileSystem用RPC调用元数据节点,得到文件的数据块信息,对于每一个数据块,元数据节点返回保存数据块的数据节点的地址。
3) FileSystem返回FSDataInputStream给客户端,用来读取数据,客户端调用stream的read()函数开始读取数据。
4) DFSInputStream连接保存此文件第一个数据块的最近的数据节点,data从数据节点读到客户端(client)
5) 当此数据块读取完毕时,DFSInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。
6) 当客户端读取完毕数据的时候,调用FSDataInputStream的close函数。
7) 在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。
8) 失败的数据节点将被记录,以后不再连接。
2.写文件过程
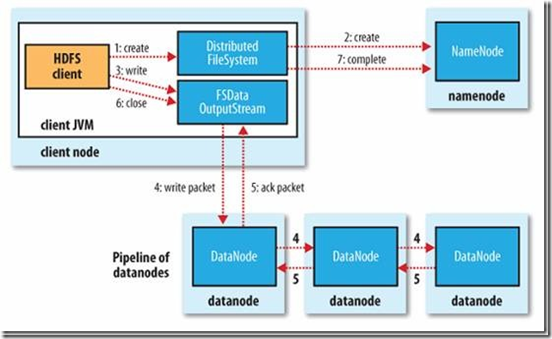
1) 初始化FileSystem,客户端调用create()来创建文件
2) FileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件,元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。
3) FileSystem返回DFSOutputStream,客户端用于写数据,客户端开始写入数据。
4) DFSOutputStream将数据分成块,写入data queue。data queue由Data Streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个pipeline里。Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。
5) DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。
6) 当客户端结束写入数据,则调用stream的close函数。此操作将所有的数据块写入pipeline中的数据节点,并等待ack queue返回成功。最后通知元数据节点写入完毕。
7) 如果数据节点在写入的过程中失败,关闭pipeline,将ack queue中的数据块放入data queue的开始,当前的数据块在已经写入的数据节点中被元数据节点赋予新的标示,则错误节点重启后能够察觉其数据块是过时的,会被删除。失败的数据节点从pipeline中移除,另外的数据块则写入pipeline中的另外两个数据节点。元数据节点则被通知此数据块是复制块数不足,将来会再创建第三份备份。
啦啦啦
Hadoop -- HDFS 读写数据的更多相关文章
- HDFS读写数据块--${dfs.data.dir}选择策略
最近工作需要,看了HDFS读写数据块这部分.不过可能跟网上大部分帖子不一样,本文主要写了${dfs.data.dir}的选择策略,也就是block在DataNode上的放置策略.我主要是从我们工作需要 ...
- 大数据:Hadoop(HDFS 读写数据流程及优缺点)
一.HDFS 写数据流程 写的过程: CLIENT(客户端):用来发起读写请求,并拆分文件成多个 Block: NAMENODE:全局的协调和把控所有的请求,提供 Block 存放在 DataNode ...
- HDFS读写数据流程
HDFS的组成 1.NameNode:存储文件的元数据,如文件名,文件目录结构,文件属性(创建时间,文件权限,文件大小) 以及每个文件的块列表和块所在的DataNode等.类似于一本书的目录功能. 2 ...
- HDFS 读写数据流程
一.上传数据 二.下载数据 三.读写时的节点位置选择 1.网络节点距离(机架感知) 下图中: client 到 DN1 的距离为 4 client 到 NN 的距离为 3 DN1 到 DN2 的距离为 ...
- HDFS读写数据过程
一.文件的打开 1.1.客户端 HDFS打开一个文件,需要在客户端调用DistributedFileSystem.open(Path f, int bufferSize),其实现为: public F ...
- Hdfs读写数据出错
1.Hdfs读数据出错:若在读数据的过程中,客户端和DataNode的通信出现错误,则会尝试连接下一个 包含次文件块的DataNode.同时记录失败的DataNode,此后不再被连接. 2.Hdfs在 ...
- [Hadoop]HDFS机架感知策略
HDFS NameNode对文件块复制相关所有事物负责,它周期性接受来自于DataNode的HeartBeat和BlockReport信息,HDFS文件块副本的放置对于系统整体的可靠性和性能有关键性影 ...
- 大数据系列文章-Hadoop的HDFS读写流程(二)
在介绍HDFS读写流程时,先介绍下Block副本放置策略. Block副本放置策略 第一个副本:放置在上传文件的DataNode:如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点. 第二 ...
- Hadoop HDFS (3) JAVA訪问HDFS之二 文件分布式读写策略
先把上节未完毕的部分补全,再剖析一下HDFS读写文件的内部原理 列举文件 FileSystem(org.apache.hadoop.fs.FileSystem)的listStatus()方法能够列出一 ...
随机推荐
- 喵哈哈村的魔法考试 Round #19 (Div.2) 题解
题解: 喵哈哈村的魔力源泉(1) 题解:签到题. 代码: #include<bits/stdc++.h> using namespace std; int main(){ long lon ...
- sql ,内连接,外连接,自然连接等各种连接
1.内联接(典型的联接运算,使用像 = 或 <> 之类的比较运算符).包括相等联接和自然联接. 内联接使用比较运算符根据每个表共有的列的值匹配两个表中的行.例如,检索 students和c ...
- How to change the implementation (detour) of an externally declared function
原文地址:http://stackoverflow.com/questions/6905287/how-to-change-the-implementation-detour-of-an-extern ...
- Std::map too few template arguments
在上述的代码中,红色波浪线的部分编译的时候报错: error C2976: 'std::map' : too few template arguments 换成std::map<std::str ...
- hash bucket
什么是bucket bucket的英文解释: Hash table lookup operations are often O(n/m) (where n is the number of objec ...
- 微软BI 之SSIS 系列 - 理解Data Flow Task 中的同步与异步, 阻塞,半阻塞和全阻塞以及Buffer 缓存概念
开篇介绍 在 SSIS Dataflow 数据流中的组件可以分为 Synchronous 同步和 Asynchronous 异步这两种类型. 同步与异步 Synchronous and Asynchr ...
- windows性能监控
see also:http://www.cnblogs.com/upDOoGIS/archive/2010/11/19/1881970.html CPU Processor : % Processor ...
- Java中多环境Logback配置与ELK日志发送
Java中多环境Logback配置与ELK日志发送 一.项目基于SpringBoot实现,引入SpringBoot相关库后,本文还要讲上传到ELK的Logstash,所以需要在pom.xml中加入 ...
- oracle数据库将一列的值拼接成一行,并且各个值之间用逗号隔开
使用场景:把某一列值转换为逗号分隔的字符串 例子:比如查询所有的的表空间如下,现在要获得所有的表空间用逗号分隔的字符串(比如rman duplicate的时候skip表空间) SQL> sele ...
- 基于Centos搭建Django 环境搭建
CentOS 7.2 64 位操作系统 安装 Django 先安装 PIP,再通过 PIP 安装 Django 安装 PIP cd /data; mkdir tmp; cd tmp; wget htt ...