系统学习NLP(二十一)--SWEM
https://blog.csdn.net/App_12062011/article/details/88655589
这篇发表在 ACL 2018 上的论文来自于杜克大学 Lawrence Carin 教授的实验室。文章重新审视了 deep learning models(例如 CNN, LSTM)在各类 NLP 任务中的必要性。
通过大量的实验探究(17 个数据集),作者发现对于大多数的 NLP 问题,在 word embedding 矩阵上做简单的 pooling 操作就达到了比 CNN encoder 或者 LSTM encoder 更好的的结果。
■ 论文 | Baseline Needs More Love: On Simple Word-Embedding-Based Models and Associated Pooling Mechanisms
■ 链接 | https://www.paperweekly.site/papers/1987
■ 源码 |https://github.com/dinghanshen/SWEM
论文详细比较了直接在词向量上进行池化的简单模型和主流神经网络模型(例如 CNN 和 RNN)在 NLP 多个任务上的效果。实验结果表明,在很多任务上简单的词向量模型和神经网络模型(CNN 和 LSTM)的效果相当,有些任务甚至简单模型更好。下面是我对这篇论文的阅读笔记。
引言
在 NLP 领域,词向量(word embedding)已经受到了研究者们的广泛关注和应用。它通过大量的无标签数据将每个词表示成一个固定维度的向量。相比传统的独热(one-hot)表示,词向量具有低维紧密的特点,并能学习到丰富的语义和句法信息。目前代表性的词向量工作有word2vec[1]和GloVe[2]。
在 NLP 领域,使用词向量将一个变长文本表示成一个固定向量的常用方法有:1)以词向量为输入,使用一个复杂的神经网络(CNN,RNN 等)来进行文本表示学习;2)在词向量的基础上,直接简单的使用按元素求均值或者相加的简单方法来表示。
对于复杂神经网络方法,模型复杂计算量大耗时。该论文通过大量实验发现,基于词向量的简单池化模型对于大多数的 NLP 问题,已经表现得足够好,有时甚至效果超过了复杂的神经网络模型。
方法
该文对比的主流神经网络模型为:LSTM 和 CNN。对于 LSTM 特点在于使用门机制来学习长距离依赖信息,可以认为考虑了词序信息。对于 CNN 特点是利用滑动窗口卷积连续的词特征,然后通过池化操作学习到最显著的语义特征。 对于简单的词向量模型(Simple word-embedding model,SWEM),作者提出了下面几种方法。

SWEM-aver:就是平均池化,对词向量的按元素求均值。这种方法相当于考虑了每个词的信息。
SWEM-max:最大池化,对词向量每一维取最大值。这种方法相当于考虑最显著特征信息,其他无关或者不重要的信息被忽略。
SWEM-concat:考虑到上面两种池化方法信息是互补的,这种变体是对上面两种池化方法得到的结果进行拼接。
SWEM-hier:上面的方法并没有考虑词序和空间信息,提出的层次池化先使用大小为 n 局部窗口进行平均池化,然后再使用全局最大池化。该方法其实类似我们常用的 n-grams 特征。
接下来对比一下 SWEM 和神经网络模型结构。可以看到 SWEM 仅对词向量使用池化操作,并没有额外的参数,且可以高度并行化。

实验结果与分析
实验中,使用了 300 维的 GloVe 词向量,对于未登录词按照均匀分布进行初始化。最终的分类器使用了多层感知机 MLP 进行分类。在文档分类,文本序列匹配和句子分类三大任务,共 17 个数据集上进行了实验并进行了详细的分析。
文档分类
实验中的文档分类任务能被分为三种类型:主题分类,情感分析和本体分类。实验结果如下:

令人惊奇的是在主题分类任务上,SWEM 模型获得了比 LSTM 和 CNN 更好的结果,特别是 SWEM-concat 模型的效果甚至优于 29 层的 Deep CNN。在本体分类任务上也有类似的趋势。有趣的是对于情感分析任务,CNN 和 LSTM 效果要好于不考虑词序信息的 SWEM 模型。对于考虑了词序和空间信息的 SWEM-hier 取得了和 CNN/LSTM 相当的结果。这可能是情感分析任务需要词序信息。例如“not really good”和“really not good”的情感等级是不一样的。
在大多数任务上 SWEM-max 的方法略差于 SWEM-aver,但是它提供了互补的信息,所以 SWEM-concat 获得了更好的结果。更重要的是,SWEM-max 具有很强的模型解释性。
论文在 Yahoo 数据集上训练了 SWEM-max 模型(词向量随机初始化)。然后根据训练学习后的词向量中的每一维的值画了直方图,如下图 1:

可以看到相比与 GloVe,SWEM-max 学习出来的词向量是十分稀疏的,这说明在预测文本时,模型只依靠一些关键词,这就增加了模型的解释性。论文在整个词汇表中根据词向量维度挑选出了一个维度中值最大的 5 个词展示在表 3 中。可以看到每个维度选出的词是同一个主题相关的。甚至模型可以学到没有标签信息的结构,例如表 3 中的“Chemistry”,在数据集中是没有 chemistry 标签的,它属于 science 主题。
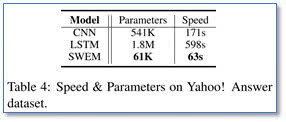
在模型时间上,SWEM 模型要比 CNN 和 LSTM 都高效。
文本序列匹配
在句子匹配问题的实验室中,主要包括自然语言推理,问答中答案句选择和复述识别任务。实验结果如下:

可以看到除了 WikiQA 数据集,其他数据集上,SWEM 模型获得了比 CNN 和 LSTM 更好的结果。这可能是因为在当匹配自然语言句子时,在大多数情况下,只需要使用简单模型对两个序列之间在单词级别上进行对比就足够了。从这方面也可以看出,词序信息对于句子匹配的作用比较小。此外简单模型比 LSTM 和 CNN 更容易优化。
句子分类
相比与前面的文档分类,句子分类任务平均只有 20 个词的长度。实验结果如下:

在情感分类任务上,和前面文档分类的实验结果一样,SWEM 效果差于 LSTM 和 CNN,在其他两个任务上,效果只是略差于 NN 模型。相比与前面的文档分类,在短句子分类上 SWEM 的效果要比长文档的分类效果要差。这也可能是由于短句中词序信息更重要。
此外,论文还在附加材料中补充了对序列标注任务的实验,实验结果如下:

可以看到对于词序敏感的序列标注任务,SWEM 的效果明显要差于 CNN 和 RNN。
词序信息的重要性
从上面可以看到,SWEM 模型的一个缺点在于忽略了词序信息,而 CNN 和 LSTM 模型能够一定程度的学习词序信息。那么在上述的这些任务中,词序信息到底有多重要?
为了探索这个问题,该文将训练数据集的词序打乱,并保持测试集的词序不变,就是为了去掉词序信息。然后使用了能够学习词序信息 LSTM 模型进行了实验,实验结果如下:

令人惊奇地发现,在 Yahoo 和 SNLI 数据集(也就是主题分类和文本蕴涵任务)上,在乱序训练集上训练的 LSTM 取得了和原始词序相当的结果。这说明词序信息对这两个问题并没有明显的帮助。但是在情感分析任务上,乱序的 LSTM 结果还是有所下降,说明词序对于情感分析任务还是比较重要。
再来看看 SWEM-hier 在情感分析上的效果,相比与 SWEM 其他模型,SWEM-hier 相当于学习了 n-gram 特征,保留了一定的局部词序信息。在两个情感任务上效果也是由于其他 SWEM 模型,这也证明了 SWEM-hier 能够学习一定的词序信息。
其他实验
除了上述实验,该文还设置了一些实验在说明 SWEM 的性能。对于之前的使用非线性的 MLP 作为分类器,替换成了线性分类器进行了实验。在 Yahoo(从 73.53% 到 73.18%)和 Yelp P(93.76% 到 93.66%)数据集上 SWEM 的效果并未明显下降。这也说明了 SWEM 模型能够抽取鲁棒、有信息的句子表示。
该文还在中文数据集上进行了实验,实验结果表明层次池化比最大和平均池化更适合中文文本分类,这样暗示了中文可能比英文对词序更加敏感。
在附加材料中,该文还用 SWEM-concat 模型在 Yahoo 数据集上对词向量维度(从 3 维到 1000 维)进行了实验,这里词向量使用随机初始化。

可以看到高的维度一般效果会更好一些,因为能够表示更丰富的语义信息。但是,可以看到词向量在 10 维的时候已经可以达到和 1000 维相当的效果。其实这也和论文[3]的结果比较一致,在一些任务上小维度的词向量效果也已经足够好了。
此外,论文还对训练集规模对模型效果影响进行了实验。在 Yahoo 和 SNLI 数据集上分别取不同比例的训练集对模型进行训练测试,结果如下图:

可以看到当标注训练集规模比较小时,简单的 SWEM 模型的效果更好,这可能也是 CNN 和 LSTM 复杂模型在小规模训练数据上容易过拟合导致的。
总结
该论文展示了在词向量上仅使用池化操作的简单模型 SWEM 的性能,在多个 NLP 任务数据集上进行了实验,比较了 SWEM 和目前主流的 NN 模型(CNN 和 LSTM)性能。
实验发现,SWEM 这样简单的基线系统在很多任务上取得了与 NN 相当的结果,实验中的一些总结如下:
1. 简单的池化操作对于长文档(上百个词)表示具有不错的表现,而循环和卷积操作对于短文本更有效;
2. 情感分析任务相比主题文本分类任务对词序特征更敏感,但是该文提出的一种简单的层次池化也能够学习一定的词序信息,和 LSTM/CNN 在情感分析任务上取得了相当的结果;
3. 对于句子匹配问题,简单的池化操作已经展现出了与 LSTM/CNN 相当甚至更好的性能;
4. 对于 SWEM-max 模型,可以通过对词向量维度的分析得到较好的模型解释;
5. 在一些任务上,词向量的维度有时在低维已经足够好;
6. 在标注训练集规模小的时候,简单的 SWEM 模型可能更加鲁棒、获得更好的表现。
总的来说,我们在进行研究时,有时为了让模型学习到更为丰富的信息,会把模型设计得十分复杂,但是这篇论文通过实验告诉了我们,简单的基线系统也能够获得很不错的表现。当我们做具体任务时,应该根据具体需求来选择设计模型(模型效果,模型复杂度,模型运行时间等的权衡),简单有效的系统也应该受到关注。
参考文献
[1] Mikolov, Tomas, et al. "Distributed representations of words and phrases and their compositionality." Advances in neural information processing systems. 2013.
[2] Pennington, Jeffrey, Richard Socher, and Christopher Manning. "Glove: Global vectors for word representation." Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 2014.
[3] Lai, Siwei, et al. "How to generate a good word embedding." IEEE Intelligent Systems 31.6 (2016): 5-14.
系统学习NLP(二十一)--SWEM的更多相关文章
- 学习笔记:CentOS7学习之二十一: 条件测试语句和if流程控制语句的使用
目录 学习笔记:CentOS7学习之二十一: 条件测试语句和if流程控制语句的使用 21.1 read命令键盘读取变量的值 21.1.1 read常用见用法及参数 21.2 流程控制语句if 21.2 ...
- python3.4学习笔记(二十一) python实现指定字符串补全空格、前面填充0的方法
python3.4学习笔记(二十一) python实现指定字符串补全空格.前面填充0的方法 Python zfill()方法返回指定长度的字符串,原字符串右对齐,前面填充0.zfill()方法语法:s ...
- (C/C++学习笔记) 二十一. 异常处理
二十一. 异常处理 ● 异常的概念 程序的错误通常包括:语法错误.逻辑错误.运行异常. 语法错误指书写的程序语句不合乎编译器的语法规则,这种错误在编译.连接时由编译器指出. 逻辑错误是指程序能顺利运行 ...
- 系统学习 Java IO (十一)----打印流 PrintStream
目录:系统学习 Java IO---- 目录,概览 PrintStream 类可以将格式化数据写入底层 OutputStream 或者直接写入 File 对象. PrintStream 类可以格式化基 ...
- Java I/O系统学习系列二:输入和输出
编程语言的I/O类库中常使用流这个抽象概念,它代表任何有能力产出数据的数据源对象或者是有能力接收数据的接收端对象.“流”屏蔽了实际的I/O设备中处理数据的细节. 在这个系列的第一篇文章:<< ...
- Java基础学习笔记二十一 多线程
多线程介绍 学习多线程之前,我们先要了解几个关于多线程有关的概念.进程:进程指正在运行的程序.确切的来说,当一个程序进入内存运行,即变成一个进程,进程是处于运行过程中的程序,并且具有一定独立功能. 线 ...
- android 学习随笔二十一(内容提供者 )
一.内容提供者* 应用的数据库是不允许其他应用访问的* 内容提供者的作用就是让别的应用访问到你的私有数据* 自定义内容提供者,继承ContentProvider类,重写增删改查方法,在方法中写增删改查 ...
- Java学习笔记二十一:Java面向对象的三大特性之继承
Java面向对象的三大特性之继承 一:继承的概念: 继承是java面向对象编程技术的一块基石,因为它允许创建分等级层次的类. 继承就是子类继承父类的特征和行为,使得子类对象(实例)具有父类的实例域和方 ...
- Linux系统学习之 二:新手必须掌握的Linux命令2
2018-10-03 22:20:48 一.文件目录管理命令 1.touch 命令 用于创建空白文件或设置文件的时间,格式为“touch [选项] [文件]”. 参数: -a :仅修改“读取时间(at ...
随机推荐
- 【splunk】用正则表达式提取字段
设input输入数据为 http://192.168.23.121/xxx 想提取出里面的ip,可以用rex source="xxx.csv" |rex field=input ...
- 【linux】crontab失效
在linux上,crontab任务全部使用完整路径,但是任务无效. 检测crontab 服务是否启动, /etc/init.d/cron status /etc/init.d/cron restart
- java uitl
Random类 //生成随机数 https://i.cnblogs.com/EditPosts.aspx?opt=1
- Fiddler抓包7-post请求(json)
前言上一篇讲过get请求的参数都在url里,post的请求相对于get请求多了个body部分,本篇就详细讲解下body部分参数的几种形式. 一.body数据类型 常见的post提交数据类型有四种: 1 ...
- python 全栈开发,Day135(爬虫系列之第2章-BS和Xpath模块)
一.BeautifulSoup 1. 简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: ''' Beautiful Soup提供一些简单 ...
- ngrinder的简介与基本使用(转载:https://www.jianshu.com/p/f336180806cc)
nGrinder简介 nGrinder是基于Grinder开源项目,由NHN公司的开发团队进行了重新设计和完善.nGrinder是一款非常易用,有简洁友好的用户界面和controller-agent分 ...
- SimInfo获取(MCC, MNC, PLMN)
String NUMERIC = getSIMInfo(); protected String getSIMInfo() { TelephonyManager iPhoneManager = (Tel ...
- C#编程的语法积累(一)
1.自动属性 之前的实现方式: private int id; public int Id { set {id = value;} get {return id;} } 现在可通过自动属性实现: pu ...
- openstack基础环境准备(一)
一.环境介绍 操作系统 ip地址 主机名 服务 centos7.5 192.168.56.11 linux-node1 控制节点 centos7.5 192.168.56.12 linux-node2 ...
- 047 大数据下的java client连接JDBC
1.前提 启动hiveserver2服务 url,username,password. 2.官网 3.程序 4.结果 emp的第一列与第二列 5.源程序 package com.cj.it.hiveU ...