最近对latin-1这个字符集产生了不少好感
【简介】
最近我要解析一个数据库中间件的日志、这个中间件会在日志中记录SQL发往的后台DB ,执行耗时,对应的SQL;中间件直接把SQL写到
了日志中去,并没有对SQL进行适当的编码转换;理想情况下这个也不会有什么问题,不幸的是我就面对着这种情况,client的发给中间件
的SQL有可能是"utf-8",也有可能是"gbk",也有可能是"gb2132";所以使用中间件的日志文件用任何一种编码方式都不成正确的解码它,
幸运的是我要做的工作只要解决出日志中所涉及到的数据库名和表名就行,所以我并不一定要完全解码这个文件。
【复现一下那个中间件写日志的大致逻辑】
以下我会用python代码来描述上面的情况,可以看到对于同一个文件以不同的编码写入了内容
with open('proxy_backup_sql.log','bw') as user_log_hander:
user_log_hander.write("192.186.100.10 | 0.012 | select id from tempdb.person where name='张三'; \n".encode('utf8'))
user_log_hander.write("192.186.100.10 | 0.012 | select id from tempdb.person where name='杨白劳'; \n".encode('gbk'))
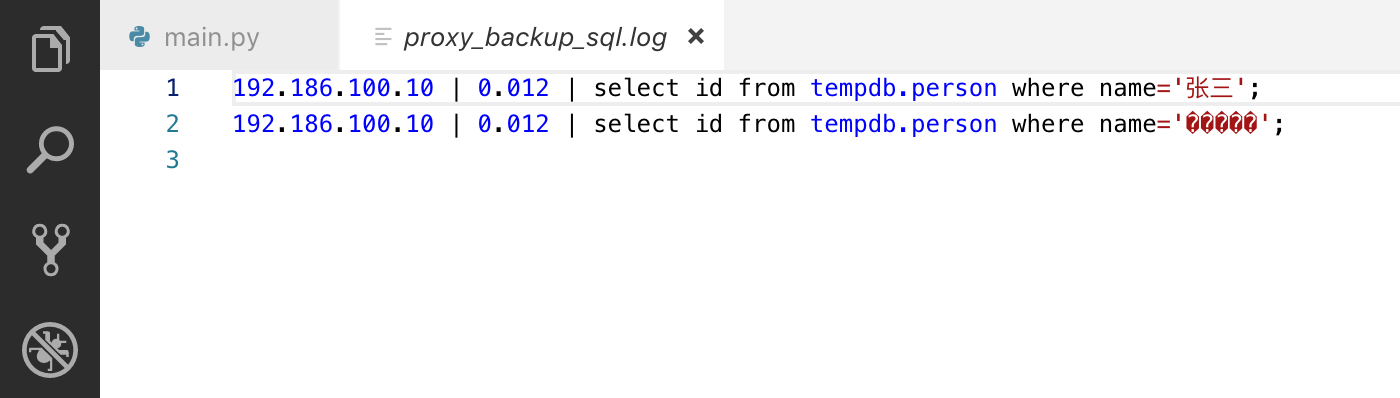
对于上面的情况不管你是用utf-8 还是用gbk打开文件它们会乱码的、
【用什么编码都是不可能正常打开这个文件的】
1、UTF8打开
with open('proxy_backup_sql.log','r',encoding='utf8') as proxy_backup_log_handler:
for line in proxy_backup_log_handler:
print(line,end='')
Traceback (most recent call last):
File "main.py", line 22, in <module>
for line in proxy_backup_log_handler:
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/codecs.py", line 321, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd1 in position 142: invalid continuation byte
2、用gbk打开
with open('proxy_backup_sql.log','r',encoding='gbk') as proxy_backup_log_handler:
for line in proxy_backup_log_handler:
print(line,end='')
192.186.100.10 | 0.012 | select id from tempdb.person where name='寮犱笁';
192.186.100.10 | 0.012 | select id from tempdb.person where name='杨白劳';
可以看到没有报异常、但是这个只是巧合、gbk刚好能解码utf8编码下的“张三”并把它解码成了“寮犱笁”
【latin-1 有的牛逼之处】
latin-1 这个字符集的牛逼之处、latin-1字符集是在ascii码上的一个扩展,它把ascii码没有用到过的字节码都给编上了对应的字符,所以它能表示
的字符就更多了;针对单个字节来说就没有它不能解码的,这个就是它的牛逼之处所在。也就是说当我们不在乎内容中多字节码的正确怕的情况
下使用latin-1字符集是不会出现解码异常的
以下代码可以说明latin-1可以解码任意的单个字节
#!/usr/bin/env python3
#! -*- coding:utf8 -*- ba = bytearray(256)
for i in range(256):
ba[i]=i
print("number = {0} char = {1}".format(i,ba[i:i+1].decode('latin-1')) )
【在我们不在乎多字节码的情况性的情况下latin-1真的是无敌了】
latin-1可以解码任意文件如果你只是在意单字节码中的内容的话
#!/usr/bin/env python3
#! -*- coding:utf8 -*- if __name__ == "__main__":
with open('proxy_backup_sql.log','r',encoding='latin-1') as proxy_backup_log_handler:
for line in proxy_backup_log_handler:
print(line,end='')
可以看到如下的输出
192.186.100.10 | 0.012 | select id from tempdb.person where name='å¼ ä¸';
192.186.100.10 | 0.012 | select id from tempdb.person where name='Ñî°×ÀÍ';
虽然是乱码,但是绝对不会有异常发生。
---
最近对latin-1这个字符集产生了不少好感的更多相关文章
- 01 . Mysql简介及部署
Mysql数据库简介 什么是数据? 数据(data)是事实或观察的结果,是对客观事物的逻辑归纳,是用于表示客观事物的未经加工的原始素材,数据是信息的表现形式和载体,可以是符号,文字,数字,语音,图 ...
- 前端学HTTP之字符集
前面的话 HTTP报文中可以承载以任何语言表示的内容,就像它能承载图像.影片或任何类型的媒体那样.对HTTP来说,实体主体只是二进制信息的容器而已.为了支持国际性内容,服务器需要告知客户端每个文档的字 ...
- mysql数据校验之字符集问题
场景:主库DB:utf8字符集备库DB:gbk字符集 需求:校验主备数据是否一致,并且修复 校验过程:设置主库连接为utf8,设置备库连接为gbk,分别进行查询,将返回的的结果集按记录逐字段比较. 显 ...
- 中文编码、字符集,GBK, UTF-8的概念
字符集指的是什么? 字符集是一个人为的规定,人们用一个小册子规定好"文字字符"与"数字"的对应关系. 其中,每一个字符对应的数组也称其为编码. 例如,ASCII ...
- [MySQL] 字符集的选择
1. Mysql支持的字符集 MySQL服务器可以支持多种字符集,不同的字段都可以使用不同的字符集. 查看所有可用字符集: show character set; select * from info ...
- 03_MySQL中文乱码处理_01_MySQl数据库字符集知识
[MySql数据库常见字符集介绍] 在互联网环境中,使用MySql时常用的字符集有: [如何选择合适的字符集] 1.如果处理各种各样的文字,发布到不同语言的国家地区,应选Unicode字符集,对MyS ...
- LINUX专题之操作系统字符集
原创作品,出自 "深蓝的blog" 博客,欢迎转载.转载时请务必注明下面出处,否则追究版权法律责任. 深蓝的blog: http://blog.csdn.net/huangyanl ...
- 关于Unicode字符集
最初的unicode编码是固定长度的,16位,也就是2两个字节代表一个字符,这样一共可以表示65536个字符.显然,这样要表示各种语言中所有的字符是远远不够的.Unicode4.0规范考虑到了这种情况 ...
- Unicode字符集,各个语言的区间
链接:http://www.cnblogs.com/zl0372/p/unicode.html 链接:http://www.unicode.org/ 链接:https://zh.wikipedia.o ...
随机推荐
- 导出oracle序列
set serveroutput on;spool c:\sequence_code.txt; declare v_sequence varchar2(4000); v_nextval numbe ...
- Jmeter如何提取响应头部的JSESSIONID
近期有柠檬班的学生找到华华,问了一个问题,就是利用Jmeter做接口测试的时候,如何提取头部的JSESSIONID然后传递到下一个请求,继续完成当前用户的请求. 其实,关于这个问题有三种种解决方法: ...
- PHP 数组中取出随机取出指定数量子值集
#关键:array_rand() 函数返回数组中的随机键名,或者如果您规定函数返回不只一个键名,则返回包含随机键名的数组.#思路:先使用array_rand()随机取出所需数量键名,然后将这些键名指向 ...
- maven添加插件,与maven打包
1.编译插件 添加编译器插件来告诉 Maven 使用哪个 JDK 版本是用来编译项目. 2.pom <plugin> <groupId>org.apache.maven.plu ...
- python2与python3的差异
最近在学习python3,遇到过几次python3与python2的的问题,python2使用,而到了python3就不适用了,就整理了一下自己到目前为止所遇到了几个问题(以下是小白见解) 1.pyt ...
- P3819 松江1843路
P3819 松江1843路sigema(r[i]*abs(x[i]-x[s]));令它最小,是带权中位数问题,s是带权中位数,s左边的r[i]之和+r[s]大于s左边的r[i]之和,反过来也成立.如果 ...
- 暴力破解ZIP文件密码
Python 的标准库提供了 ZIP 文件的提取压缩模块 zipfile,现在让我们试着用这个模块,暴力破解出加密的 ZIP 文件!我们可以用 extractall()这个函数抽取文件,密码正确则返回 ...
- win10 图标异常 ,重命名后,图标不显示,名字错乱。
win10 图标异常 ,重命名后,图标不显示,名字错乱. 按下快捷键 Win+R,在打开的运行窗口中输入 %localappdata%,回车. 在打开的文件夹中,找到 IconCache.db,将其删 ...
- BZOJ.3575.[HNOI2014]道路堵塞(最短路 动态SPFA)
题目链接 \(Description\) 给你一张有向图及一条\(1\)到\(n\)的最短路.对这条最短路上的每条边,求删掉这条边后\(1\)到\(n\)的最短路是多少. \(Solution\) 枚 ...
- USBWriter之后恢复磁盘大小
USBWriter之后恢复磁盘大小的方法: 1,cmd 2,diskpart 3,list disk 4,select disk *(*你的U盘代号) (e.g:U盘为磁盘 2 ,则代号为2 ,使用命 ...