从Podman开始一步步构建Hadoop开发集群
摘要
工作关系经常开发大数据相关程序,Hive、Spark、Flink等等都会涉及,为方便随时调试程序便有了部署一个Hadoop集群的想法。在单个主机上部署集群肯定要用到容器相关技术,本人使用过Docker和Podman,在资源和性能比较有限的笔记本上面Podman的总体表现比较不错,而且还可以拉取Docker上的镜像。Podman的安装过程比较简单这里先不赘述,下面一步步展示基于Podman的Hadoop集群安装过程。
软件系统版本
| 系统/软件 | 版本 | 说明 |
|---|---|---|
| Podman Desktop | 1.20.2 | |
| Debian | 9 (stretch) | 10(buster)默认支持的JDK 11以上版本,也通过其他方式安装JDK 8 |
| Hadoop | 3.3.6 |
Hadoop角色结构
resourcemanager好像必须跟namenode在同一台机器
A[Hadoop Network]
B["node01 - 10.88.0.101
角色:
namenode (HDFS)
datanode (HDFS)
nodemanager (YARN)
"] --> A
C["node02 - 10.88.0.102
角色:
secondarynamenode (HDFS)
datanode (HDFS)
nodemanager (YARN)"] --> A
D["node03 - 10.88.0.103
角色:
resourcemanager (YARN)
datanode (HDFS)
nodemanager (YARN)"] --> A
Podman相关
避免挂载宿主机磁盘后遇到权限问题,登录Podman machine default
修改配置/etc/wsl.conf
[automount]
enabled=true
mountFsTab=false
options="metadata"
自动生成hosts记录问题
修改配置/etc/wsl.conf
[network]
generateHosts = false
容器与宿主机网络互通
这里本人没有设置容器的端口映射,通过添加路由的方式,宿主机直接访问容器IP。在宿主机上添加路由,网关设置为Podman machine default系统的IP地址。
route ADD 10.88.0.0 MASK 255.255.0.0 172.24.137.159 IF 37
零、创建容器
创建debian 9容器并指定ip和主机名称
podman run -dt --name node01 --hostname node01.data.org --ip 10.88.0.101 --add-host "node02;node02.data.org:10.88.0.102" --add-host "node03;node03.data.org:10.88.0.103" --cap-add IPC_LOCK --cap-add NET_RAW docker.io/library/debian:9.9 bash
podman run -dt --name node02 --hostname node02.data.org --ip 10.88.0.102 --add-host "node01;node01.data.org:10.88.0.101" --add-host "node03;node03.data.org:10.88.0.103" --cap-add IPC_LOCK --cap-add NET_RAW docker.io/library/debian:9.9 bash
podman run -dt --name node03 --hostname node03.data.org --ip 10.88.0.103 --add-host "node01;node01.data.org:10.88.0.101" --add-host "node02;node02.data.org:10.88.0.102" --cap-add IPC_LOCK --cap-add NET_RAW docker.io/library/debian:9.9 bash
2023年以后Debian官方源地址已经修改,系统自带的源会出现404报错问题,更新官方源或者网上搜索国内公共源。
# 设置系统时区和语言
rm -f /etc/localtime && ln -sv /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo "Asia/Shanghai" > /etc/timezone
# 更新镜像源
mv /etc/apt/sources.list /etc/apt/sources.list.old
cat > /etc/apt/sources.list << EOF
deb http://mirrors.cloud.tencent.com/debian-archive//debian/ stretch main contrib non-free
deb-src http://mirrors.cloud.tencent.com/debian-archive//debian/ stretch main contrib non-free
deb http://mirrors.cloud.tencent.com/debian-archive//debian/ stretch-backports main contrib non-free
deb http://mirrors.cloud.tencent.com/debian-archive//debian-security/ stretch/updates main contrib non-free
deb-src http://mirrors.cloud.tencent.com/debian-archive//debian-security/ stretch/updates main contrib non-free
EOF
apt update
执行apt update更新时如果提示PUBLIC KEY的问题执行下面语句
apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 467B942D3A79BD29(更换为提示的KEY)
# 安装必须软件
apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \
openjdk-8-jdk \
net-tools \
curl \
netcat \
gnupg \
libsnappy-dev \
openssh-server \
openssh-client \
sudo \
&& rm -rf /var/lib/apt/lists/*
# 创建hadoop用户并添加sudo权限
chmod 640 /etc/sudoers
groupadd --system --gid=10000 hadoop && useradd --system --home-dir /home/hadoop --uid=10000 --gid=hadoop hadoop && echo "hadoop ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
# 生成秘钥,把node01公钥导入node02和node03中,配置免密登录
ssh-keygen -t rsa -P "" -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 允许root登录,启动ssh并允许开机启动
echo "PermitRootLogin yes" >> /etc/ssh/sshd_config
/etc/init.d/ssh start
update-rc.d ssh enable
一、Hadoop基础环境安装
hadoop软件下载安装
设置环境变量
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=${JAVA_HOME}/jre
export HADOOP_VERSION=3.3.6
export HADOOP_HOME=/opt/hadoop-$HADOOP_VERSION
echo "export LANG=zh_CN.UTF-8" >> /etc/profile
echo "export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64" >> /etc/profile.d/hadoopbase.sh
echo "export JRE_HOME=${JAVA_HOME}/jre" >> /etc/profile.d/hadoopbase.sh
echo "export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib" >> /etc/profile.d/hadoopbase.sh
echo "export PATH=${JAVA_HOME}/bin:\$PATH" >> /etc/profile.d/hadoopbase.sh
echo "export HADOOP_VERSION=3.3.6" >> /etc/profile.d/hadoopbase.sh
echo "export HADOOP_HOME=/opt/hadoop-$HADOOP_VERSION" >> /etc/profile.d/hadoopbase.sh
echo "export HADOOP_CONF_DIR=/etc/hadoop" >> /etc/profile.d/hadoopbase.sh
echo "export PATH=$HADOOP_HOME/bin/:\$PATH" >> /etc/profile.d/hadoopbase.sh
source /etc/profile
创建数据目录
mkdir -p /data/hadoop-data
mkdir -p /data/hadoop/tmp
mkdir -p /data/hadoop/nameNode
mkdir -p /data/hadoop/dataNode
安装Hadoop
# 导入hadoop安装包校验KEY
curl -O https://dist.apache.org/repos/dist/release/hadoop/common/KEYS
gpg --import KEYS
# hadoop 版本
set -x \
&& curl -fSL "https://www.apache.org/dist/hadoop/common/hadoop-$HADOOP_VERSION/hadoop-$HADOOP_VERSION.tar.gz" -o /tmp/hadoop.tar.gz \
&& curl -fSL "https://www.apache.org/dist/hadoop/common/hadoop-$HADOOP_VERSION/hadoop-$HADOOP_VERSION.tar.gz.asc" -o /tmp/hadoop.tar.gz.asc \
&& gpg --verify /tmp/hadoop.tar.gz.asc \
&& tar -xf /tmp/hadoop.tar.gz -C /opt/ \
&& rm /tmp/hadoop.tar.gz*
ln -s $HADOOP_HOME/etc/hadoop /etc/hadoop
mkdir $HADOOP_HOME/logs
node01节点修改配置
- /etc/hadoop/hadoop-env.sh
#文件最后添加
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
- /etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
- /etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node02:50070</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/nameNode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/dataNode</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
- /etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node01:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
- /etc/hadoop/yarn-site.xml resourcemanager好像必须跟namenode在同一台机器
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://node01:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
- /etc/hadoop/workers
node01
node02
node03
- 拷贝到其他节点
scp -r /opt/hadoop-3.3.6 root@node02:/opt/
scp -r /opt/hadoop-3.3.6 root@node03:/opt/
# 分别在node02和node03节点创建软链接
ln -s $HADOOP_HOME/etc/hadoop /etc/hadoop
- 初始启动前操作
# 在node01上格式化namenode
hdfs namenode -format
- 启动服务
# 在node01上执行
bash $HADOOP_HOME/sbin/start-all.sh
bash $HADOOP_HOME/sbin/stop-all.sh
检查服务启动动是否正常
jps
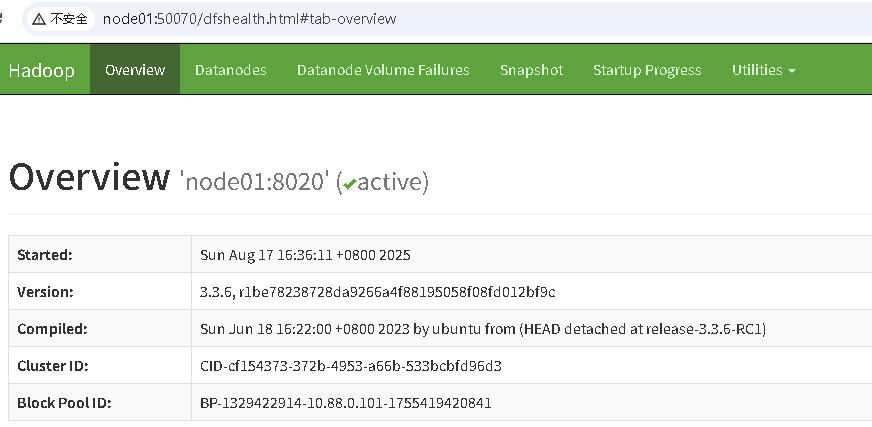
打开浏览器验证
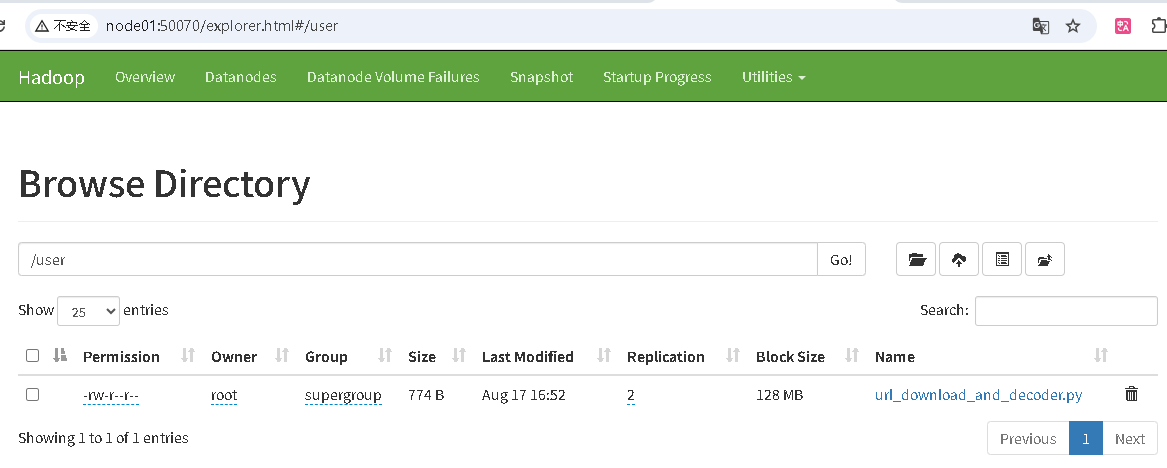
HDFS上传文件
http://node01:50070/ 验证HDFS上传文件
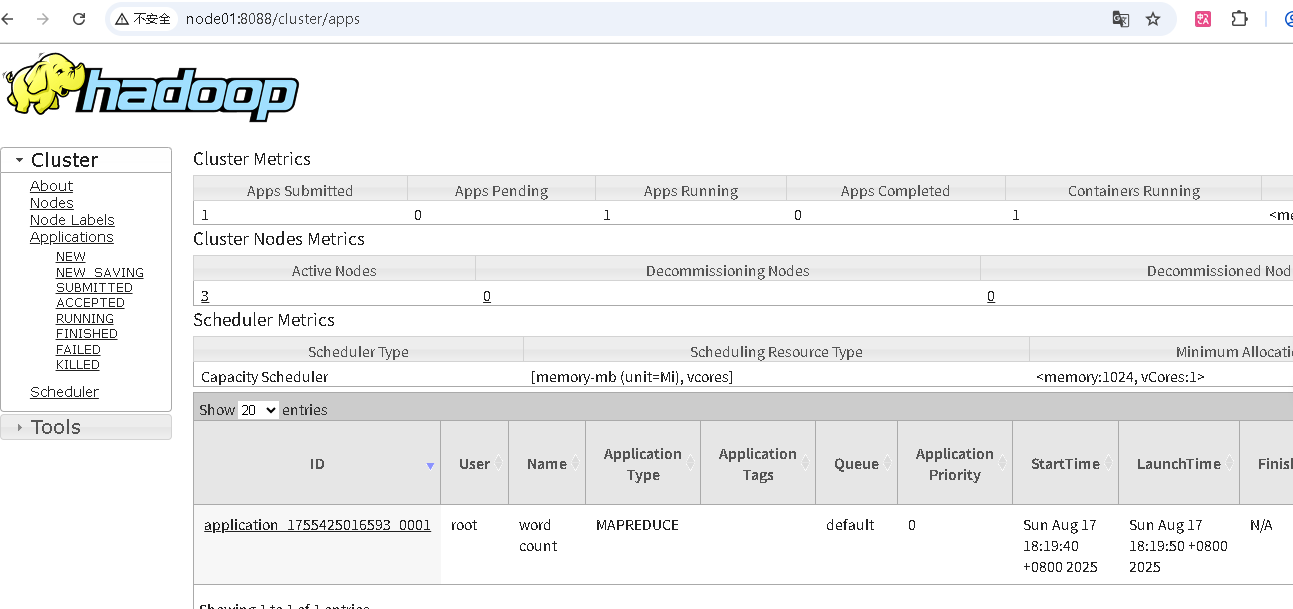
mapreduce跑wordcount任务验证
运行wordcount测试样例统计一个文本用词数量,文本要先上传到HDFS
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /tmp/harrypotter.txt /output/harr
output目录下载和查看输出结果
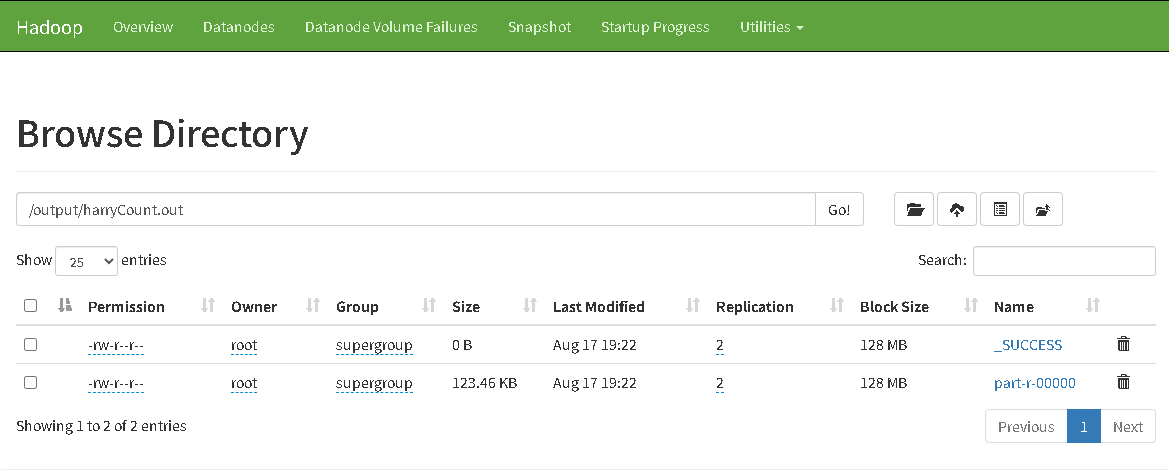
至此Hadoop平台的搭建已经完成。基础的Yarn、HDFS、MapReduce功能已经齐全,后面在此基础上完成Hive、Spark和Flink环境部署。
二、Hive安装
待补充
三、Spark
待补充
四、Flink
待补充
五、FAQ
1.容器中安装ping工具报错
需要在创建容器时添加cap-add参数IPC_LOCK和NET_RAW,desktop在Security -> Capabilities位置,命令行创建容器时添加下面参数
--cap-add=IPC_LOCK --cap-add=NET_RAW (或者--cap-add=ALL)
2.在HDFS web ui 上传文件时提示“Couldn't upload the file”
- 检查hdfs-site.xml是否配置dfs.permissions=false
- 检查操作上传的主机的hosts文件是否配置hadoop集群节点IP映射,上传文件时会调用域名
- HDFS目录是否有写入权限
附
配置参考
CORE_CONF_fs_defaultFS=hdfs://namenode:9000
CORE_CONF_hadoop_http_staticuser_user=root
CORE_CONF_hadoop_proxyuser_hue_hosts=*
CORE_CONF_hadoop_proxyuser_hue_groups=*
CORE_CONF_io_compression_codecs=org.apache.hadoop.io.compress.SnappyCodec
HDFS_CONF_dfs_webhdfs_enabled=true
HDFS_CONF_dfs_permissions_enabled=false
HDFS_CONF_dfs_namenode_datanode_registration_ip___hostname___check=false
YARN_CONF_yarn_log___aggregation___enable=true
YARN_CONF_yarn_log_server_url=http://historyserver:8188/applicationhistory/logs/
YARN_CONF_yarn_resourcemanager_recovery_enabled=true
YARN_CONF_yarn_resourcemanager_store_class=org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore
YARN_CONF_yarn_resourcemanager_scheduler_class=org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
YARN_CONF_yarn_scheduler_capacity_root_default_maximum___allocation___mb=8192
YARN_CONF_yarn_scheduler_capacity_root_default_maximum___allocation___vcores=4
YARN_CONF_yarn_resourcemanager_fs_state___store_uri=/rmstate
YARN_CONF_yarn_resourcemanager_system___metrics___publisher_enabled=true
YARN_CONF_yarn_resourcemanager_hostname=resourcemanager
YARN_CONF_yarn_resourcemanager_address=resourcemanager:8032
YARN_CONF_yarn_resourcemanager_scheduler_address=resourcemanager:8030
YARN_CONF_yarn_resourcemanager_resource__tracker_address=resourcemanager:8031
YARN_CONF_yarn_timeline___service_enabled=true
YARN_CONF_yarn_timeline___service_generic___application___history_enabled=true
YARN_CONF_yarn_timeline___service_hostname=historyserver
YARN_CONF_mapreduce_map_output_compress=true
YARN_CONF_mapred_map_output_compress_codec=org.apache.hadoop.io.compress.SnappyCodec
YARN_CONF_yarn_nodemanager_resource_memory___mb=16384
YARN_CONF_yarn_nodemanager_resource_cpu___vcores=8
YARN_CONF_yarn_nodemanager_disk___health___checker_max___disk___utilization___per___disk___percentage=98.5
YARN_CONF_yarn_nodemanager_remote___app___log___dir=/app-logs
YARN_CONF_yarn_nodemanager_aux___services=mapreduce_shuffle
MAPRED_CONF_mapreduce_framework_name=yarn
MAPRED_CONF_mapred_child_java_opts=-Xmx4096m
MAPRED_CONF_mapreduce_map_memory_mb=4096
MAPRED_CONF_mapreduce_reduce_memory_mb=8192
MAPRED_CONF_mapreduce_map_java_opts=-Xmx3072m
MAPRED_CONF_mapreduce_reduce_java_opts=-Xmx6144m
MAPRED_CONF_yarn_app_mapreduce_am_env=HADOOP_MAPRED_HOME=/opt/hadoop-3.2.1/
MAPRED_CONF_mapreduce_map_env=HADOOP_MAPRED_HOME=/opt/hadoop-3.2.1/
MAPRED_CONF_mapreduce_reduce_env=HADOOP_MAPRED_HOME=/opt/hadoop-3.2.1/
Debian 9(stretch)镜像源
官方
deb http://archive.debian.org/debian/ stretch main contrib non-free
deb-src http://archive.debian.org/debian/ stretch main contrib non-free
deb http://archive.debian.org/debian/ stretch-backports main contrib non-free
deb http://archive.debian.org/debian-security/ stretch/updates main contrib non-free
deb-src http://archive.debian.org/debian-security/ stretch/updates main contrib non-free
腾讯
deb http://mirrors.cloud.tencent.com/debian-archive//debian/ stretch main contrib non-free
deb-src http://mirrors.cloud.tencent.com/debian-archive//debian/ stretch main contrib non-free
deb http://mirrors.cloud.tencent.com/debian-archive//debian/ stretch-backports main contrib non-free
deb http://mirrors.cloud.tencent.com/debian-archive//debian-security/ stretch/updates main contrib non-free
deb-src http://mirrors.cloud.tencent.com/debian-archive//debian-security/ stretch/updates main contrib non-free
阿里云
deb http://mirrors.aliyun.com/debian-archive/debian/ stretch main contrib non-free
deb-src http://mirrors.aliyun.com/debian-archive/debian/ stretch main contrib non-free
deb http://mirrors.aliyun.com/debian-archive/debian/ stretch-backports main contrib non-free
deb http://mirrors.aliyun.com/debian-archive/debian-security/ stretch/updates main contrib non-free
deb-src http://mirrors.aliyun.com/debian-archive/debian-security/ stretch/updates main contrib non-free
从Podman开始一步步构建Hadoop开发集群的更多相关文章
- Hadoop HA集群 与 开发环境部署
每一次 Hadoop 生态的更新都是如此令人激动 像是 hadoop3x 精简了内核,spark3 在调用 R 语言的 UDF 方面,速度提升了 40 倍 所以该文章肯定得配备上最新的生态 hadoo ...
- 超快速使用docker在本地搭建hadoop分布式集群
超快速使用docker在本地搭建hadoop分布式集群 超快速使用docker在本地搭建hadoop分布式集群 学习hadoop集群环境搭建是hadoop入门的必经之路.搭建分布式集群通常有两个办法: ...
- Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很多问题.以下是自己根据搭建Hadoop分布式集群的经验希望给新手一些帮助.当然,建议先把HDFS ...
- 使用Docker在本地搭建Hadoop分布式集群
学习Hadoop集群环境搭建是Hadoop入门必经之路.搭建分布式集群通常有两个办法: 要么找多台机器来部署(常常找不到机器) 或者在本地开多个虚拟机(开销很大,对宿主机器性能要求高,光是安装多个虚拟 ...
- hadoop分布式集群的搭建
电脑如果是8G内存或者以下建议搭建3节点集群,如果是搭建5节点集群就要增加内存条了.当然实际开发中不会用虚拟机做,一些小公司刚刚起步的时候会采用云服务,因为开始数据量不大. 但随着数据量的增大才会考虑 ...
- 分布式计算(一)Ubuntu搭建Hadoop分布式集群
最近准备接触分布式计算,学习分布式计算的技术栈和架构知识.目前的分布式计算方式大致分为两种:离线计算和实时计算.在大数据全家桶中,离线计算的优秀工具当属Hadoop和Spark,而实时计算的杰出代表非 ...
- hadoop+spark集群搭建入门
忽略元数据末尾 回到原数据开始处 Hadoop+spark集群搭建 说明: 本文档主要讲述hadoop+spark的集群搭建,linux环境是centos,本文档集群搭建使用两个节点作为集群环境:一个 ...
- 使用docker搭建hadoop分布式集群
使用docker搭建部署hadoop分布式集群 在网上找了非常长时间都没有找到使用docker搭建hadoop分布式集群的文档,没办法,仅仅能自己写一个了. 一:环境准备: 1:首先要有一个Cento ...
- Linux企业集群用商用硬件和免费软件构建高可用集群PDF
Linux企业集群:用商用硬件和免费软件构建高可用集群 目录: 译者序致谢前言绪论第一部分 集群资源 第1章 启动服务 第2章 处理数据包 第3章 编译内容 第二部分 高可用性 第4章 使用rsync ...
- Hadoop - Ambari集群管理剖析
1.Overview Ambari是Apache推出的一个集中管理Hadoop的集群的一个平台,可以快速帮助搭建Hadoop及相关以来组件的平台,管理集群方便.这篇博客记录Ambari的相关问题和注意 ...
随机推荐
- SpringBoot启动类没有启动按钮,java文件变为灰色的解决策略
今天在查看Spring Boot项目的时候发现自己的项目变成了上面这个样子,无法执行main函数. 解决方法(上述操作可以忽略):选择我们项目的pom文件,然后右键选择 Add as Maven ...
- SparkSQL编程需注意的细节
SparkSQL是把Hive转为字符串后,以参数形式传递到SparkSession.builder().enableHiveSupport().getOrcCreate().sql(Hive_Stri ...
- Mac os的防火墙导致开的热点手机连不上
在工位上用Mac给手机开热点用,结果今天手机一直连不上Mac开的热点,最后把Mac的防火墙关了就能让手机连上了,连上了再把防火墙打开也不影响连接.
- 深入浅出容器学习--Docker数据卷
一.Docker数据卷 Docker镜像是由多个文件系统(只读层)叠加而成,当启动一个容器的时候,Docker会加载只读镜像层并在其上(镜像栈顶部)添加一个读写层.如果运行中的容器修改了现有的一个已经 ...
- 【前端AI实践】Lingma:使用工具辅助开发让你停不下来
如果你用过 GitHub Copilot,那你对 AI 编程助手应该不陌生.而 Lingma 是阿里云推出的一款专注于编程场景的智能编码助手. 它深度集成在 VS Code.JetBrains 等主流 ...
- 开源项目丨 Taier 1.1 版本正式发布,新增功能一览为快
2022 年 5 月 8 日,Taier 1.1 版本正式发布! 本次版本更新对 Flink 的支持升级到 Flink1.12,支持多种流类型任务,新版本的使用文档已在社区中推送,大家可以随时下载查阅 ...
- 破解五大运营痛点:盘古信息IMS MOM重塑PCB工厂数字化基石
随着5G.物联网等技术发展,PCB行业下游消费电子.汽车电子等领域需求呈现小批量多品种.高精度高可靠性.快速交付特点.传统"规模驱动"生产模式难以适应新需求,行业竞争焦点转向质量. ...
- 用 Tarjan 算法求解无向图的割点和割边
上期回顾:https://www.cnblogs.com/ofnoname/p/18823922 Tarjan 算法与无向图 连接性分析是图论的核心,而Tarjan算法为我们提供了穿透复杂网络结构的通 ...
- stm32达到什么程度叫精通?
作为一个在嵌入式领域摸爬滚打了快10年的老兵,看到这个问题时我陷入了深深的思考.精通?这两个字说起来轻松,但要真正做到却是另一回事.我记得刚入行的时候,觉得会用几个库函数就算"精通" ...
- AI应用实战课学习总结(3)预测带货销售额
大家好,我是Edison. 最近入坑黄佳老师的<AI应用实战课>,记录下我的学习之旅,也算是总结回顾. 今天是我们的第3站,了解下AI项目实践的5大环节,并通过一个预测直播带货销售额的案例 ...