基于RAG的MaxKB知识库问答系统如何选择向量模型
在MaxKB中替换向量模型前,我们需要先了解向量相关的原理和技术,此处不做赘述,大家可以自行学习。可以了解下Embedding、Embedding核心,向量库等内容。
一、MaxKB 默认向量模型
MaxKB一款基于大语言模型和RAG技术的知识库问答系统,具体可以参见其官网:https://maxkb.cn/index.html 。在MaxKB中知识库文档的Embedding是很重要的一环,而这个过程久必须依赖向量模型。目前MaxKB本身内置的向量模型为text2vec-base-Chinese。一个针对中文语义匹配任务优化的向量模型,特别适用于中文句子级别的语义匹配任务。早期的时候在多个领域表现出了优秀的性能。但是也存在一些不足:
- 长文本处理能力:在处理长文本时,可能无法有效搜索到相关结果,这表明在长文本处理方面可能存在一定的局限性。
- 向量模型“坍缩”现象:这个现象指的是BERT对所有的句子都倾向于编码到一个较小的空间区域内,这使得大多数的句子对都具有较高的相似度分数。这会导致模型难以准确地反映出两个句子的语义相似度,尤其是在处理长文本时,可能会经常搜索不到不准确的结果。
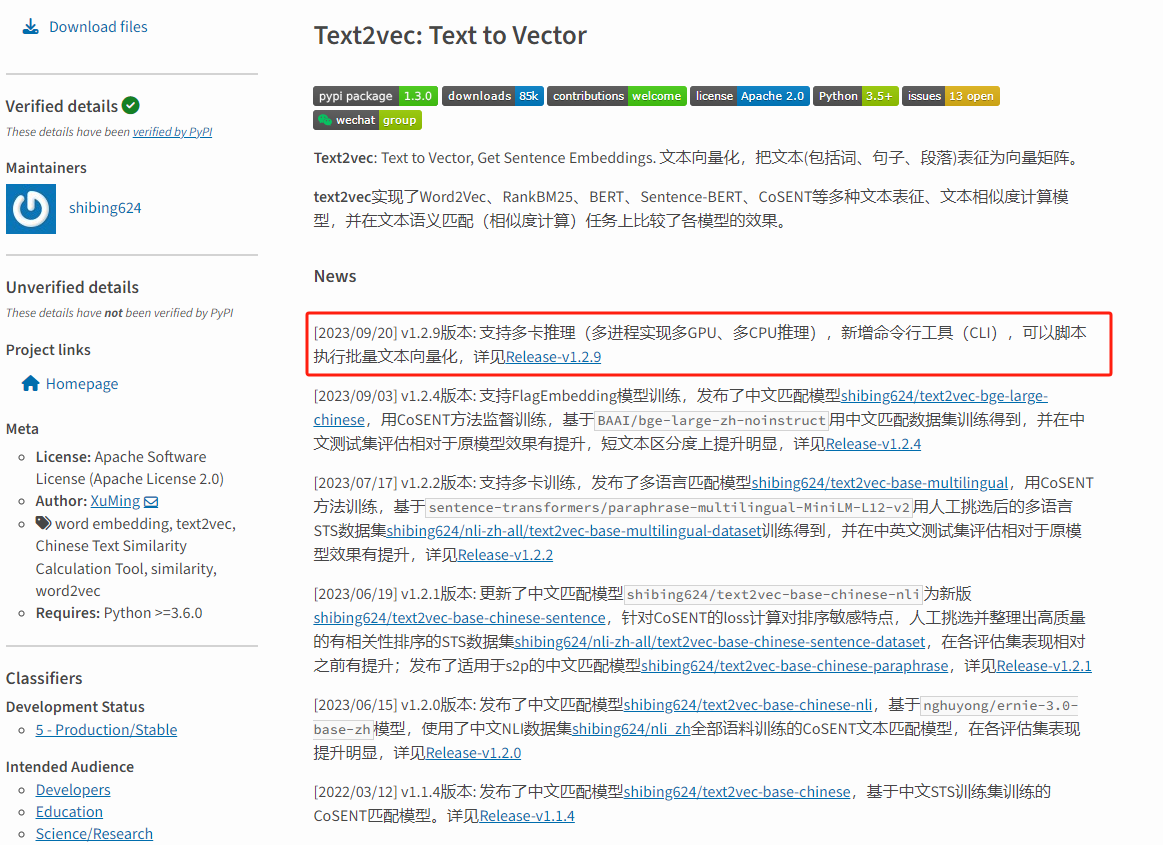
- 模型实时性问题:至目前为主,text2vec-base-Chinese官方库最新一次更新时间为[2023/09/20] v1.2.9版本,也就是一年的时间没有更新了,在这个AI快速发展的时代,一年的时间显的很长。
备注:BERT(Bidirectional Encoder Representations from Transformers)是由 Google 在 2018 年提出的一种预训练语言表示模型,它基于 Transformer 架构构建,通过深度双向训练来理解语言的上下文信息。
二、向量模型的分类
向量模型的种类大概分为六大类,向量模型的数量基本也有上百种以上,如何选择向量模型一直是个难题。我们先看下向量模型的分类情况:
- BERT (Bidirectional Encoder Representations from Transformers):这是一种基于 Transformer 架构的预训练语言表示模型,它通过深度双向训练来理解语言的上下文信息。BERT 在自然语言处理(NLP)领域取得了显著的性能提升,被广泛应用于各种任务,如情感分析、问答系统、命名实体识别等。
- M3E (Massive Mixed Embedding):M3E 在私有部署和大规模文本处理方面表现出色,适用于需要私有化和资源节约的场景。它通过大规模混合嵌入技术提高了词向量的表达能力和泛化能力,适用于各种文本处理任务。
- BGE (Baidu General Embedding):BGE 系列模型在全球下载量超过1500万,位居国内开源 AI 模型首位,表明其资源使用高效且受欢迎。BGE 在多语言支持、文本处理能力和检索精度方面表现优异,尤其适合需要高精度和高效率的场景。
- Sentence Transformers:基于孪生 BERT 网络预训练得到的模型,对句子的嵌入效果比较好。
- OpenAI Embedding (text-embedding-ada-002): OpenAI 提供的模型,嵌入效果表现不错,且可以处理最大 8191 标记长度的文本。
- Instructor Embedding:这是一个经过指令微调的文本嵌入模型,可以根据任务(例如分类、检索、聚类、文本评估等)和领域(例如科学、金融等),提供任务指令而生成相对定制化的文本嵌入向量,无需进行任何微调。
三、如何选择一款合适的向量模型
为了应对不同类型文档的 Emdeding,我们需要根据特点以及场景选择适合的向量模型,而 MaxKB 本身是支持选择配置不同的向量模型的(MaxKB具体支持那些模型可参见:https://maxkb.cn/docs/user_manual/model/model_ summary/) 。 所以我们重点看下如何选择向量模型。选择向量模型的第一点需要考虑模型的排行,应用场景等。但是这些在 huggingface、魔塔社区都有相应的说明,反而不是太过担心。
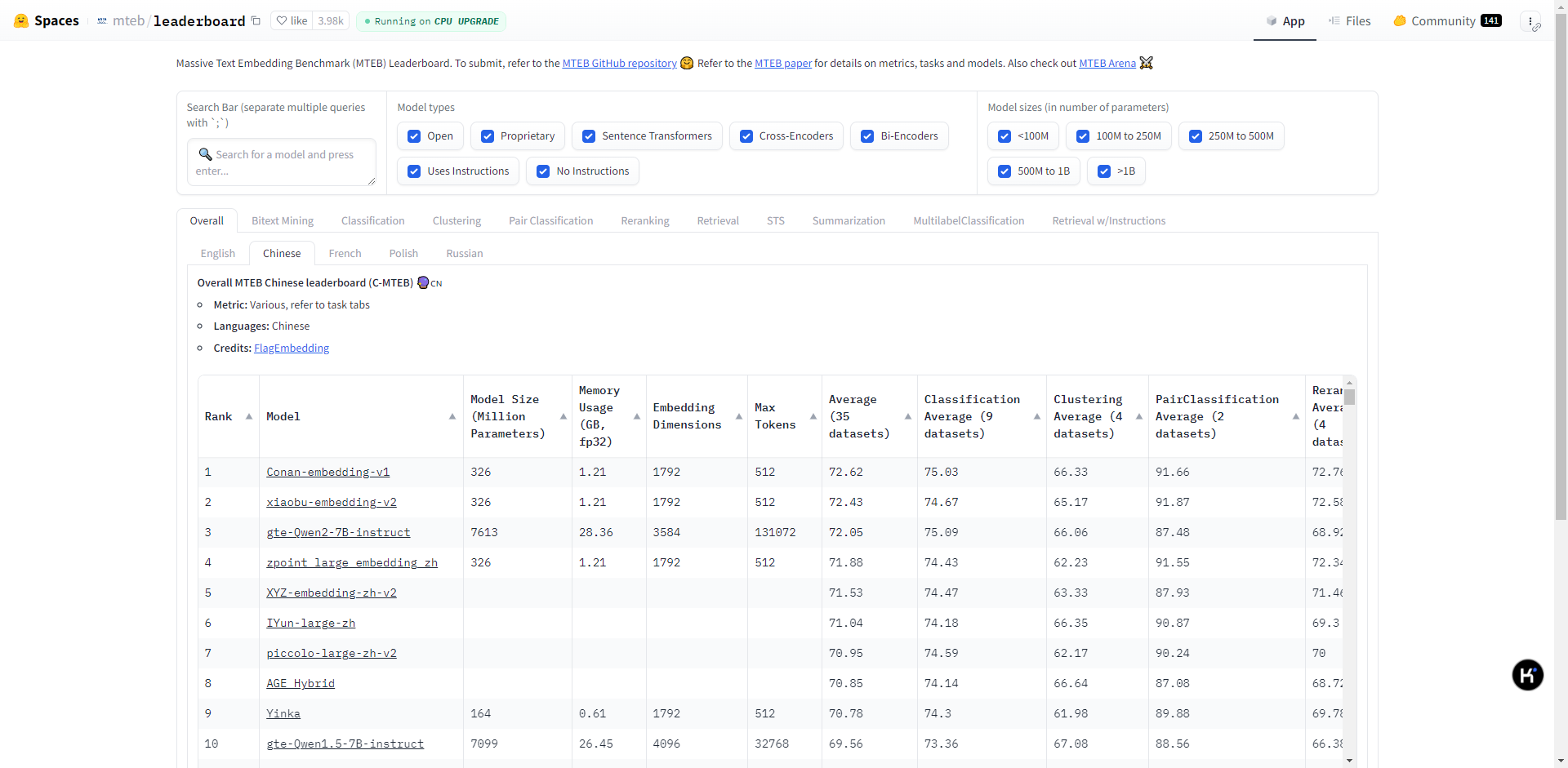
3.1、huggingface 的 MTEB 榜单
https://huggingface.co/spaces/mteb/leaderboard 评估和比较不同文本嵌入模型的基准测试性能,MTEB榜单涵盖了多种语言和任务类型,包括法语、英语、中文等112种语言,涉及检索、排序、句子相似度、推理、分类、聚类等任务。通过这些任务,MTEB能够评估模型在不同场景下的表现,为用户提供选择依据。
3.2、魔塔社区
魔塔社区(https://modelscope.cn/) ModelScope社区成立于2022年6月,是一个模型开源社区及创新平台,由阿里巴巴达摩院,联合CCF开源发展委员会,共同作为项目发起方。
3.3、替换MaxKB的向量模型
具体在MaxKB中替换向量模型时选择哪一种?这个就需要结合上述六大分类的向量模型,综合以下几个方面进行考量:
- 语义理解能力:需要能够理解句子或段落级别的语义,而不仅仅是词汇级别的相似度。
- 运行效率:针对大规模语料的检索需要考虑计算效率和相似度检索时间。
- 上下文依赖性:选择模型时需要考虑上下文对语义匹配的重要性。
- 领域适配性:有些模型对特定任务或领域(如法律、医学)需要采用专业领域模型(微调或者现有的)以提供最佳性能。
从huggingface的MTEB中文榜单中,可以看出目前支持中文主流的向量模型有以下几种(相对而言,模型更新太快)。以下是汇总了MTEB排行榜中第1至第20位中包含具体参数信息的模型,及其性能参数,补充了模型简介和适用场景:
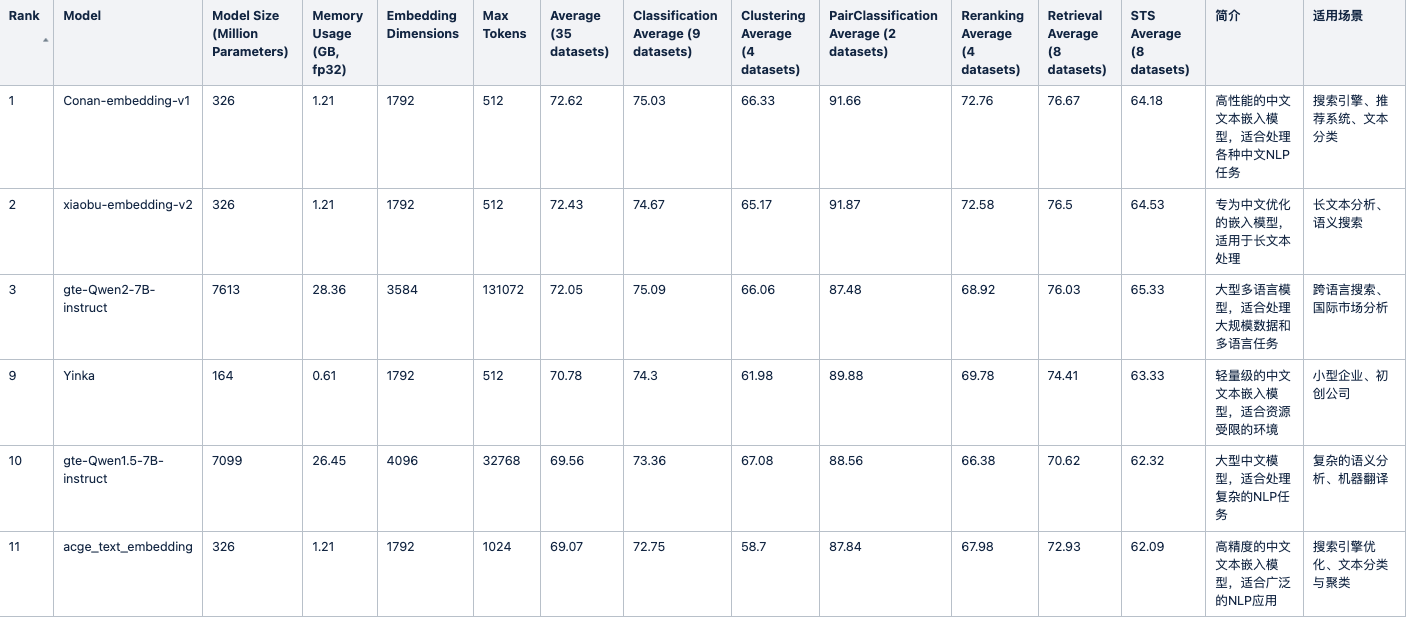
当然,上述为通用模型,在一些特殊领域也可以使用以下场景模型,比如面向电商、医疗等,可以按照实际场景进行选择:
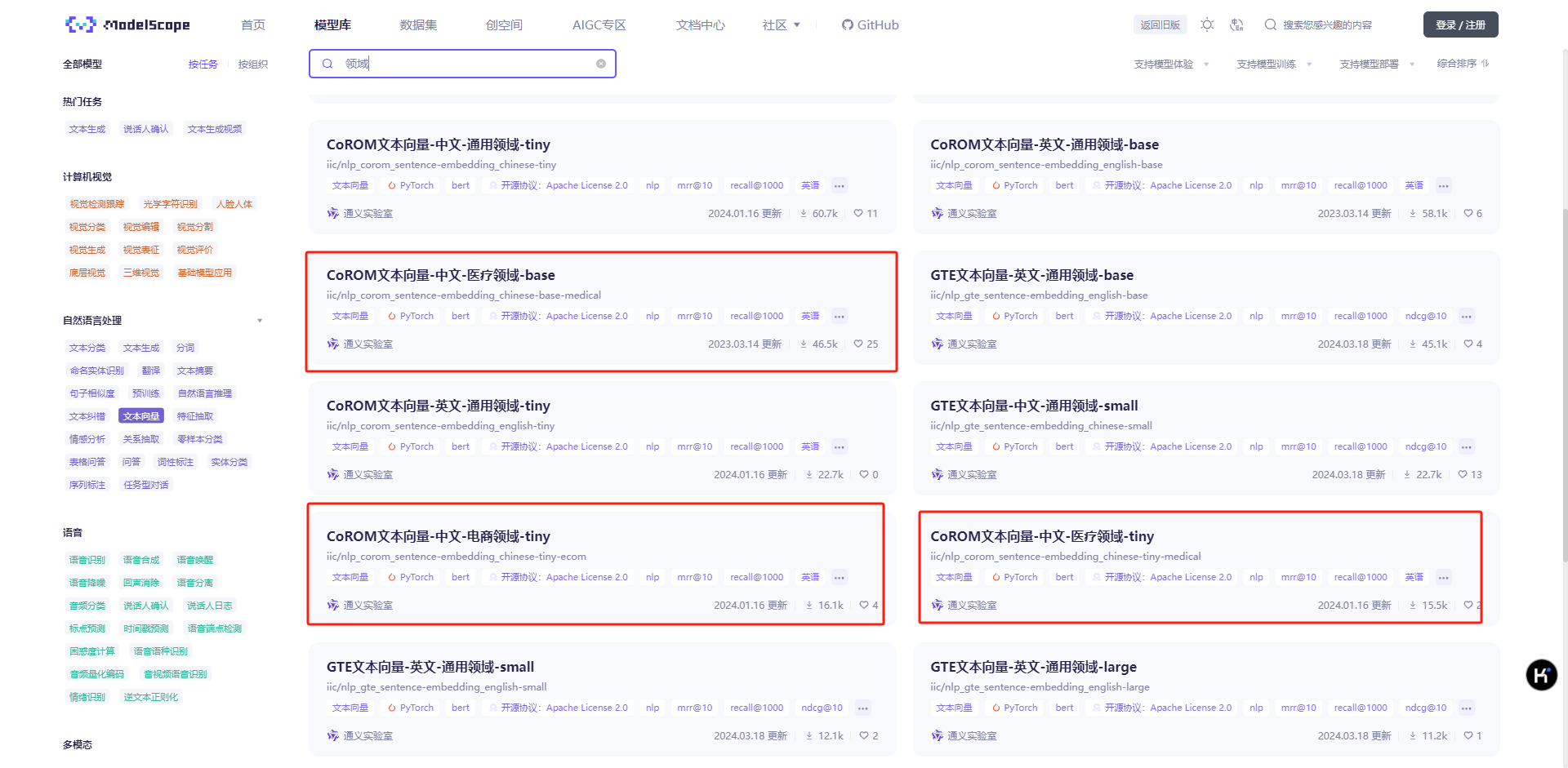
关于在MaxKB中如何替换向量模式这边就不过多介绍,可以通过接入公有向量模型、Xinference、或者本地模型方式接入,具体可以参考手册(https://maxkb.cn/docs/user_manual/model/bailian_model/ ),比如在Xinference中启用本地向量模型(用ollama、本地模型的方式也可以)。
步骤一:安装部署 Xinference
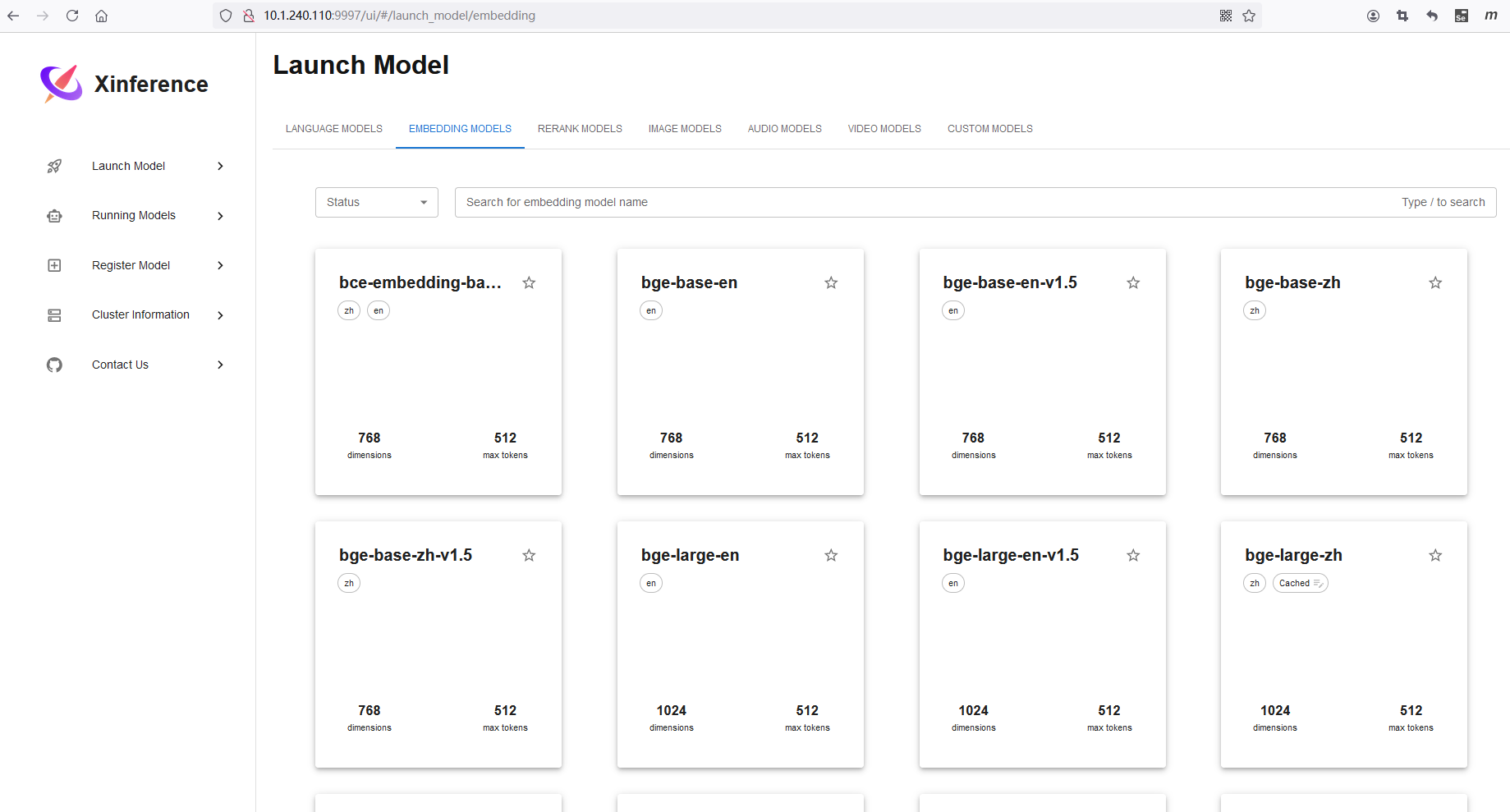
步骤二:基于 Xinference 安装向量模型
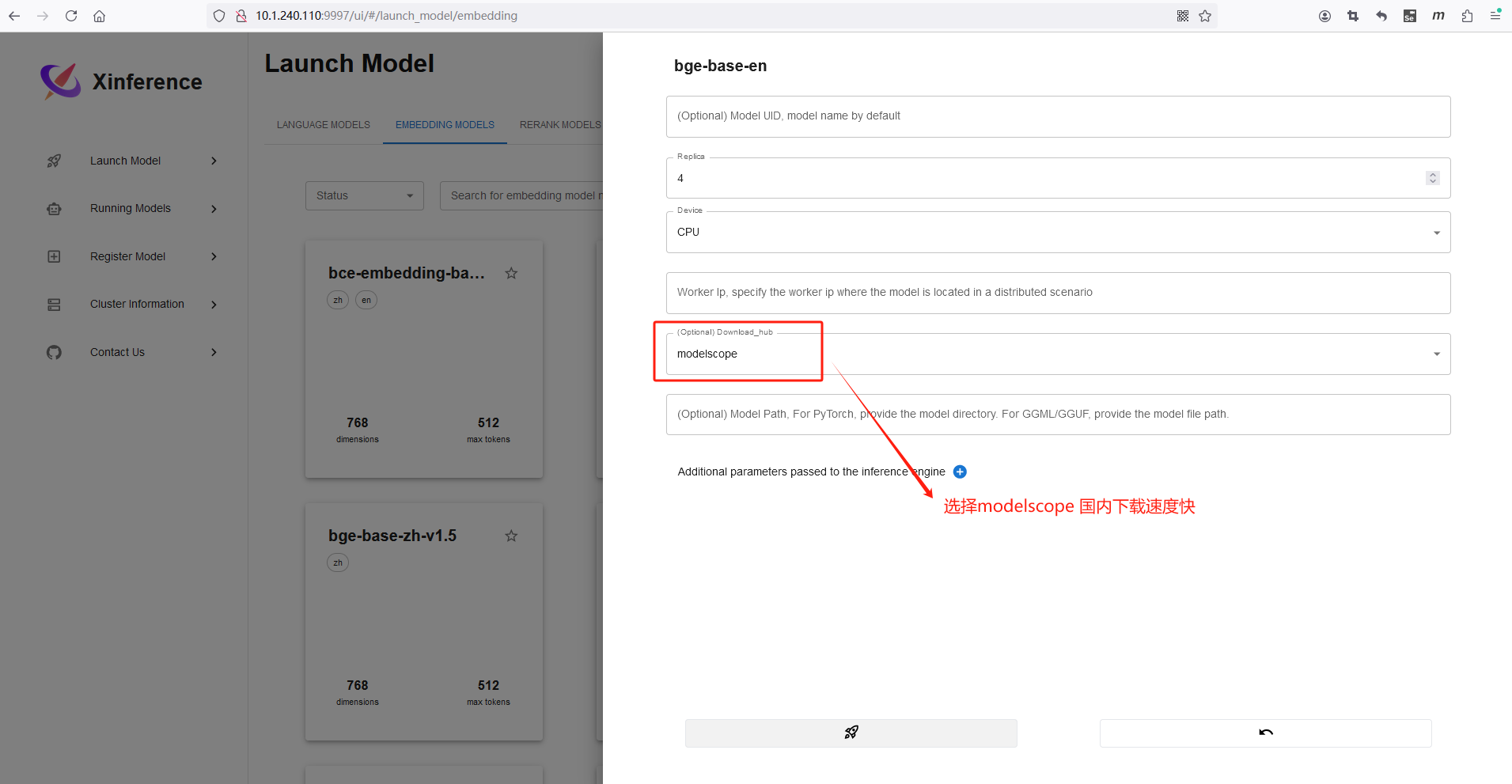
步骤三:基于MaxKB 的模型管理对接向量模型
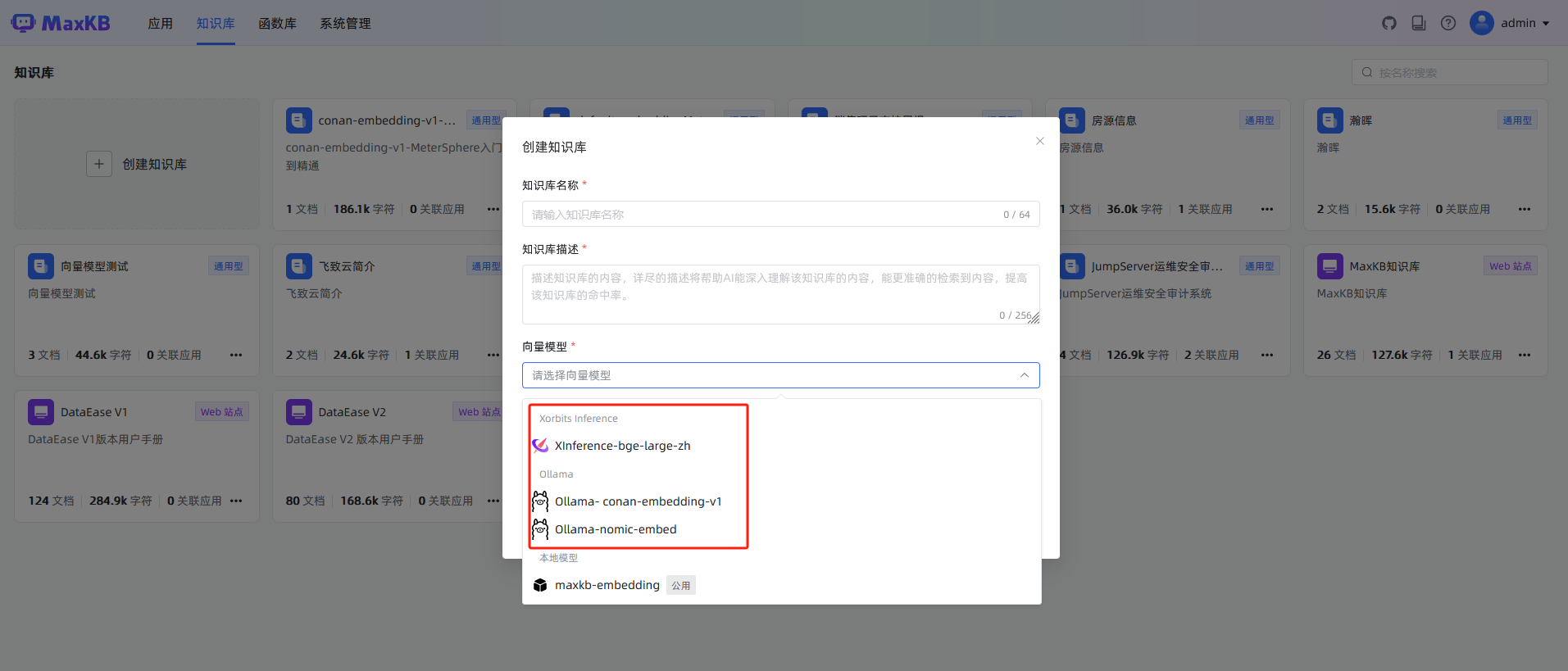
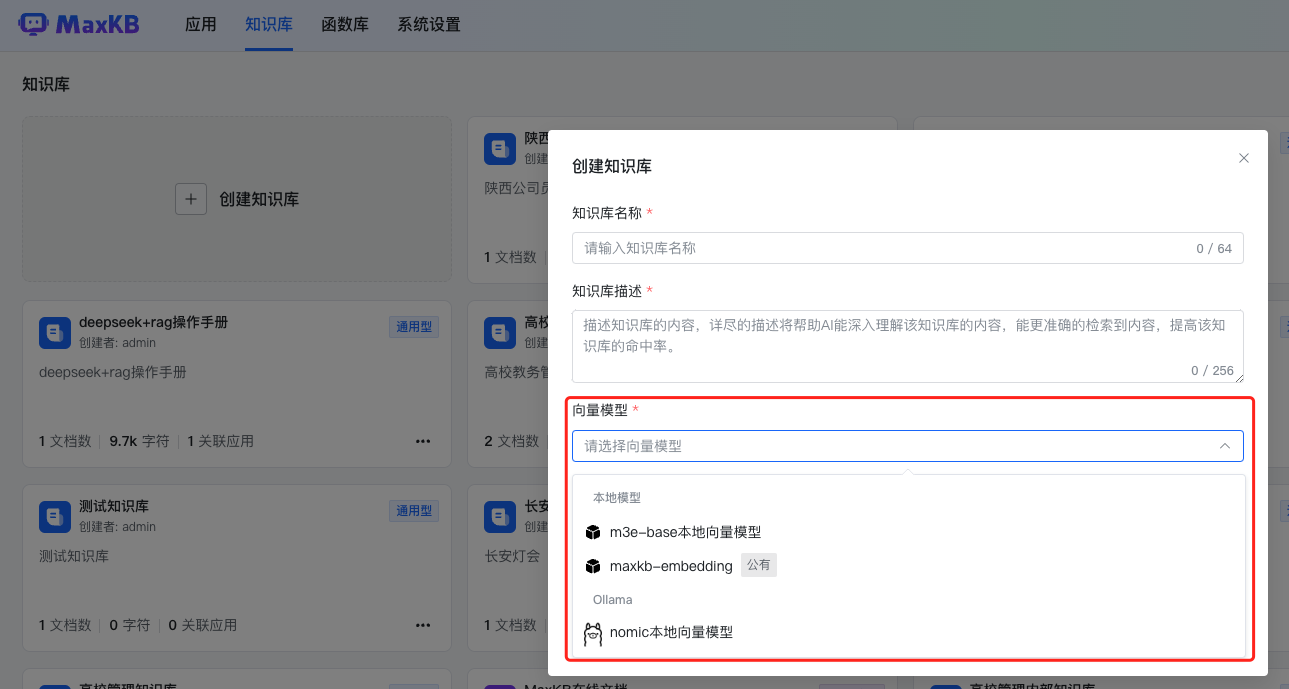
步骤四:在知识库管理中选择向量模型,完成文档向量化
 。
。
基于RAG的MaxKB知识库问答系统如何选择向量模型的更多相关文章
- 基于Kafka的实时计算引擎如何选择?Flink or Spark?
1.前言 目前实时计算的业务场景越来越多,实时计算引擎技术及生态也越来越成熟.以Flink和Spark为首的实时计算引擎,成为实时计算场景的重点考虑对象.那么,今天就来聊一聊基于Kafka的实时计算引 ...
- 基于Kafka的实时计算引擎如何选择?(转载)
1.前言 目前实时计算的业务场景越来越多,实时计算引擎技术及生态也越来越成熟.以Flink和Spark为首的实时计算引擎,成为实时计算场景的重点考虑对象.那么,今天就来聊一聊基于Kafka的实时计算引 ...
- 三维CAD塑造——基于所述基本数据结构一半欧拉操作模型
三维CAD塑造--基于所述基本数据结构一半欧拉操作模型(elar, B_REP) (欧拉操作 三维CAD建模课程 三维CAD塑造 高曙明老师 渲染框架 brep 带洞 带柄 B_REP brep ...
- 一.Windows I/O模型之选择(select)模型
1.选择(select)模型:选择模型:通过一个fd_set集合管理套接字,在满足套接字需求后,通知套接字.让套接字进行工作.避免套接字进入阻塞模式,进行无谓的等待.选择模型的核心的FD_SET集合和 ...
- 基于word2vec的文档向量模型的应用
基于word2vec的文档向量模型的应用 word2vec的原理以及训练过程具体细节就不介绍了,推荐两篇文档:<word2vec parameter learning explained> ...
- 基于jquery封装的颜色下拉选择框
应同事要求,花了半个小时,写了一个简单的选择颜色的下拉框控件,可以控制输入框指示结果颜色 也贴出来,说不定哪天有用 if (typeof jQuery === 'undefined') { throw ...
- 基于EasyUi ComBotree树修改 父节点选择问题
本人在使用 Easy UI 期间发现了一个不太适合项目的bug,可能也不算bug把 . 毕竟不同项目背景 取舍不同. 我在做网元树选择的时候 发现当选取父节点后,子节点都会被选择 返回 .但是如 ...
- 【selenium】基于python语言,如何用select选择下拉框
在项目测试中遇到了下拉框选择的控件,来总结下如何使用select选择下拉框: 下图是Select类的初始化描述,意思是,给定元素是得是select类型,不是就抛异常.接下来给了例子:要操作这个sele ...
- 基于Python Tornado的在线问答系统
概述 本项目使用最新的Tornado开发.实现了在线提问,回答,评论等功能.使用到Tornado的generator,长轮询等等技术, 支持MySQL的异步连接. 详细 代码下载:http://www ...
- 基于HTML5 Canvas 点击添加 2D 3D 机柜模型
今天又返回好好地消化了一下我们的数据容器 DataModel,这里给新手做一个典型的数据模型事件处理的例子作为参考.这个例子看起来很简单,实际上结合了数据模型中非常重要的三个事件处理的部分:属性变化事 ...
随机推荐
- Winform 使用WebView2 开发现代应用
使用 WebView2 开发现代应用 WebView2 是 Microsoft 提供的一种嵌入式浏览器控件,基于 Edge (Chromium) 引擎.它允许开发者将现代 Web 技术(如 HTML. ...
- 【SpringMVC】获取请求参数的方式
SpringMVC获取请求参数的方式 目录 SpringMVC获取请求参数的方式 方式1:ServletAPI 方法2:通过控制器方法的形参获取请求参数 方法3:@RequestParam 方法4:@ ...
- Go设置GOPROXY国内加速
go env -w GOFLAGS=-buildvcs=false 在 Linux 或 macOS 上面 需要运行下面命令(或者,可以把以下命令写到 .bashrc 或 .bash_profile 文 ...
- archlinux 显卡驱动
https://arch.icekylin.online/guide/rookie/graphic-driver.html archlinux 显卡驱动# 接天莲叶无穷碧,映日荷花别样红# 近年来,a ...
- 视频监控推流助手/极低延迟/支持N路批量多线程推流/264和265推流/监控转网页
一.前言说明 搞视频监控开发除了基本的拉流以外,还有个需求是推流,需要将拉到的流重新推流到流媒体服务器,让流媒体服务做转发和负载均衡,这样其他地方只需要问流媒体服务器要视频流即可.为什么拉了又重新推呢 ...
- Qt音视频开发03-ffmpeg倍速播放(半倍速/2倍速/4倍速/8倍速)
一.前言 用ffmpeg做倍速播放,是好多年都一直没有实现的功能,有个做法是根据倍速参数,不断切换播放位置,实现效果不是很好,ffplay中的倍速就做得很好,而且声音无论倍速多少还非常柔和,有特别的降 ...
- Qt开发经验小技巧196-200
关于Qt延时的几种方法. void QUIHelperCore::sleep(int msec) { if (msec <= 0) { return; } #if 1 //非阻塞方式延时,现在很 ...
- 【吐血经验】在 windows 上安装 spark 遇到的一些坑 | 避坑指南
在 windows 上安装 spark 遇到的一些坑 | 避坑指南 最近有个活:给了我一个阿里云桌面(windows 10系统),让我在上面用 scala + spark 写一些东西. 总是报错不断, ...
- C Primer Plus 第6版 第六章 编程练习参考答案
编译环境VS Code+WSL GCC 源码请到文末下载 .注意:本章部分题目中用到了math.h 用gcc编译时加上-lm参数. /*第1题*************************/ #i ...
- Linux防火墙端口设置策略
# 当我们在服务器上部署好我们的环境后,一定要检查一下防火墙的端口策略:否则客户端无法连接.# 查看防火墙状态 systemctl status firewalld # 查看防火墙设已开放的端口 # ...